这是从程度开发层面来说,为了方便和提高开发人员。
这个工具Bytes类,有很多很多方法,帮助我们HBase编程开发人员,提高开发。
这里,我只赘述,很常用的!
![]()
![]()
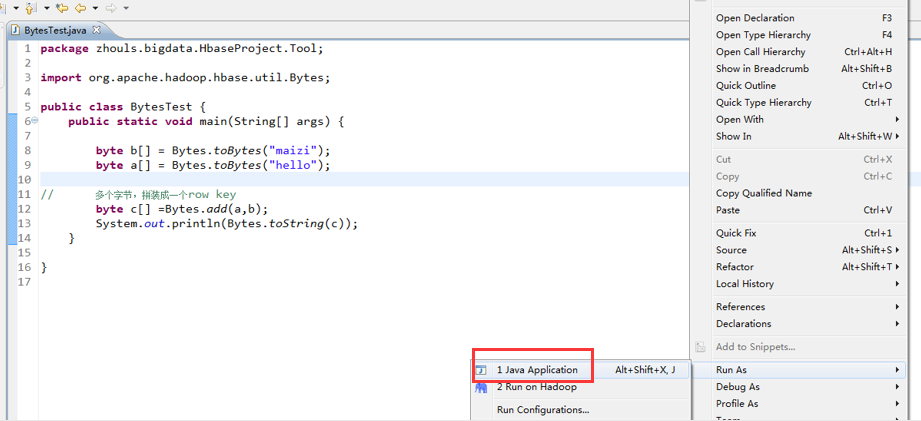
1 package zhouls.bigdata.HbaseProject.Tool;
2
3 import org.apache.hadoop.hbase.util.Bytes;
4
5 public class BytesTest {
6 public static void main(String[] args) {
7 byte b[] = Bytes.toBytes("maizi");
8 byte a[] = Bytes.toBytes("hello");
9
10 // 多个字节,拼装成一个row key
11 byte c[] =Bytes.add(a,b);
12 System.out.println(Bytes.toString(c));
13 }
14 }
![]()
hellomaizi
![]()
1 package zhouls.bigdata.HbaseProject.Tool;
2
3 import org.apache.hadoop.hbase.util.Bytes;
4
5 public class BytesTest {
6 public static void main(String[] args) {
7 byte b[] = Bytes.toBytes("maizi");
8 byte a[] = Bytes.toBytes("hello");
9 // 多个字节,拼装成一个row key
10 byte c[] =Bytes.add(a,b);
11 System.out.println(Bytes.toString(c));
12 byte d[] = Bytes.head(c, 5);
13 System.out.println(Bytes.toString(d));
14 }
15 }
![]()
hellomaizi
hello
![]()
1 package zhouls.bigdata.HbaseProject.Tool;
2
3 import org.apache.hadoop.hbase.util.Bytes;
4
5 public class BytesTest {
6 public static void main(String[] args) {
7 byte b[] = Bytes.toBytes("maizi");
8 byte a[] = Bytes.toBytes("hello");
9 // 多个字节,拼装成一个row key
10 byte c[] =Bytes.add(a,b);
11 System.out.println(Bytes.toString(c));
12
13 byte d[] = Bytes.head(c, 5);
14 System.out.println(Bytes.toString(d));
15
16 byte e[] = Bytes.tail(c, 3);
17 System.out.println(Bytes.toString(e));
18 }
19 }
![]()
hellomaizi
hello
izi
这里,我只是做一个,抛砖引玉的作用,大家,一定要去看到我这篇博文,下去之后,多实践和研究Bytes这个工具类的其他方法。(一定!!!)
![]()
对于,HBase的编程,是非常必须,掌握和熟练的。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6159444.html,如需转载请自行联系原作者