本博文包括:
Scala IDE for Eclipse的下载
Scala IDE for Eclipse的安装
本地模式或集群模式
我们知道,对于开发而言,IDE是有很多个选择的版本。如我们大部分人经常用的是如下。
Eclipse *版本
Eclipse *下载
![]()
而我们知道,对于spark的scala开发啊,有为其专门设计的eclipse,Scala IDE for Eclipse。
![]()
1、Scala IDE for Eclipse的下载
![]()
http://scala-ide.org/
![]()
![]()
2、Scala IDE for Eclipse的安装
进行解压
![]()
![]()
3、Scala IDE for Eclipse的WordCount的初步使用
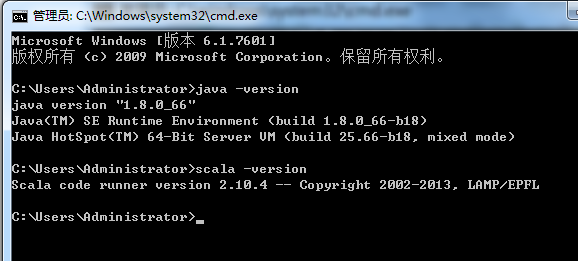
在这之前,先在本地里安装好java和scala
![]()
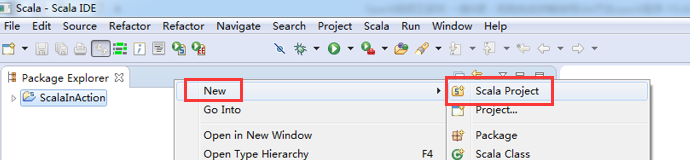
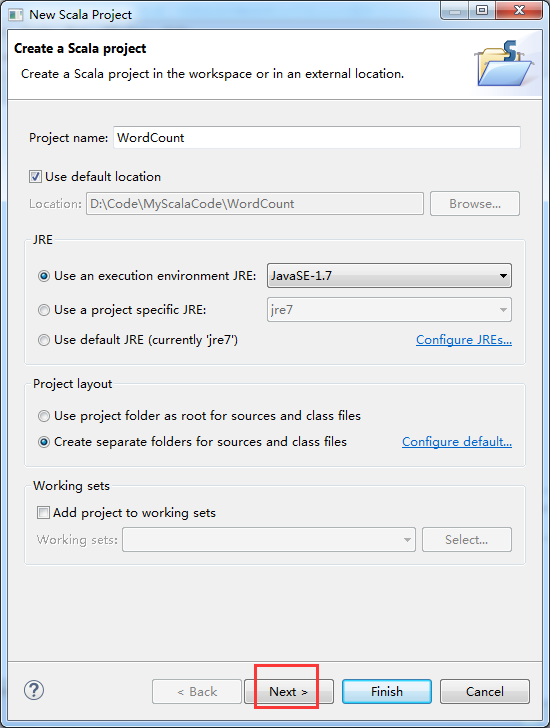
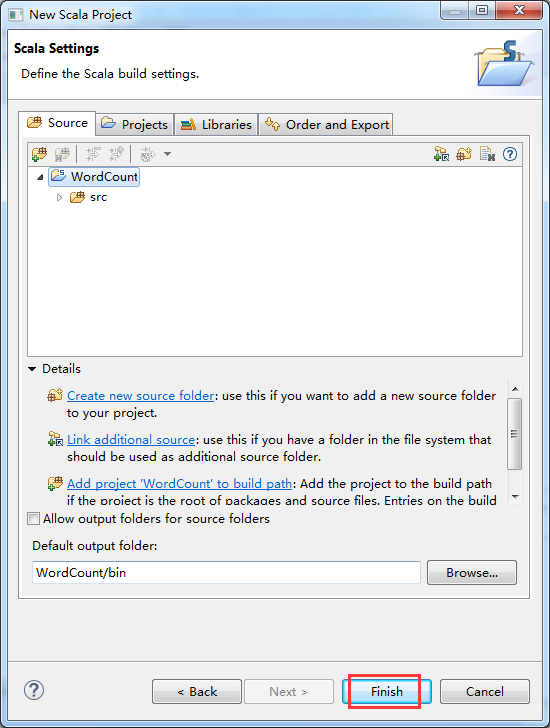
因为,我这篇博客,是面向基础的博友而分享的。所以,在此,是在Scala IDE for Eclipse里,手动新建scala项目。
注意:推荐使用IDEA , 当然有人肯定还依依不舍Scala IDE for Eclipse。
则,如下是我写的另一篇博客
![]()
![]()
![]()
![]()
![]()
默认竟然变成了scala 2.11.8去了
这一定要换!
Scala2.11.8(默认的版本) --------> scala2.10.4(我们的版本)
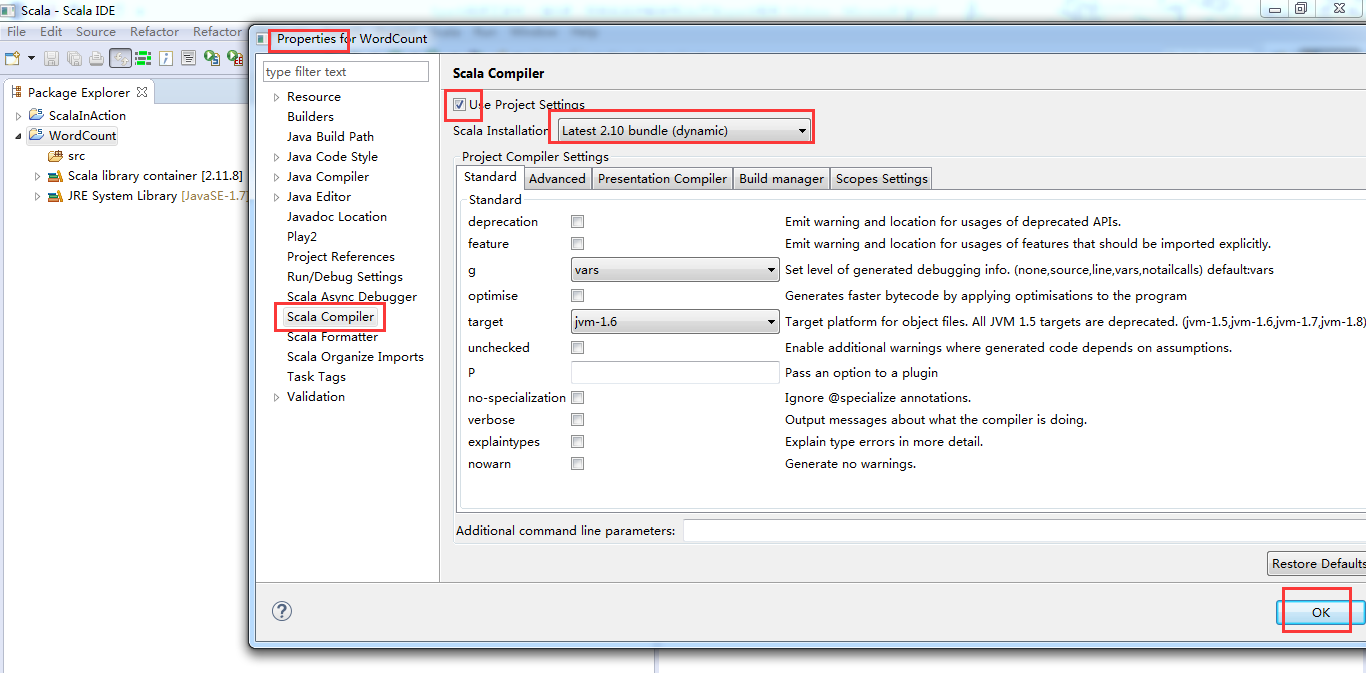
第一步:修改依赖的scala版本,从scala2.11.*,至scala2.10.*。
![]()
![]()
![]()
![]()
这里是兼容版本,没问题。Scala2.10.6和我们的scala2.10.4没关系!!!
第二步:加入spark的jar文件依赖
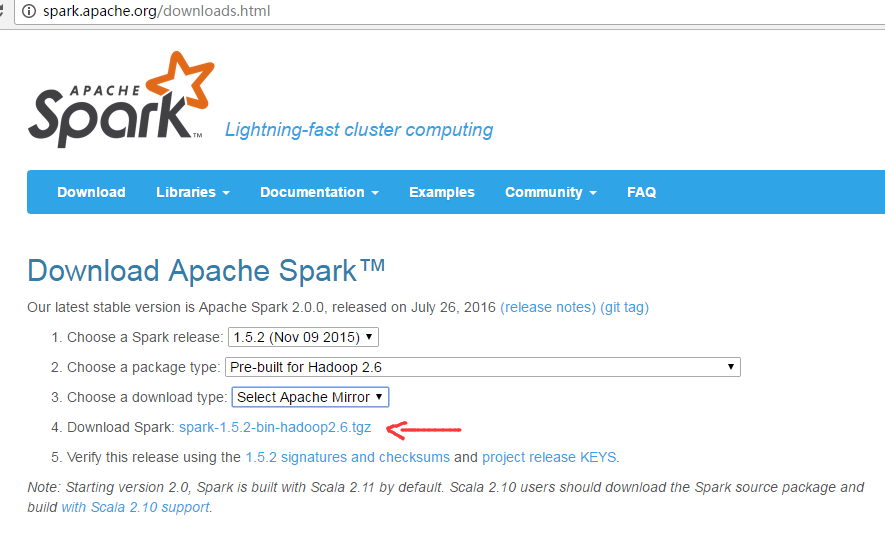
http://spark.apache.org/downloads.html
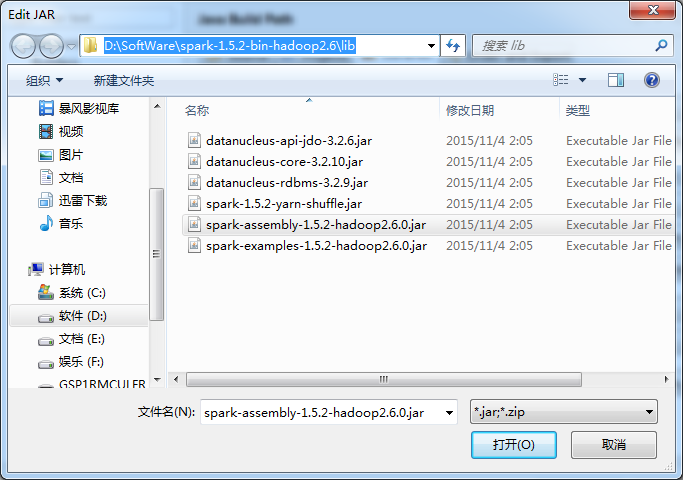
我这里,以spark-1.5.2-bin-hadoop2.6.tgz为例,其他版本都是类似的,很简单!
![]()
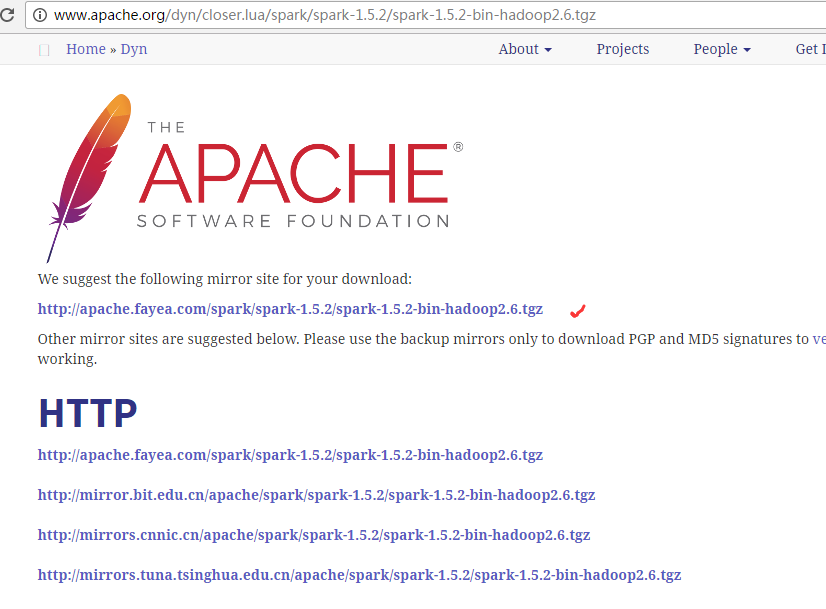
http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz
![]()
![]()
![]()
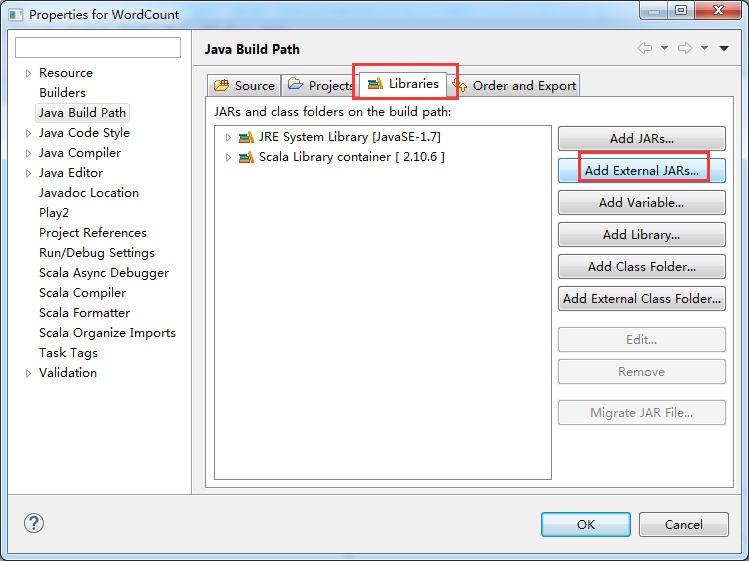
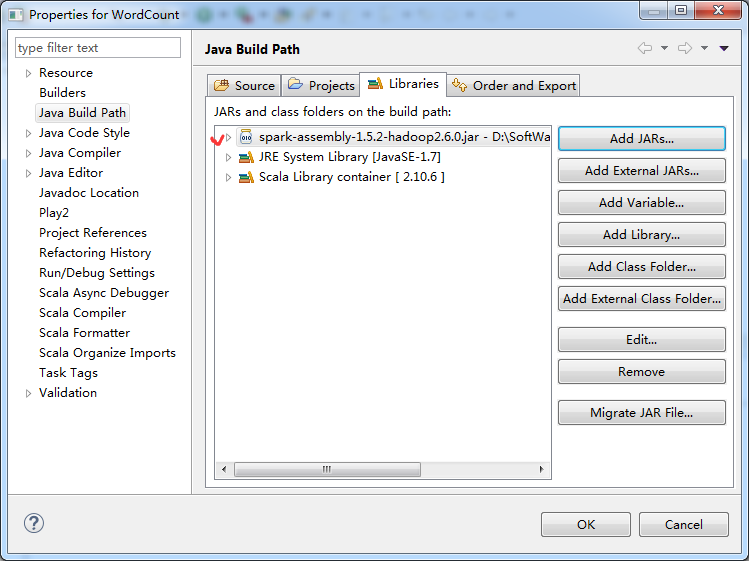
第三步:找到spark依赖的jar文件,并导入到Scala IDE for Eclipse的jar依赖中
![]()
![]()
![]()
![]()
![]()
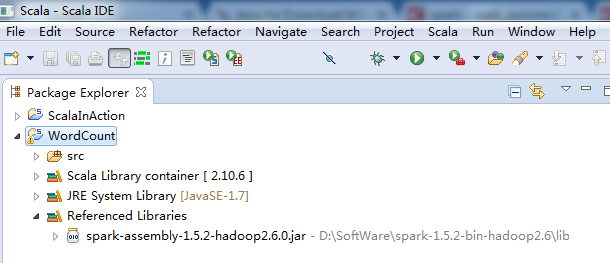
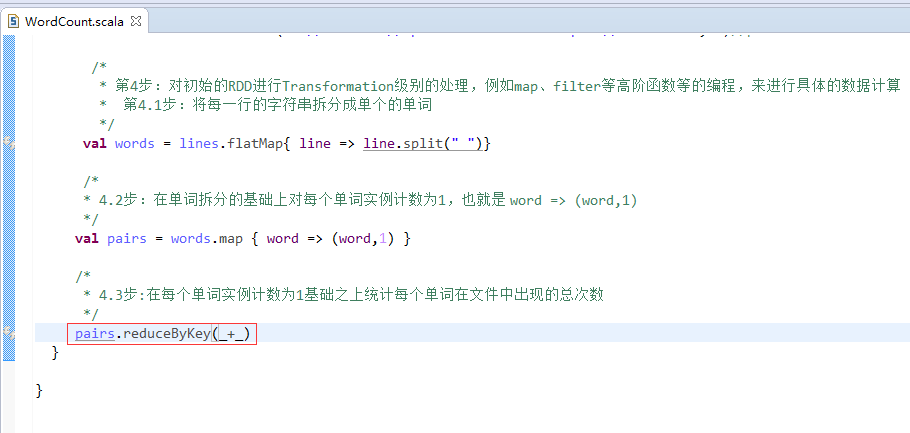
添加Spark的jar依赖spark-1.5.2-bin-hadoop2.6.tgz里的lib目录下的spark-assembly-1.5.2-hadoop2.6.0.jar
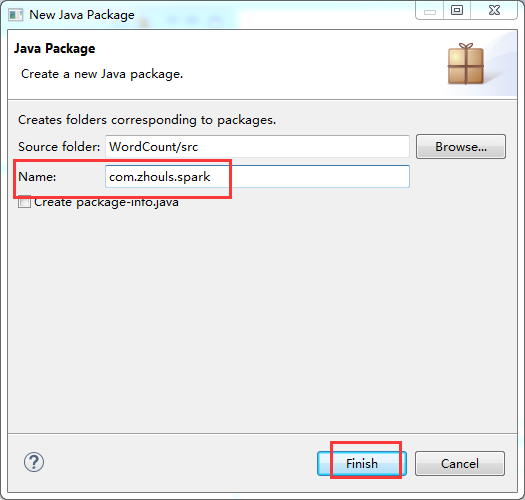
第四步:在src下,建立spark工程包
![]()
![]()
![]()
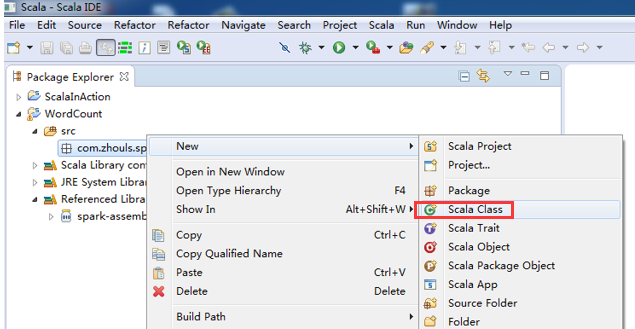
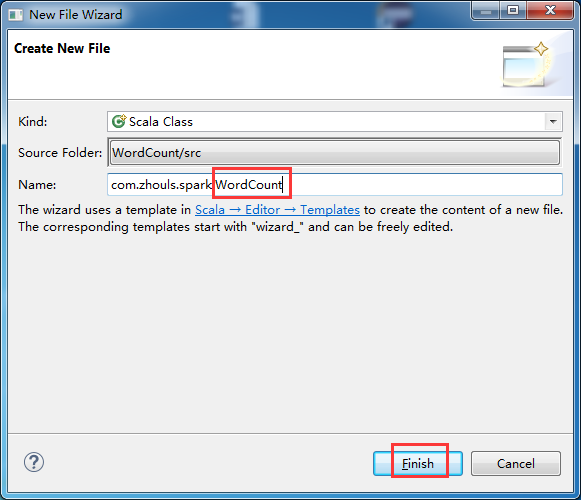
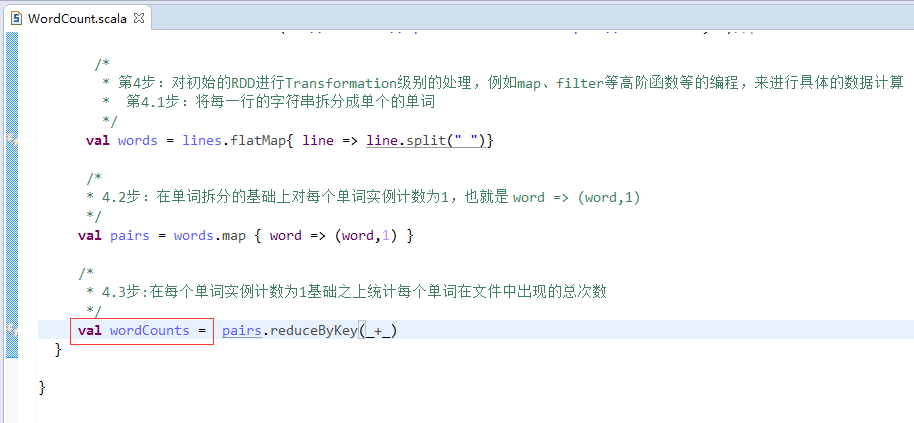
第五步:创建scala入口类
![]()
![]()
![]()
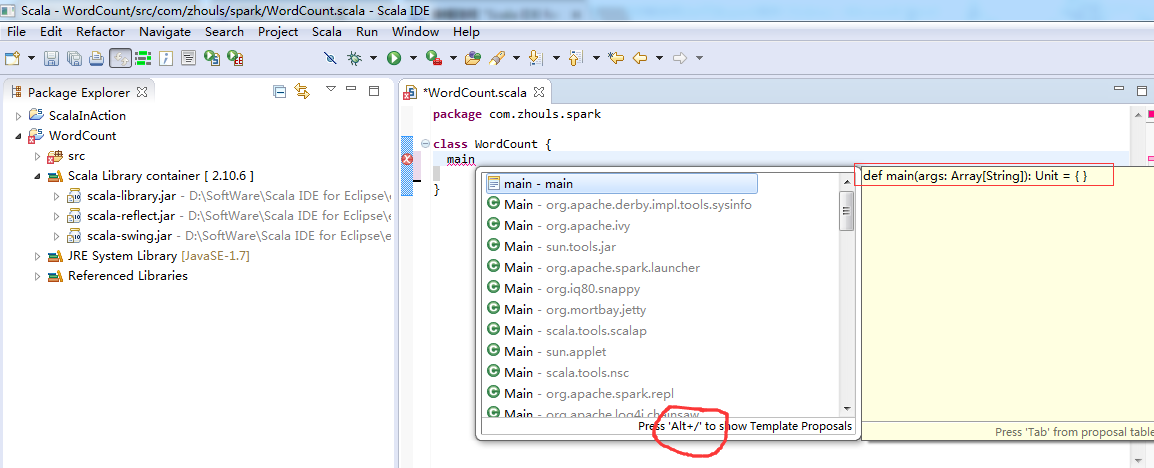
定义main方法
![]()
![]()
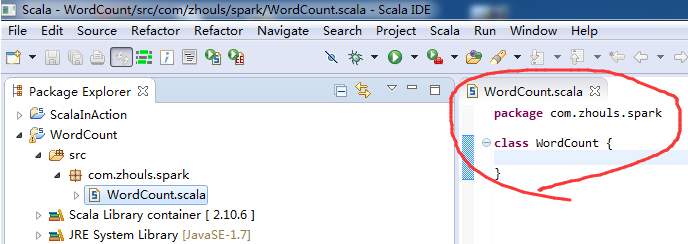
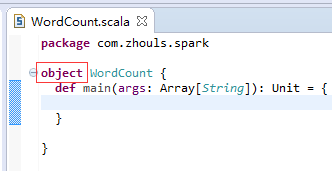
第六步:把class变成object,并编写main入口方法。
![]()
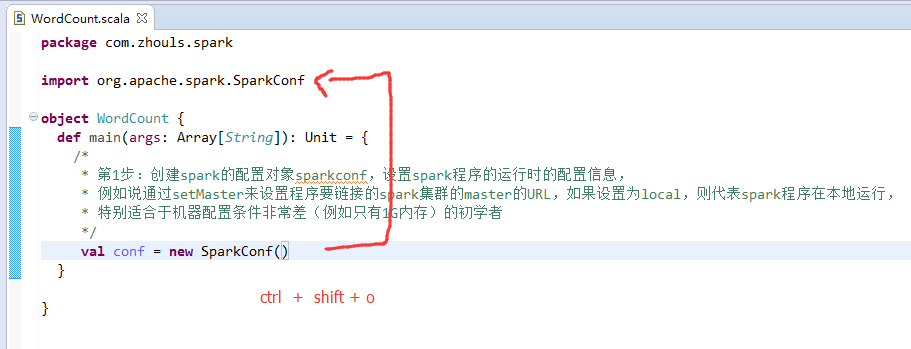
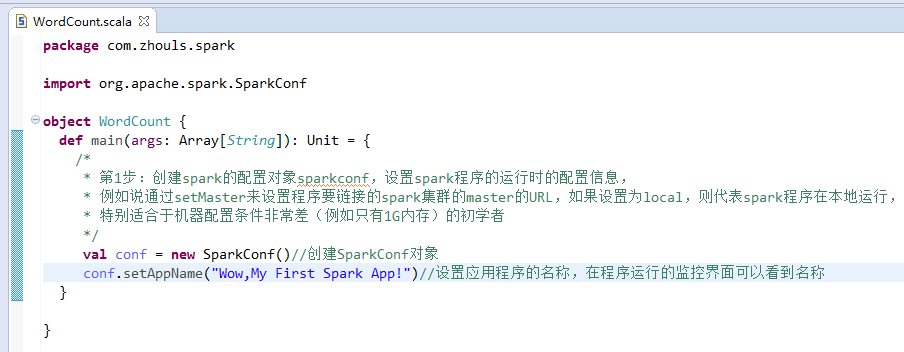
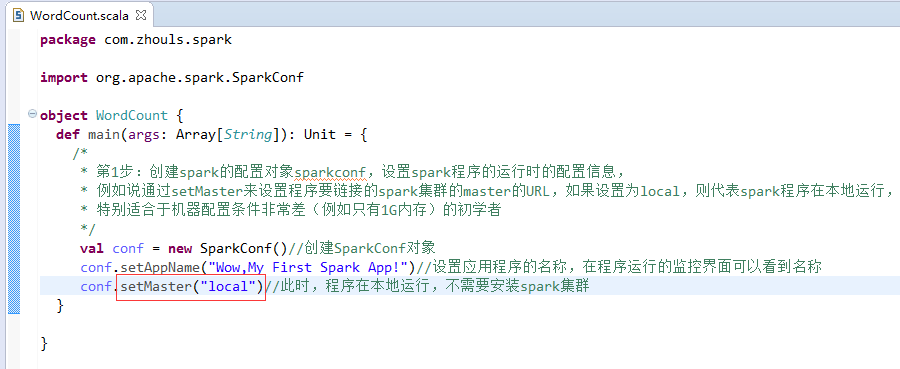
本地模式
第1步
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
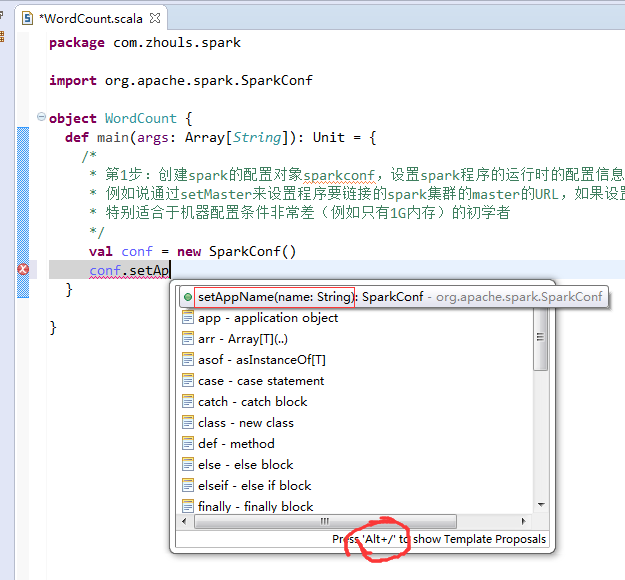
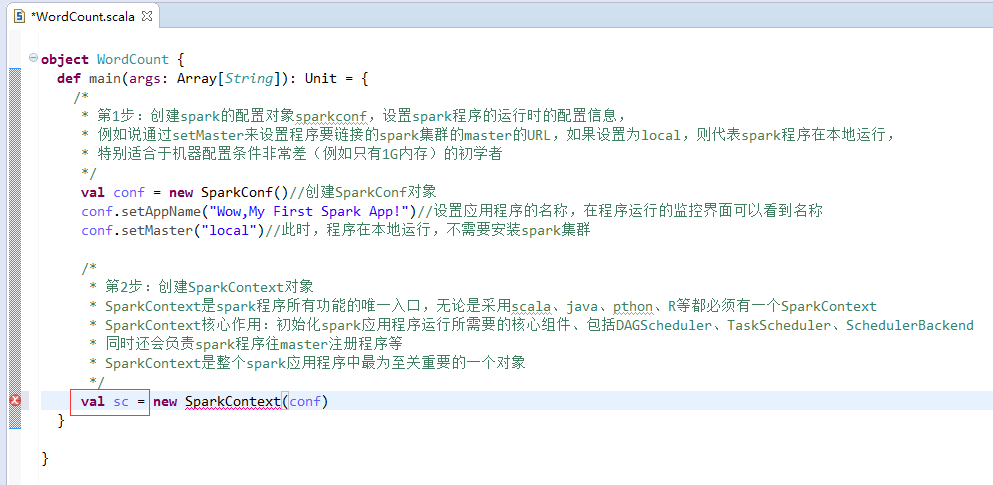
第2步
![]()
![]()
![]()
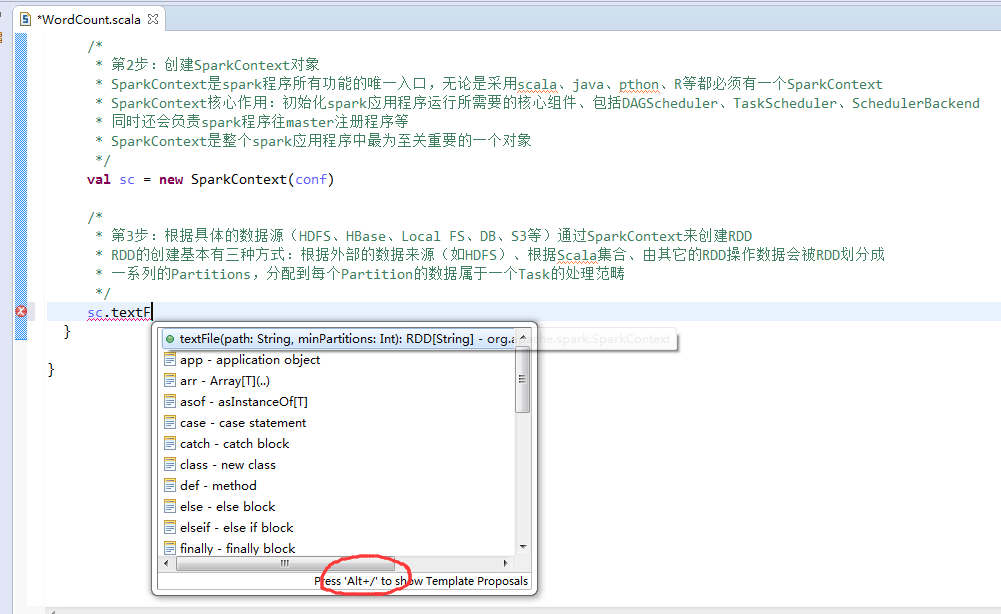
第3步
![]()
![]()
![]()
![]()
![]()
![]()
![]()
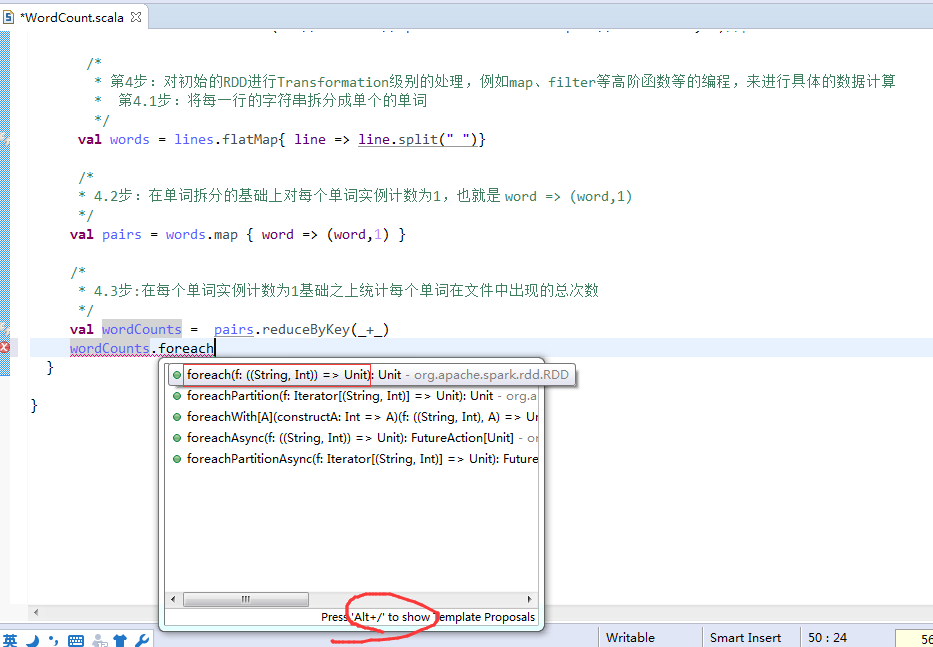
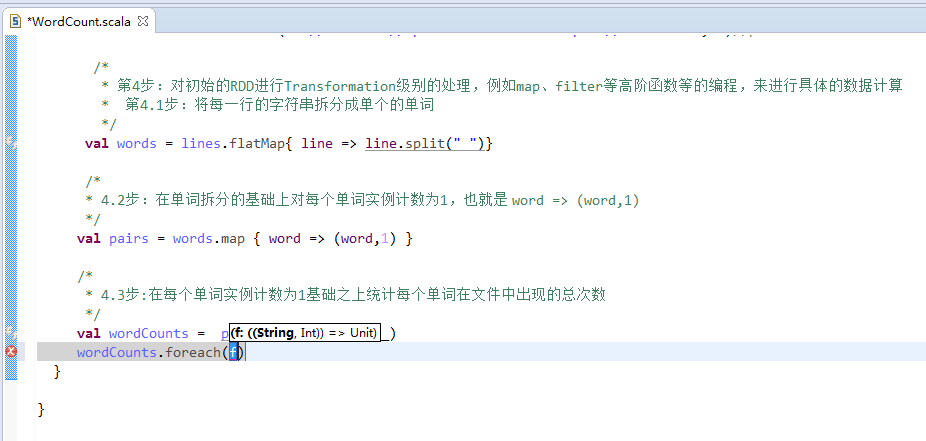
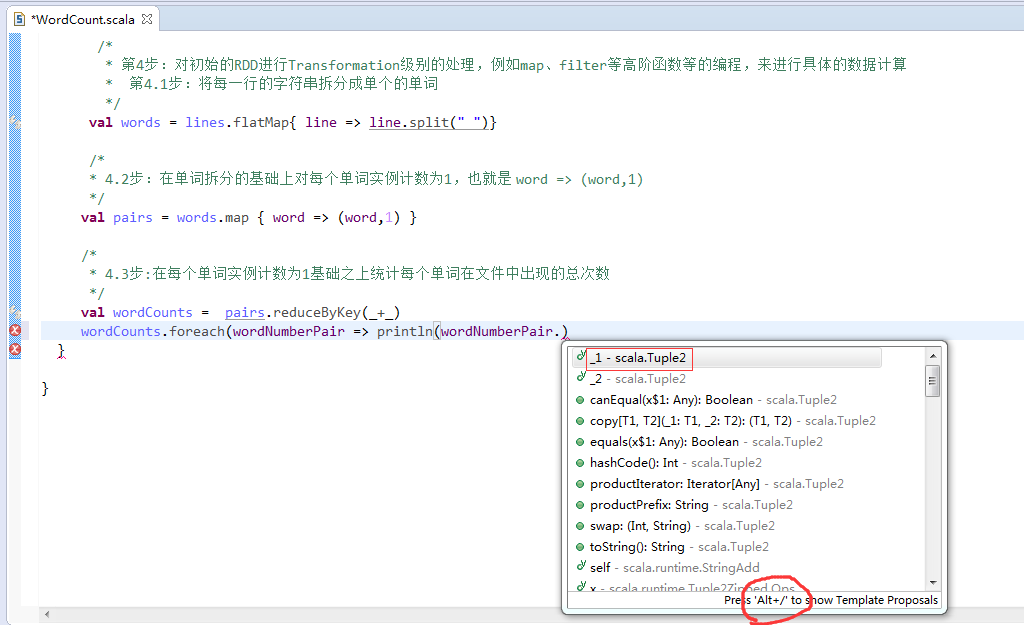
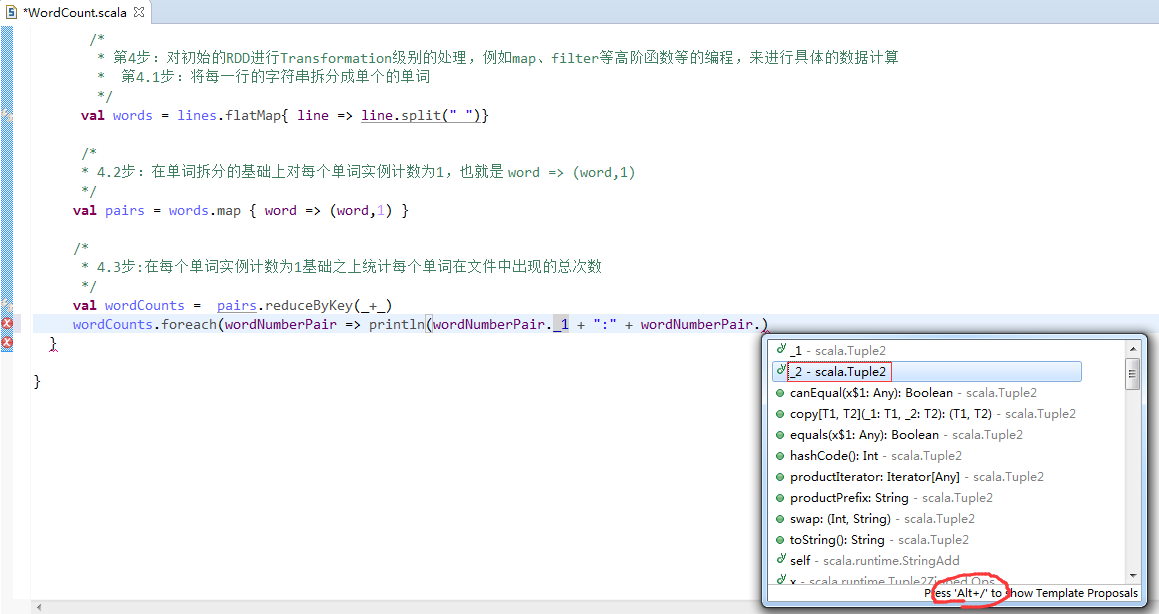
第4步
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
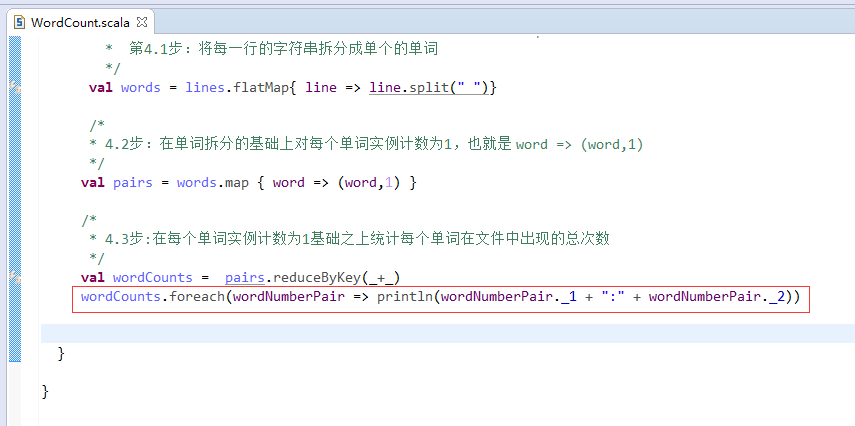
第5步
![]()
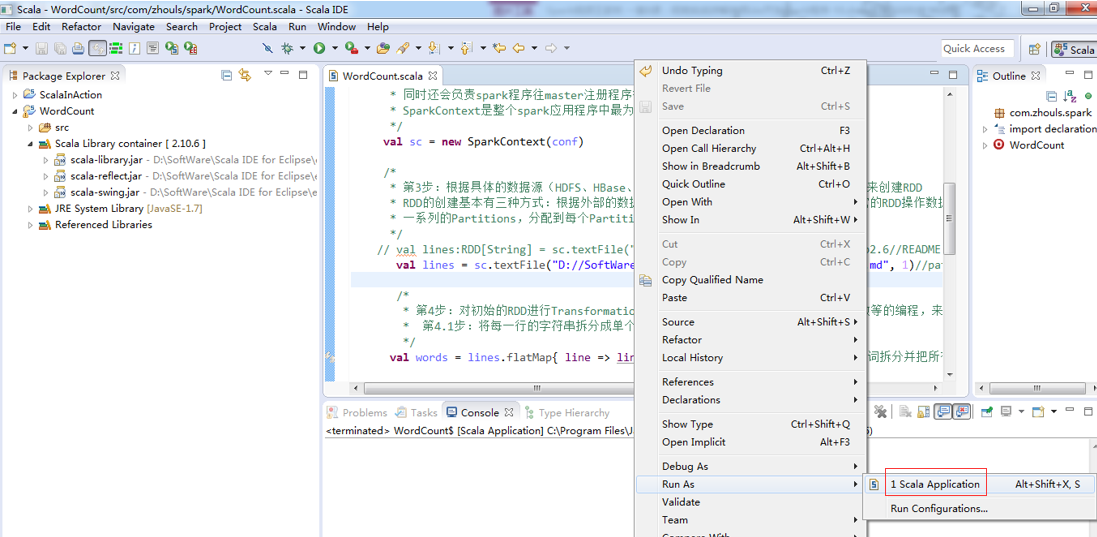
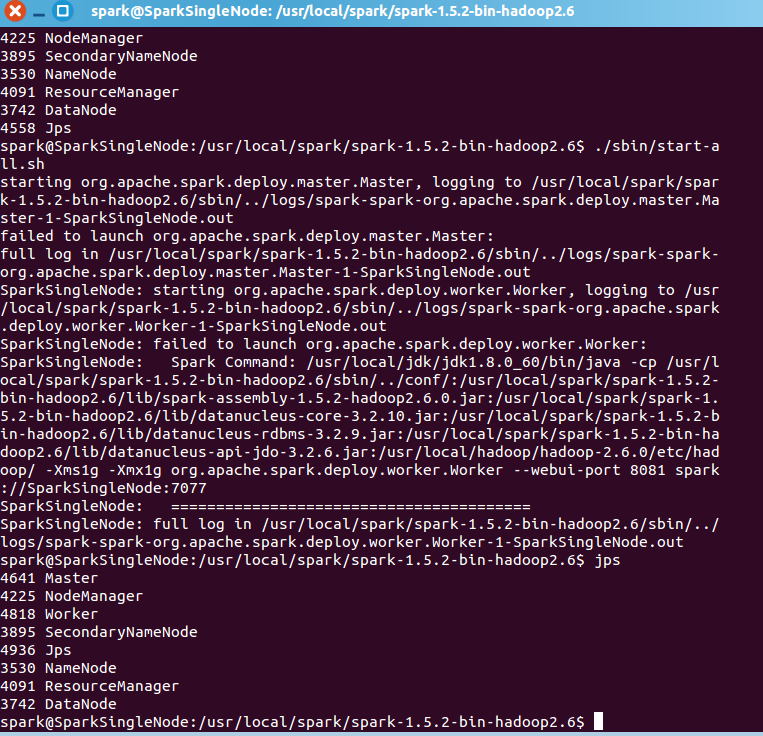
第6步
![]()
![]()
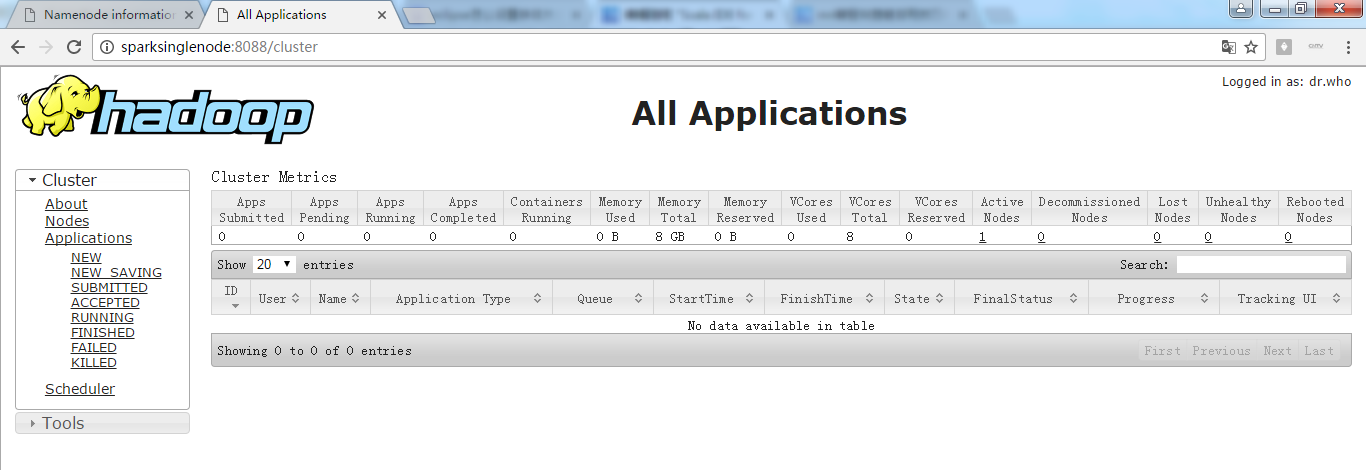
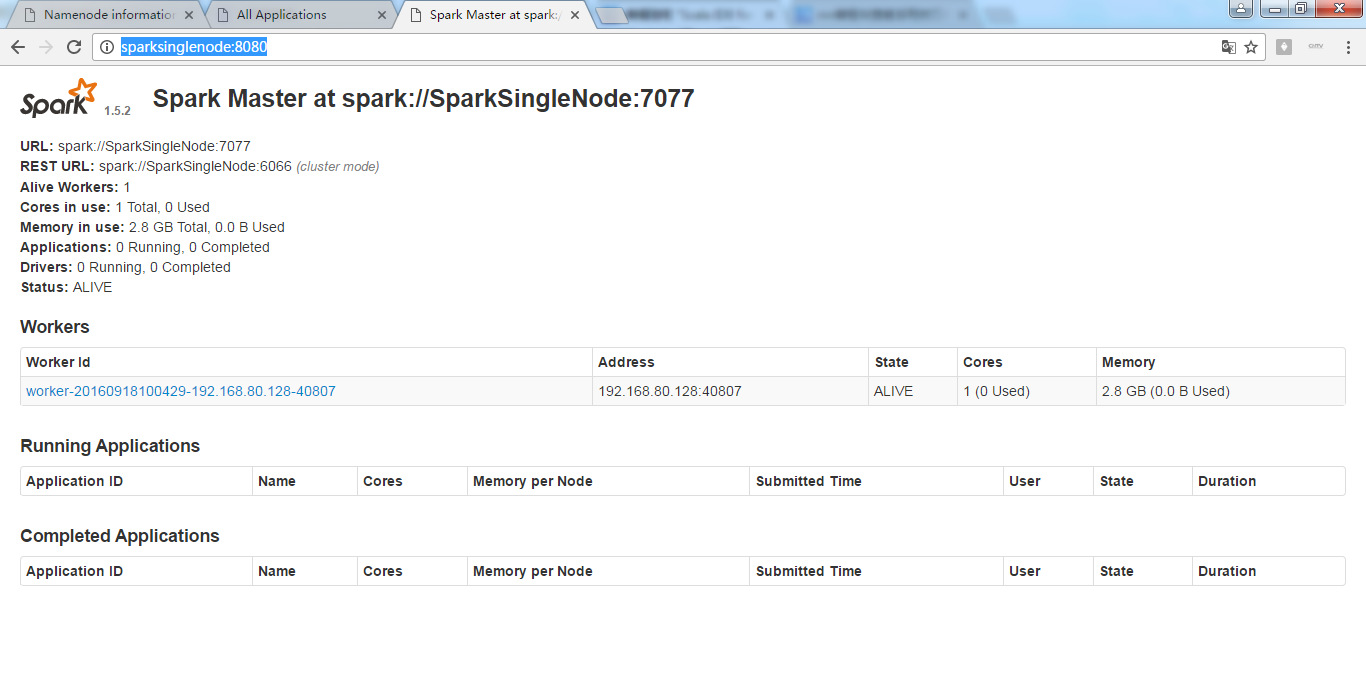
集群模式
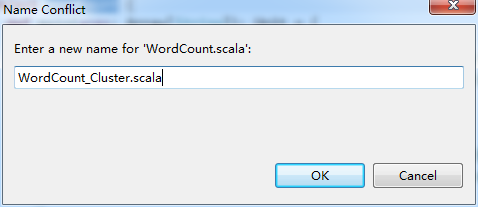
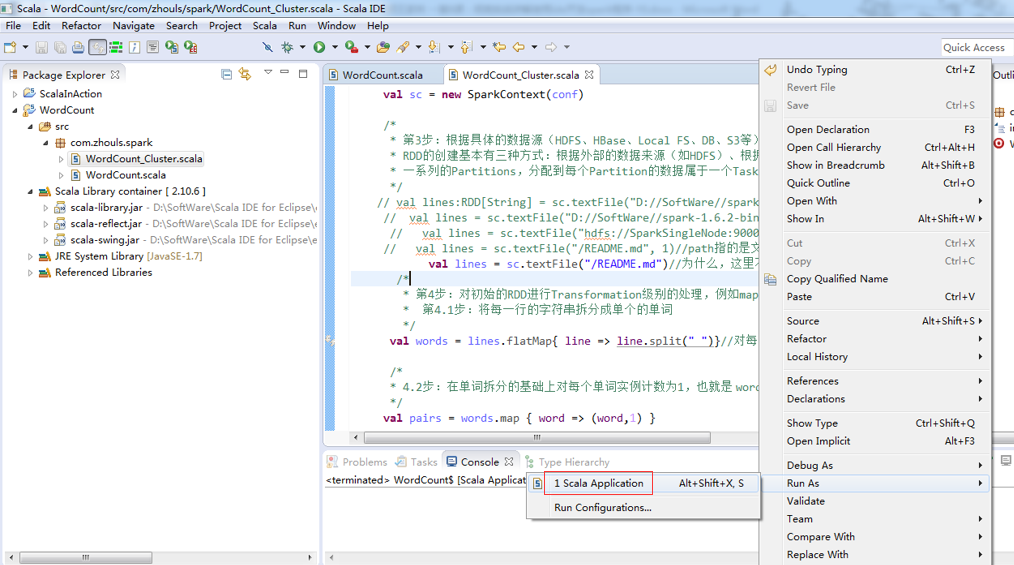
这里,学会巧,复制粘贴,WordCount.scala 为 WordCount_Clutser.scala。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
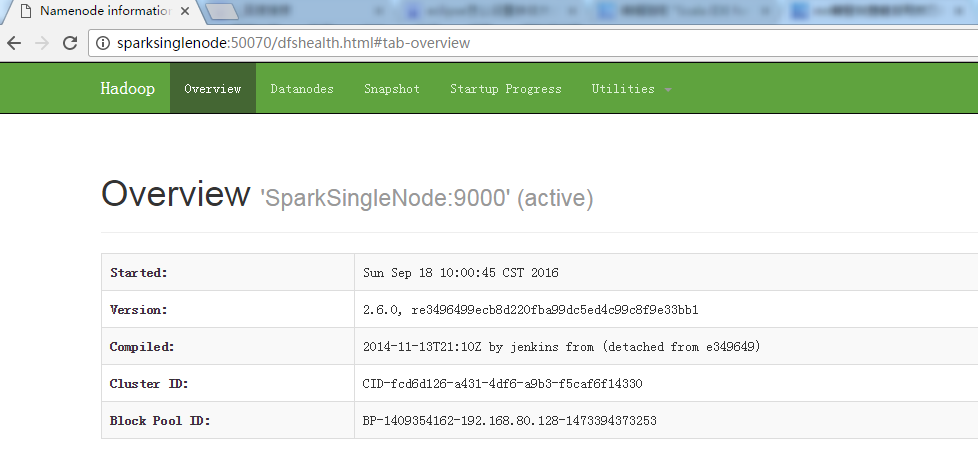
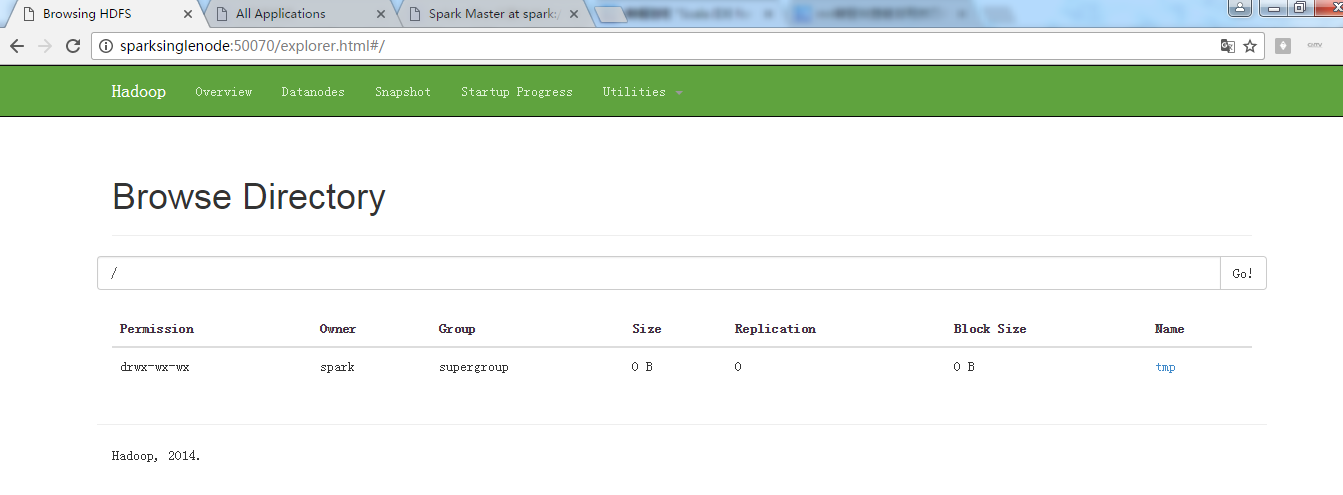
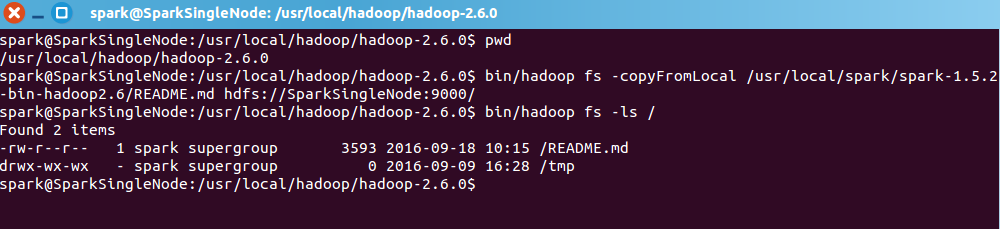
现在呢,来从Linux里,拷贝文件到hadoop集群里
即,将
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/README.md 到 / 或 hdfs://SparkSingleNode:9000
![]()
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ pwd
/usr/local/hadoop/hadoop-2.6.0
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ bin/hadoop fs -copyFromLocal /usr/local/spark/spark-1.5.2-bin-hadoop2.6/README.md hdfs://SparkSingleNode:9000/
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ bin/hadoop fs -ls /
Found 2 items
-rw-r--r-- 1 spark supergroup 3593 2016-09-18 10:15 /README.md
drwx-wx-wx - spark supergroup 0 2016-09-09 16:28 /tmp
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$
![]()
![]()
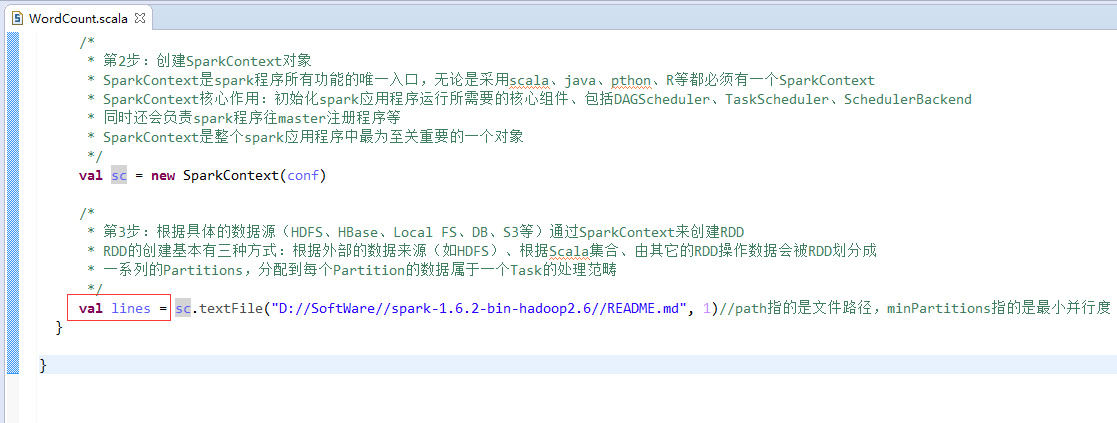
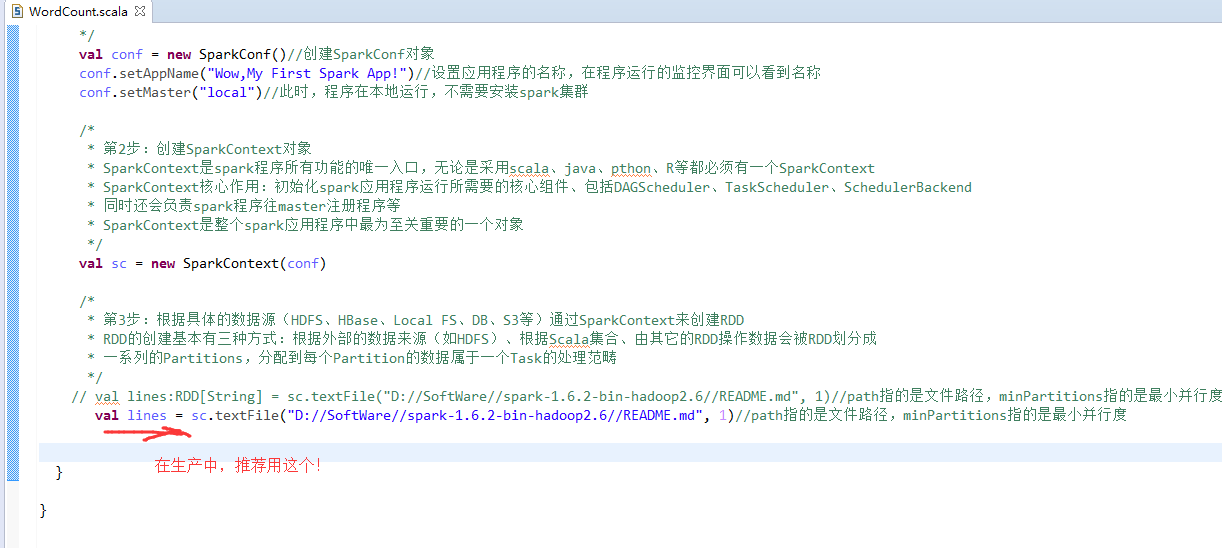
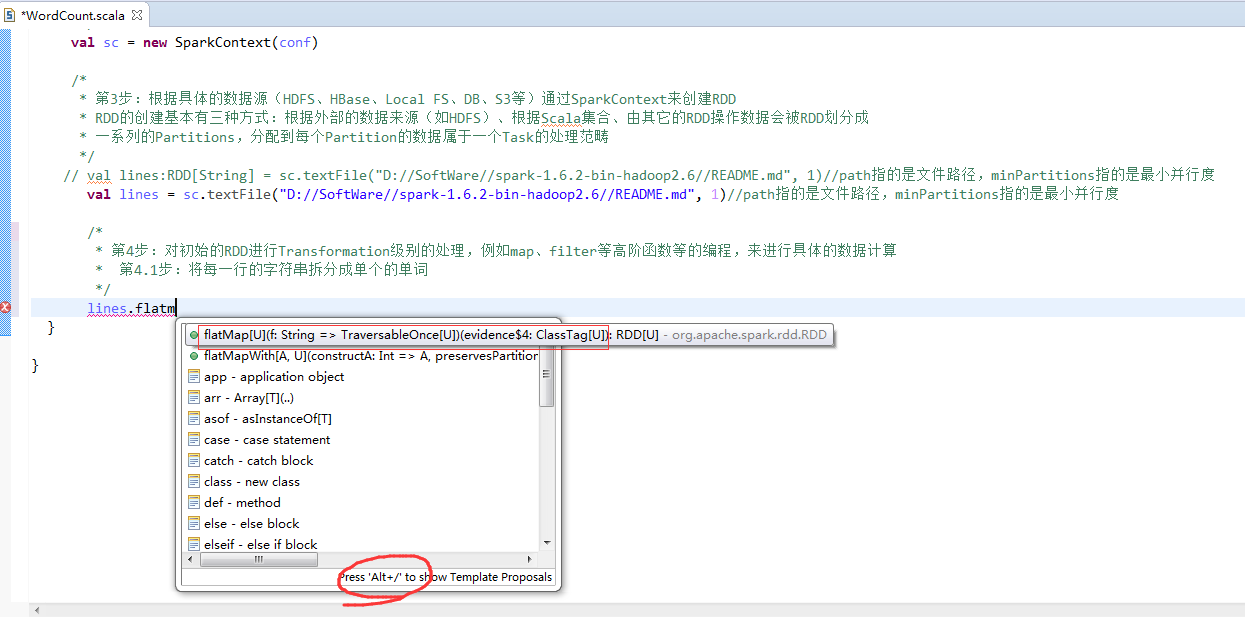
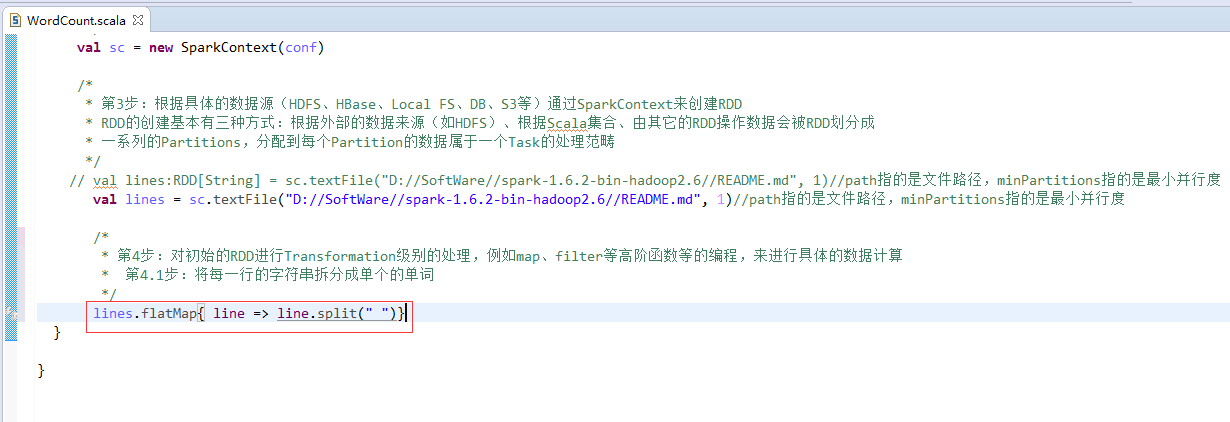
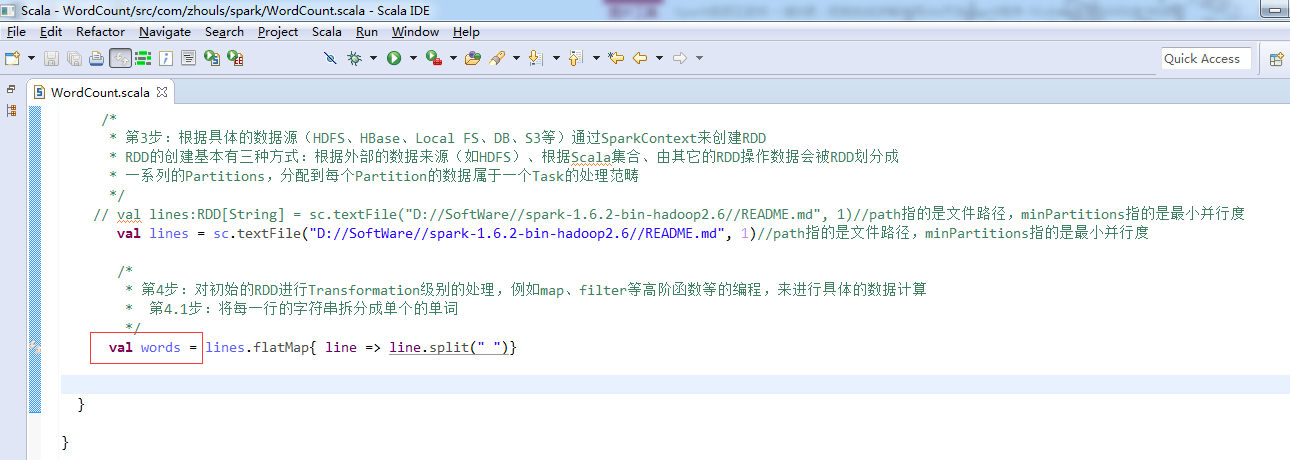
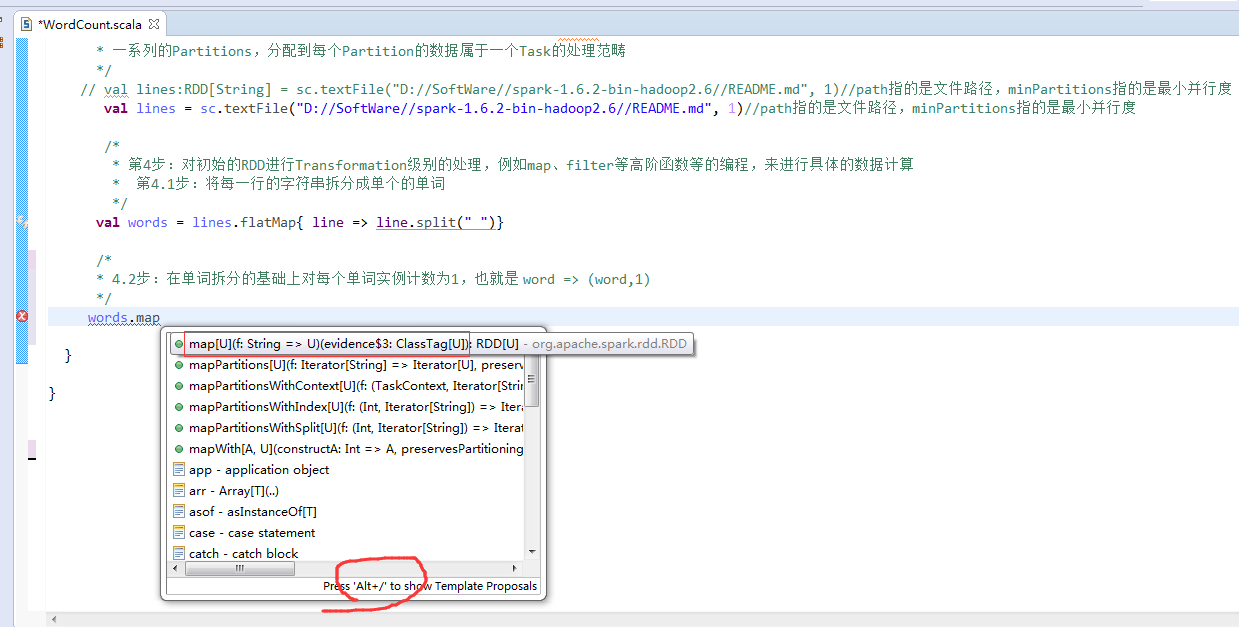
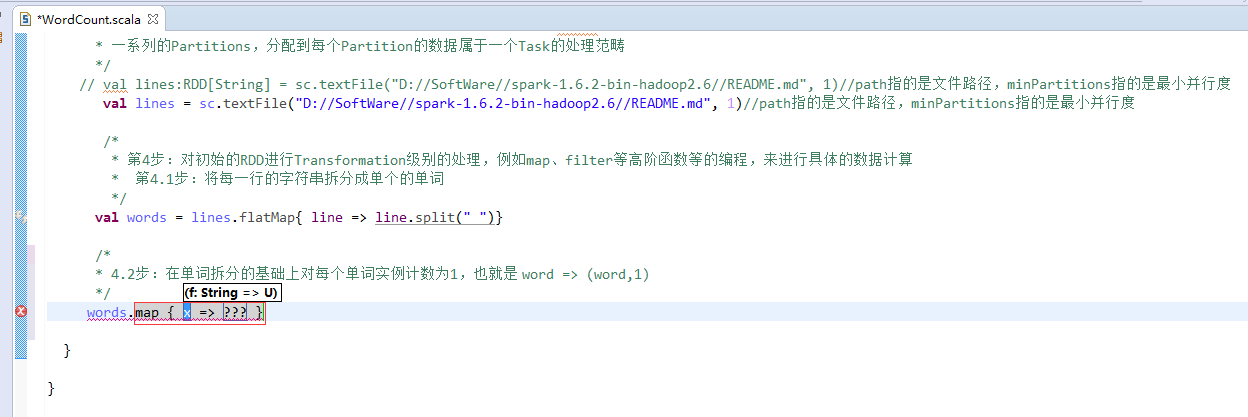
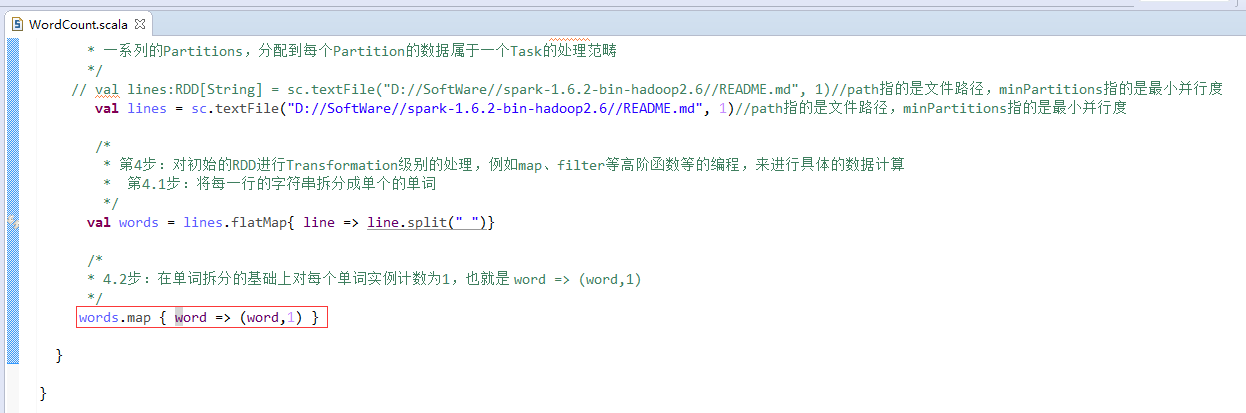
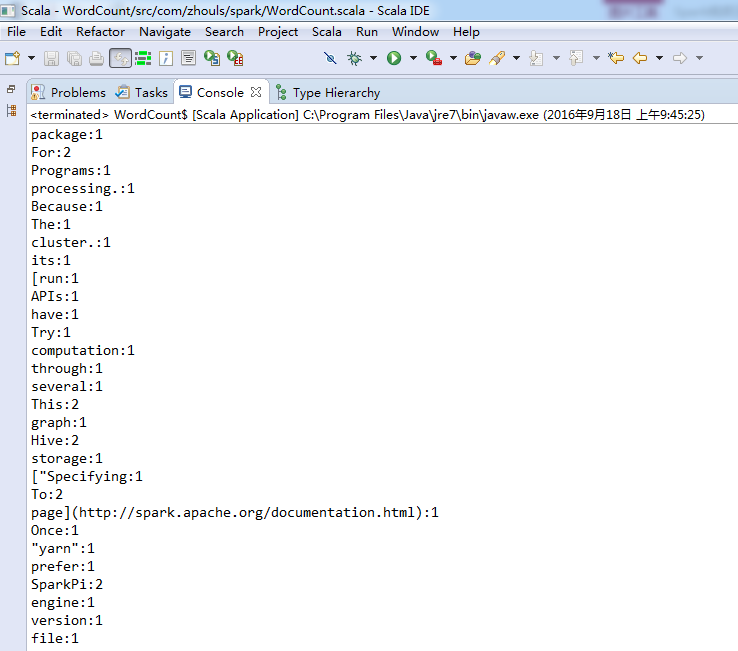
// val lines:RDD[String] = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度
// val lines = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度
// val lines = sc.textFile("hdfs://SparkSingleNode:9000/README.md", 1)//没必要会感知上下文
// val lines = sc.textFile("/README.md", 1)//path指的是文件路径,minPartitions指的是最小并行度
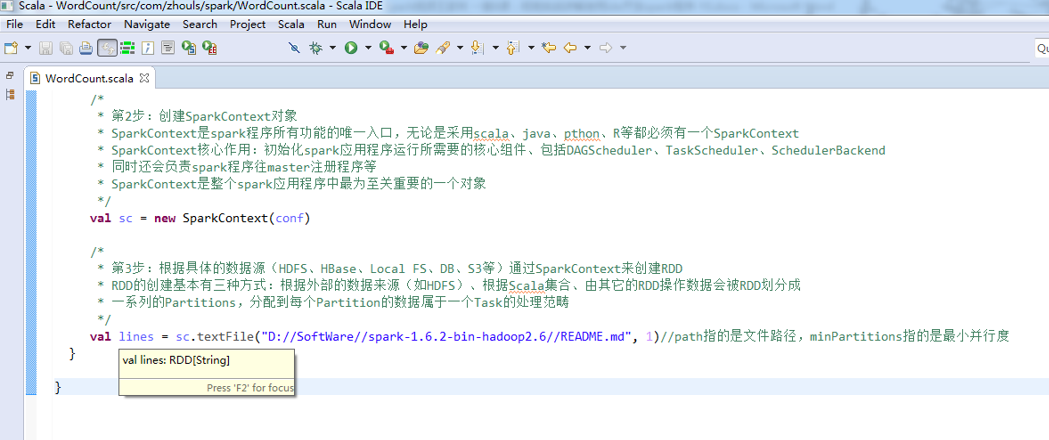
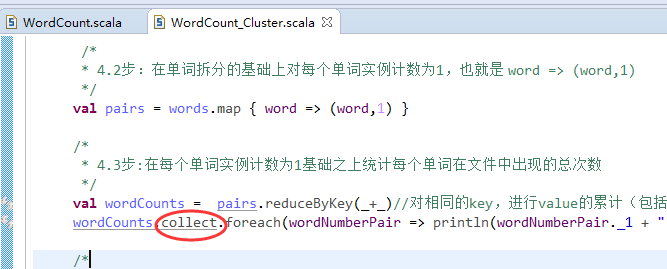
val lines = sc.textFile("/README.md")//为什么,这里不写并行度了呢?因为,hdfs会有一个默认的
如,我们的这里/里,有188个文件,每个文件小于128M。
所以,会有128个小集合。
当然,若是大于的话,我们可以人为干预,如3等
![]()
做好程序修改之后,
![]()
![]()
我这里啊,遇到如上的错误。
http://blog.csdn.net/weipanp/article/details/42713121
(3)Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
at org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(Native Method)
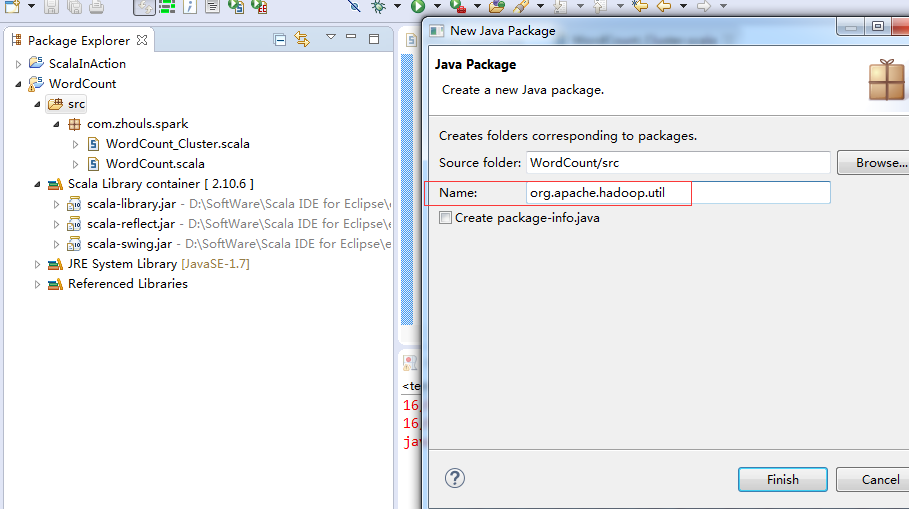
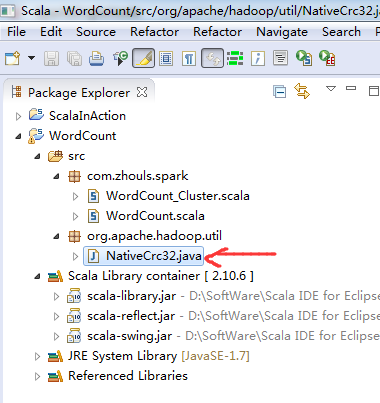
修复方法:在hadoop2.6源码里找到NativeCrc32.java,创建与源码一样的包名,拷贝NativeCrc32.java到该包工程目录下。
![]()
![]()
hadoop-2.6.0-src/hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/util/NativeCrc32.java
![]()
![]()
![]()
![]()
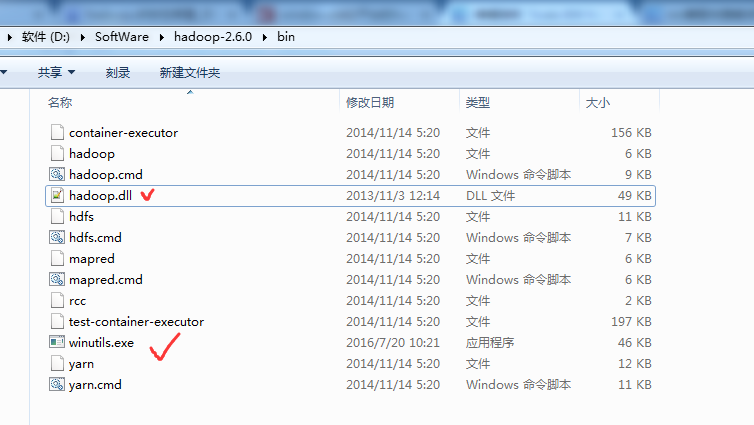
以及,缺少hadoop.dll,注意是64位的。放到hadoop-2.6.0下的bin目录下
![]()
![]()
玩玩spark-1.5.2-bin-hadoop2.6.tgz
![]()
![]()
继续,,,出现了一些问题!
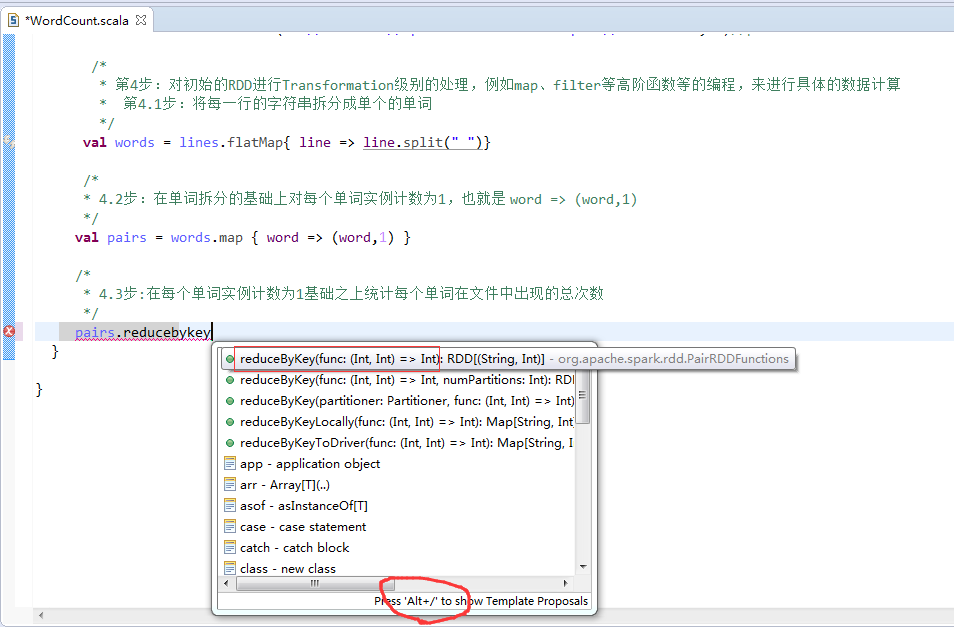
其实啊,在集群里,模板就是如下
val file = spark.textFile("hdfs://...”)
val counts = file.flatMap("line => line.spilt(" "))
.map(word => (word,1))
.reduceByKey(_+_)
counts.saveAsTextFile("hdfs://...”)
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5880006.html,如需转载请自行联系原作者