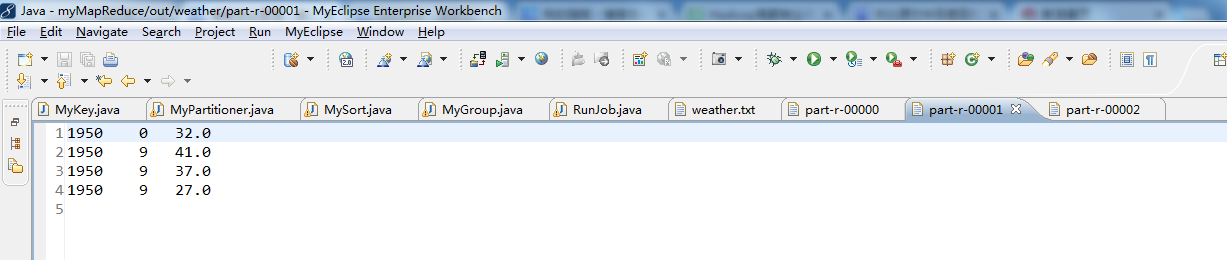
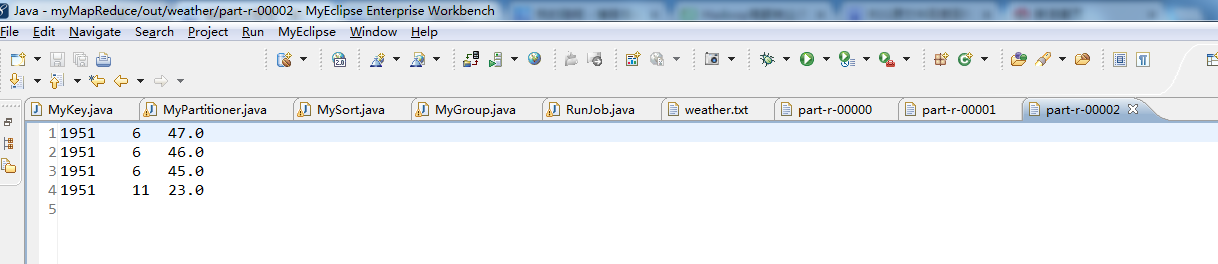
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
代码
![复制代码]()
package zhouls.bigdata.myMapReduce.weather;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
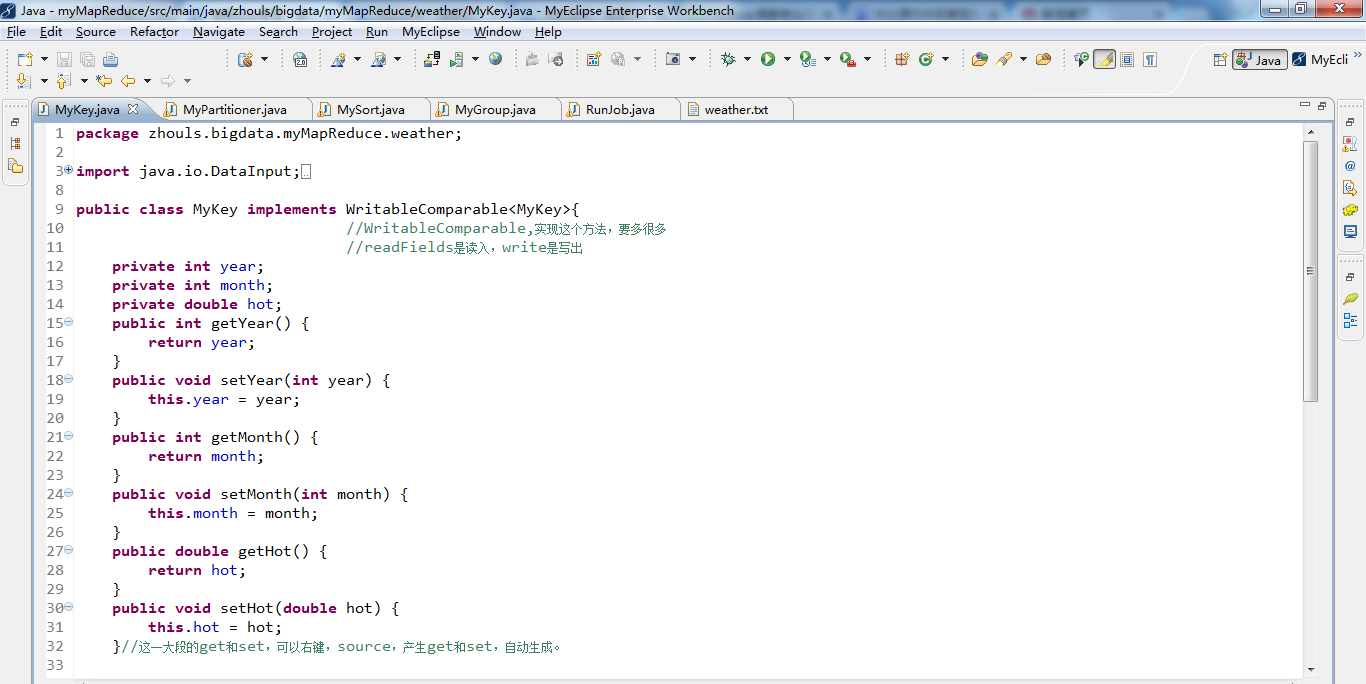
public class MyKey implements WritableComparable<MyKey>{
//WritableComparable,实现这个方法,要多很多
//readFields是读入,write是写出
private int year;
private int month;
private double hot;
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public double getHot() {
return hot;
}
public void setHot(double hot) {
this.hot = hot;
}//这一大段的get和set,可以右键,source,产生get和set,自动生成。
public void readFields(DataInput arg0) throws IOException { //反序列化
this.year=arg0.readInt();
this.month=arg0.readInt();
this.hot=arg0.readDouble();
}
public void write(DataOutput arg0) throws IOException { //序列化
arg0.writeInt(year);
arg0.writeInt(month);
arg0.writeDouble(hot);
}
//判断对象是否是同一个对象,当该对象作为输出的key
public int compareTo(MyKey o) {
int r1 =Integer.compare(this.year, o.getYear());//比较当前的年和你传过来的年
if(r1==0){
int r2 =Integer.compare(this.month, o.getMonth());
if(r2==0){
return Double.compare(this.hot, o.getHot());
}else{
return r2;
}
}else{
return r1;
}
}
}
![复制代码]()
package zhouls.bigdata.myMapReduce.weather;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class MyPartitioner extends HashPartitioner<MyKey, DoubleWritable>{//这里就是洗牌
//执行时间越短越好
public int getPartition(MyKey key, DoubleWritable value, int numReduceTasks) {
return (key.getYear()-1949)%numReduceTasks;//对于一个数据集,找到最小,1949
}
}
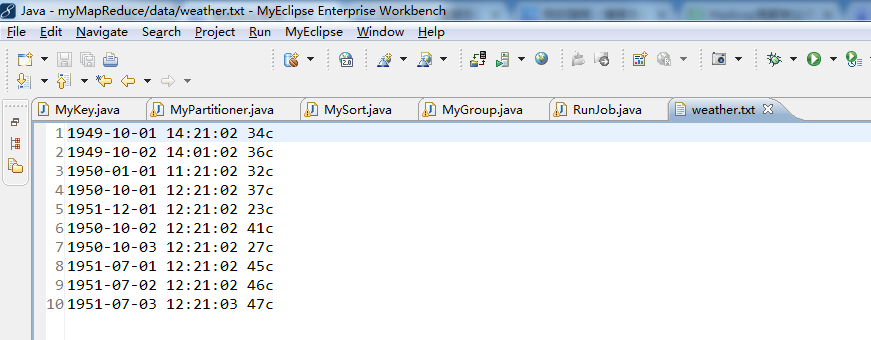
//1949-10-01 14:21:02 34c
//1949-10-02 14:01:02 36c
//1950-01-01 11:21:02 32c
//1950-10-01 12:21:02 37c
//1951-12-01 12:21:02 23c
//1950-10-02 12:21:02 41c
//1950-10-03 12:21:02 27c
//1951-07-01 12:21:02 45c
//1951-07-02 12:21:02 46c
//1951-07-03 12:21:03 47c
package zhouls.bigdata.myMapReduce.weather;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
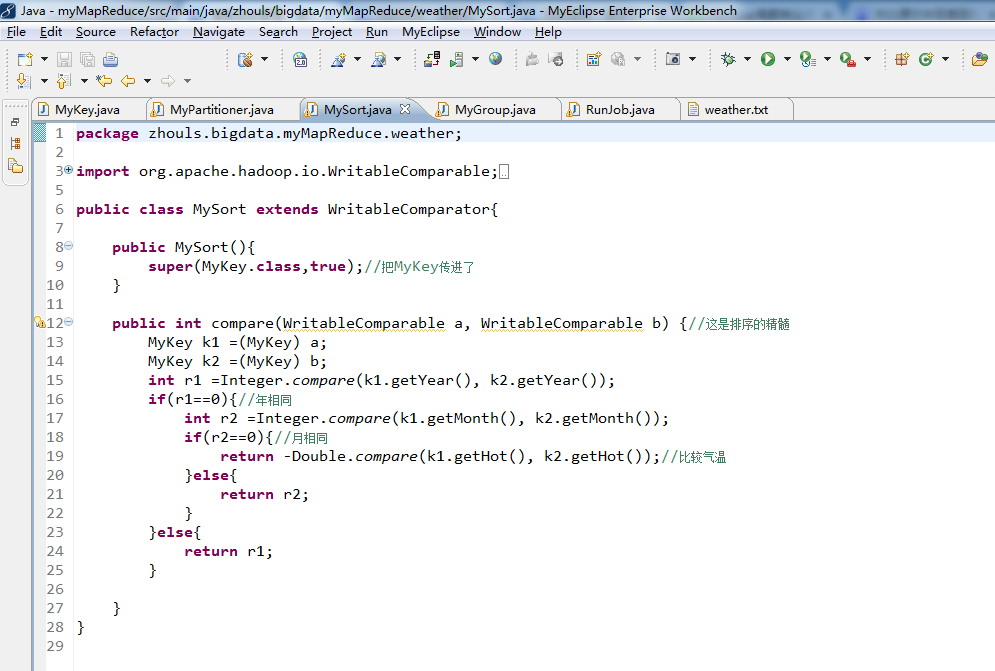
public class MySort extends WritableComparator{
public MySort(){
super(MyKey.class,true);//把MyKey传进了
}
public int compare(WritableComparable a, WritableComparable b) {//这是排序的精髓
MyKey k1 =(MyKey) a;
MyKey k2 =(MyKey) b;
int r1 =Integer.compare(k1.getYear(), k2.getYear());
if(r1==0){//年相同
int r2 =Integer.compare(k1.getMonth(), k2.getMonth());
if(r2==0){//月相同
return -Double.compare(k1.getHot(), k2.getHot());//比较气温
}else{
return r2;
}
}else{
return r1;
}
}
}
package zhouls.bigdata.myMapReduce.weather;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
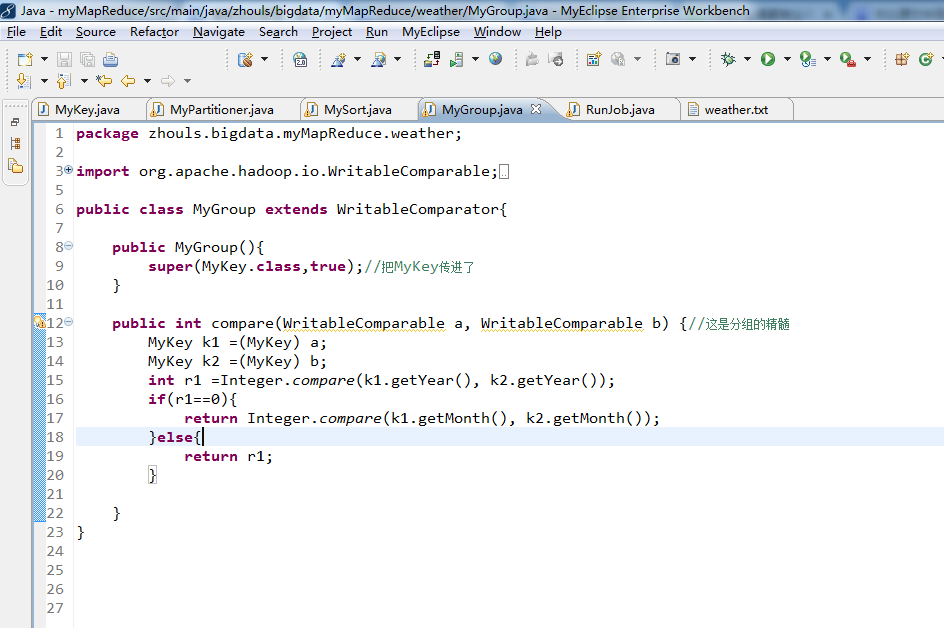
public class MyGroup extends WritableComparator{
public MyGroup(){
super(MyKey.class,true);//把MyKey传进了
}
public int compare(WritableComparable a, WritableComparable b) {//这是分组的精髓
MyKey k1 =(MyKey) a;
MyKey k2 =(MyKey) b;
int r1 =Integer.compare(k1.getYear(), k2.getYear());
if(r1==0){
return Integer.compare(k1.getMonth(), k2.getMonth());
}else{
return r1;
}
}
}
![复制代码]()
package zhouls.bigdata.myMapReduce.weather;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
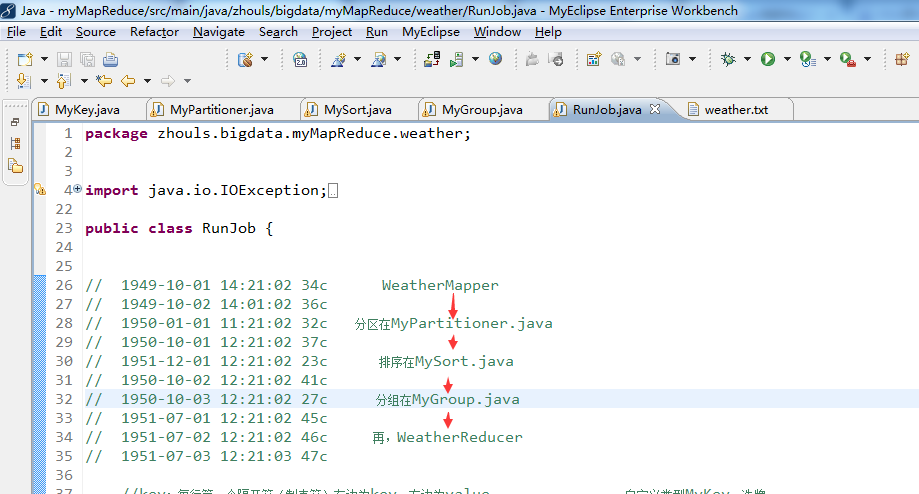
public class RunJob {
// 1949-10-01 14:21:02 34c WeatherMapper
// 1949-10-02 14:01:02 36c
// 1950-01-01 11:21:02 32c 分区在MyPartitioner.java
// 1950-10-01 12:21:02 37c
// 1951-12-01 12:21:02 23c 排序在MySort.java
// 1950-10-02 12:21:02 41c
// 1950-10-03 12:21:02 27c 分组在MyGroup.java
// 1951-07-01 12:21:02 45c
// 1951-07-02 12:21:02 46c 再,WeatherReducer
// 1951-07-03 12:21:03 47c
//key:每行第一个隔开符(制表符)左边为key,右边为value 自定义类型MyKey,洗牌,
static class WeatherMapper extends Mapper<Text, Text, MyKey, DoubleWritable>{
SimpleDateFormat sdf =new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
NullWritable v =NullWritable.get();
// 1949-10-01 14:21:02是自定义类型MyKey,即key
// 34c是DoubleWritable,即value
protected void map(Text key, Text value,Context context) throws IOException, InterruptedException {
try {
Date date =sdf.parse(key.toString());
Calendar c =Calendar.getInstance();
//Calendar 类是一个抽象类,可以通过调用 getInstance() 静态方法获取一个 Calendar 对象,
//此对象已由当前日期时间初始化,即默认代表当前时间,如 Calendar c = Calendar.getInstance();
c.setTime(date);
int year =c.get(Calendar.YEAR);
int month =c.get(Calendar.MONTH);
double hot =Double.parseDouble(value.toString().substring(0, value.toString().lastIndexOf("c")));
MyKey k =new MyKey();
k.setYear(year);
k.setMonth(month);
k.setHot(hot);
context.write(k, new DoubleWritable(hot));
} catch (Exception e) {
e.printStackTrace();
}
}
}
static class WeatherReducer extends Reducer<MyKey, DoubleWritable, Text, NullWritable>{
protected void reduce(MyKey arg0, Iterable<DoubleWritable> arg1,Context arg2)throws IOException, InterruptedException {
int i=0;
for(DoubleWritable v :arg1){
i++;
String msg =arg0.getYear()+"\t"+arg0.getMonth()+"\t"+v.get();//"\t"是制表符
arg2.write(new Text(msg), NullWritable.get());
if(i==3){
break;
}
}
}
}
public static void main(String[] args) {
Configuration config =new Configuration();
// config.set("fs.defaultFS", "hdfs://HadoopMaster:9000");
// config.set("yarn.resourcemanager.hostname", "HadoopMaster");
// config.set("mapred.jar", "C:\\Users\\Administrator\\Desktop\\wc.jar");
// config.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ",");//默认分隔符是制表符"\t",这里自定义,如","
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJarByClass(RunJob.class);
job.setJobName("weather");
job.setMapperClass(WeatherMapper.class);
job.setReducerClass(WeatherReducer.class);
job.setMapOutputKeyClass(MyKey.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setPartitionerClass(MyPartitioner.class);
job.setSortComparatorClass(MySort.class);
job.setGroupingComparatorClass(MyGroup.class);
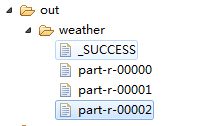
job.setNumReduceTasks(3);
job.setInputFormatClass(KeyValueTextInputFormat.class);
// FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/weather.txt"));//输入路径,下有weather.txt
//
// Path outpath =new Path("hdfs://HadoopMaster:9000/out/weather");
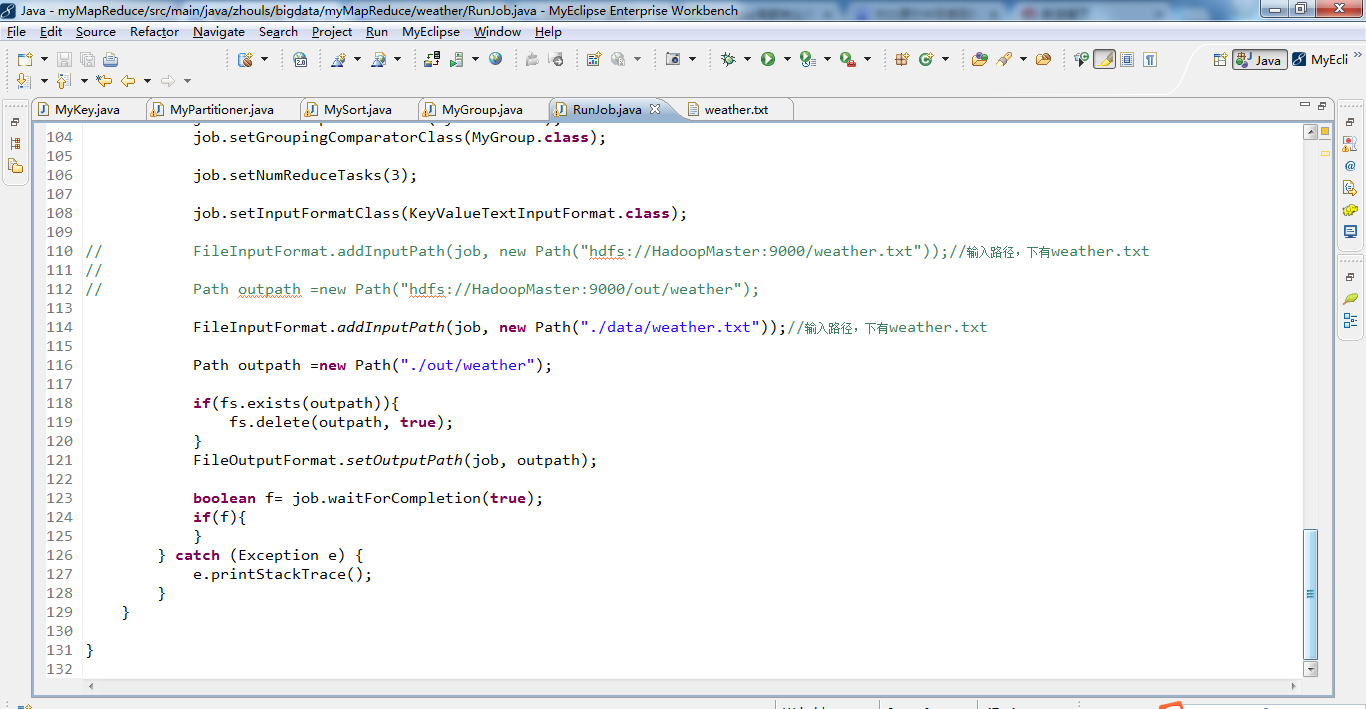
FileInputFormat.addInputPath(job, new Path("./data/weather.txt"));//输入路径,下有weather.txt
Path outpath =new Path("./out/weather");
if(fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f= job.waitForCompletion(true);
if(f){
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
![复制代码]()
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6164729.html,如需转载请自行联系原作者