Elasticsearch之head插件安装之后的浏览详解
比如,我的这里是http://192.168.80.200:9200/_plugin/head/ 1、概览 2、索引 3、数据浏览 4、基本查询 5、复合查询 6、更多详情,随着深入,再贴写分享! 总结: 对于ES而言,安装其他插件的方法,跟此类似! 本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6424134.html,如需转载请自行联系原作者
首先,明确一个概念,es包括全部更新和局部更新!
ES全部更新
ES可以使用PUT或者POST对文档进行更新(全部更新),如果指定ID的文档已经存在,则执行更新操作。
比如,我这里,id=1文档存在,那么,就是es全部更新。
注意:
es执行更新操作的时候,ES首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,但是你也无法访问,
ES会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
ES局部更新
es为什么需要局部更新?
这个,从字面意思就知道,当然,不想全部更新时,比如一个指定类型下,很多个id,我不想每个id都涉及等。
局部更新,可以添加新字段或者更新已有字段(必须使用POST)
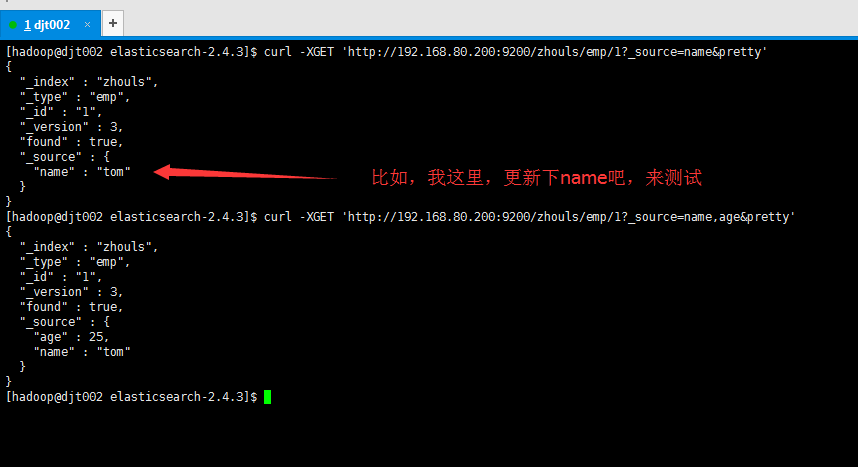
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?_source=name&pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"name" : "tom"
}
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?_source=name,age&pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"age" : 25,
"name" : "tom"
}
}
[hadoop@djt002 elasticsearch-2.4.3]$
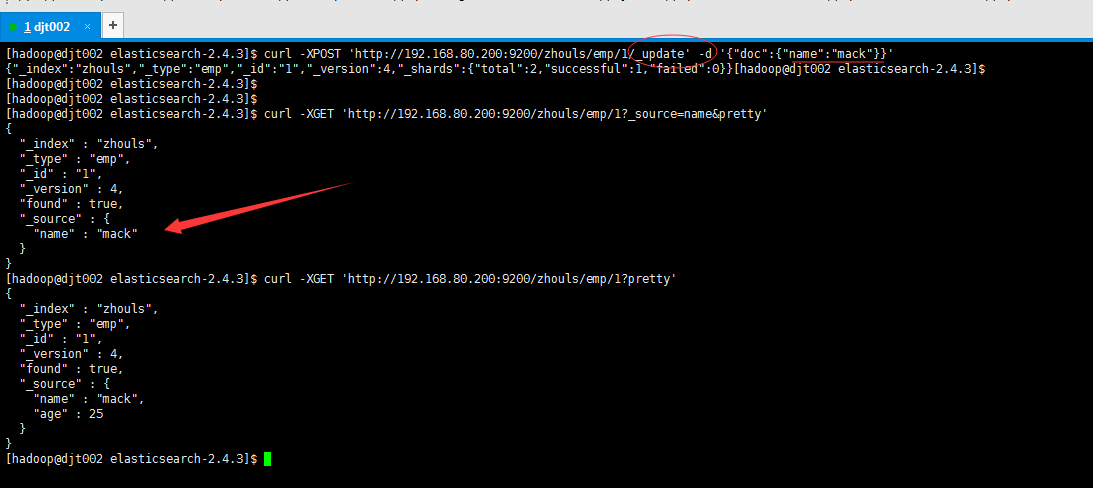
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XPOST 'http://192.168.80.200:9200/zhouls/emp/1/_update' -d '{"doc":{"name":"mack"}}'
{"_index":"zhouls","_type":"emp","_id":"1","_version":4,"_shards":{"total":2,"successful":1,"failed":0}}[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?_source=name&pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_version" : 4,
"found" : true,
"_source" : {
"name" : "mack" 成功更改了name
}
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/1?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"_version" : 4,
"found" : true,
"_source" : {
"name" : "mack",
"age" : 25
}
}
[hadoop@djt002 elasticsearch-2.4.3]$
总结:
ES全部更新,使用PUT或者POST
ES局部更新,使用POST
ES的全部更新和局部更新,底层有什么区别?
答:全部更新,是直接把之前的老数据,标记为删除状态,然后,再添加一条更新的。
局域更新,只是修改某个字段。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6421577.html,如需转载请自行联系原作者

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273