MainFrame大型机行业应用介绍
大型机(mainframe)这个词,最初是指装在非常大的带框铁盒子里的大型计算机系统,以用来同小一些的迷你机和微型机有所区别。虽然这个词已经通过不同方式被使用了很多年,大多数时候它却是指system/360 开始的一系列的IBM计算机。这个词也可以用来指由其他厂商,如Amdahl, Hitachi Data Systems (HDS) 制造的兼容的系统。
近年来,随着国内银行、保险、证券和海关等企事业的处理信息需求量猛增,对处理速度的要求越来越高,要求响应时间越来越短,在这种情况下这些行业逐渐提出了对大型机的需求。
现在,不单在银行业,IBM 大型主机已经在国内各主要领域例如金融、制造、交通等行业得到广泛应用,帮助中国各行各业的信息化进程跃入了一个新的阶段。例如:国内五大银行:中国银行、农业银行、工商银行、建设银行、交通银行,目前的核心系统都建立在IBM大型机的平台上。国外的银行包括花旗、汇丰、渣打等也有建立在大型机上的系统。在航空交通领域,国内的中航信采用大型机运行航空售票交易系统。此外还有许多企业也需要IBM大型机技术人才进行应用程序的开发,例如IBM, first data等。
2传统MainFrame大机在技术上遇到的问题和性能瓶颈
遇到的问题:
-
在业务操作层面,操作风险高、手工作业量大、业务流程繁琐、系统间业务分离
-
在 IT 架构方面,处理速度慢,响应周期长;为保证催收效率,需多系统配合;集中式架构缺乏横向扩展能力、特别是关系型数据库难于扩展;
-
在数据融合方面,不支持非结构化数据的处理、更多业务数据没有引入(如签证和净化器数据)、多系统之间数据不同步,存在差异。
性能瓶颈:
3传统大数据解决方案与潜在不足
由于传统Hadoop大数据平台体系架构用于日志信息等非结构化数据并行分析处理,并不是为了解决关系型数据日常增删改查(CRUD)的问题,所以在单条数据查询上性能稍慢。
另外,来自银行前端应用,如内部业务系统、网点客户查询、监管查询、网银查询等,存在并发量大、访问频繁的特点。由于Hadoop平台也不足以支撑来自前端应用的高并发访问,因此需要引入能够应付大机高并发查询的关键组件。
-
方案一:
HDFS+MapReduce:方案直接被否,无应用级容灾架构
-
方案二:
HDFS+HBase+Hive:HBase 结构稀疏、Hive 对SQL标准支持不完全、Hive API 散乱,二次开发有难度,无应用级容灾架构
-
方案三:
HDFS+Spark:Spark 对SQL标准支持较好、但不能支撑高并发访问,无应用级容灾架构
4信用卡中心大数据平台与银行其他系统对接
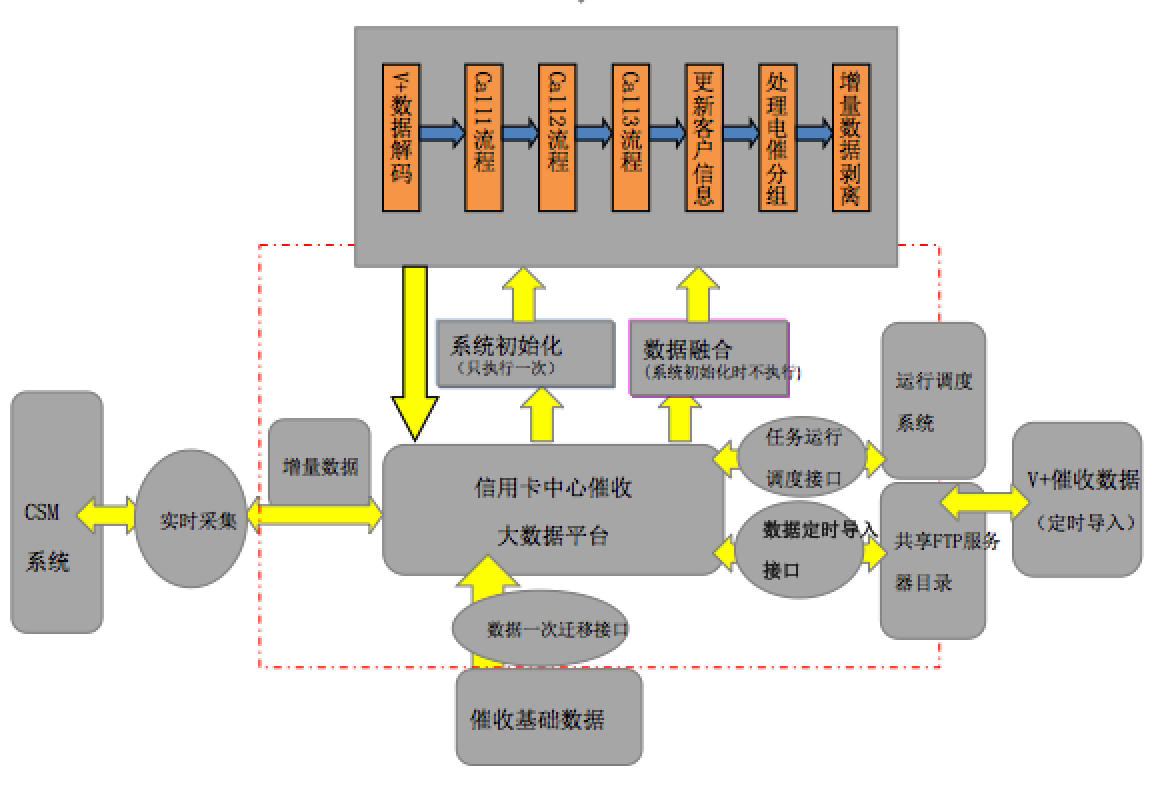
基本上国内所有银行的信用卡中心都是银行的核心IT系统之一,它对接的应用系统众多,系统间结构异常复杂,尤其是Call流程有100多个,改造起来工作量蛮大。
![20160615103230768.png]()
以信用卡中心催收大数据平台为例,大数据平台需要对接的外围系统有CSM系统、催收系统、营帐系统、网银系统、监管系统、柜台系统等。
信用卡V+核心系统统一采集管理外围数据(包括人行征信记录、第三方评估数据、申请信息、账户数据、额度数据、交易数据、卡片数据、客户数据等),经过初步加工处理,形成基础数据。
这些基础数据都存储在大机的 Oracle数据库中。
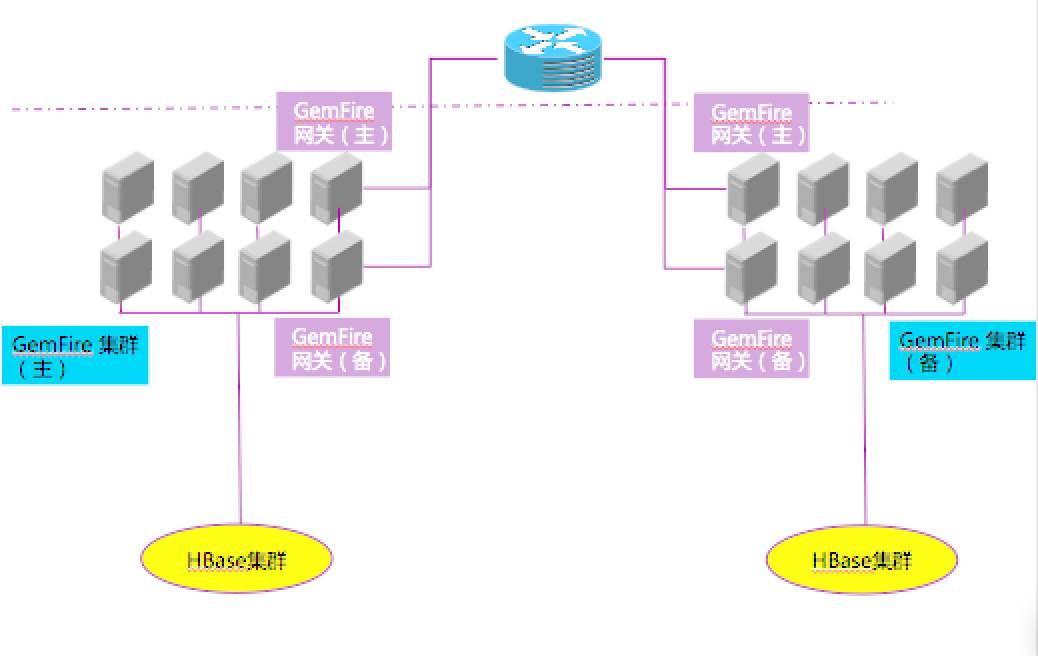
5大数据平台最终方案:GemFire+HBase

大数据平台采用GmFire+HBase作为大数据平台的两个核心组件,GemFire 使用高速分布式缓存支撑前端并发访问,使用SQL接口与前端查询系统的应用逻辑进行对接,起到平滑迁移应用到大数据平台的目的;HBase 主要用于保存全量的历史数据文件。(文章最后会对GemFire分布式数据处理平台做一个简要介绍)
CWS系统从 Oracle 数据定时推送增量数据到GemFire 集群中,数据进入 GemFire 集群后会和 HBase 的数据进行数据完整性校验和数据格式统一处理。这里面得益于 GemFire 和 HBase早已经做了集成,GemFire CacheServer可以很轻松地从 HBase Region中读写数据放入到自己的Region中。
应用查询策略:
-
全时间段查询
-
同步查询
-
异步查询
-
多条件组合查询
-
多查询接口报文封装
将大型机的数据全量导入到 HBase 中采取生成 HFile 的方式。将 HFile 挂载到 HBase 数据库上,当GemFire 需要从 HBase 中取数据时,与 HBase 交互,将数据加载到 Cache 中。

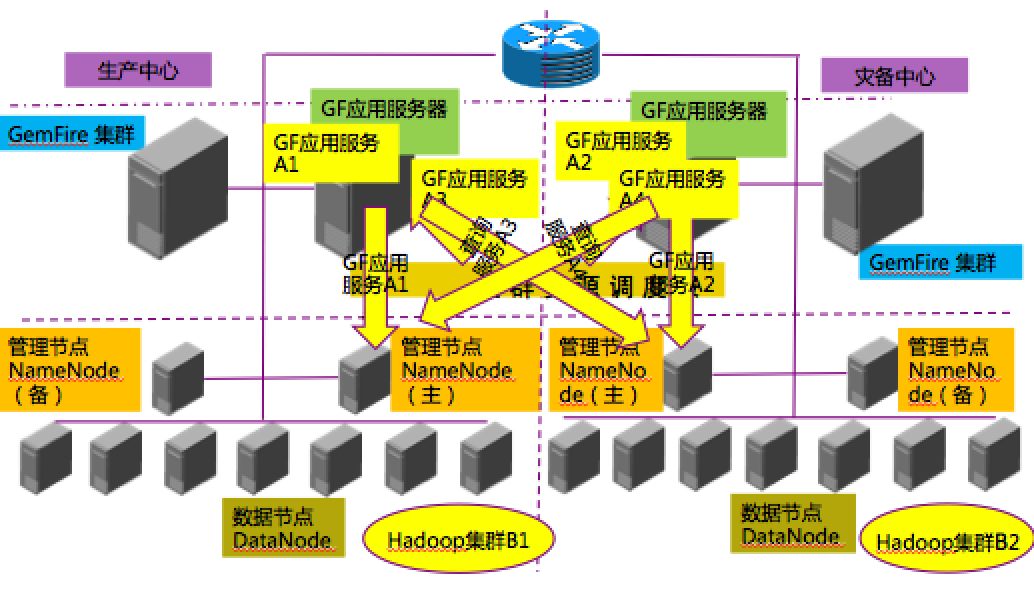
6大数据平台容灾设计
由于银行对核心应用系统的安全等保和业务连续性要求,强制要求异地双活的应用系统架构,因此利用 GemFire 的网关服务器进行异地双活容灾。
![20160615103311619.jpg]()
当某个数据中心出现故障后,GF 应用服务可自动切换到灾备数据中心继续访问应用。
![20160615103325520.png]()
7GemFire分布式数据处理平台介绍
GemFire 是Pivotal 旗下的一款分布式数据处理平台产品,现在已经开源为 Apache Geode 工程,网址为 http://github.com/apache/incubator-geode。
社群的朋友可能对GemFire不太了解,我先介绍一下GemFire的整体情况。
GemFire的自身功能比较多,首先它是一个基于 JVM 的 NoSQL分布式数据处理平台,同时集中间件、缓存、消息队列、事件处理引擎、NoSQL数据库于一身的分布式内存数据处理平台。
GemFire具有如下的功能特性:
GemFire分布式内存数据处理平台使用网格化的缓存集群,构成了统一的、应用缓存系统。所有数据都放入到内存当中,所有的缓存操作都被抽象化为对缓存集群的单点引用,换句话说,你的应用能够与缓存集群中的单个逻辑单元交互,而不用考虑集群中到底有多少缓存集群。
GemFire物理架构主要的组成模块是缓存服务器,位置服务器,缓存客户端组成。
总结:大数据平台单侧数据中心使用节点数为GemFire 20+, NameNode 2个, DataNode 7个。
催收系统经过大机负载下移改造后的系统分散运行压力控制,CPU运行率控制在稳定低损耗状态;承载了来自前端应用的10000次/秒的并发访问;跑批速度提升50%为业务扩展功能提供时间;系统监控实时可控。
COBOL服务测试结果:
![20160615103340981.png]()
在技术创新方面,带来系统应用级容灾,提供了高可用性,大数据平台分布式架构,带来易扩展、高性能、低硬件成本,采用双中心、 双集群、纯双活架构,多数据副本均衡分布,系统应用级容灾,带来了应用级的高可用性。
在业务创新方面,大数据实时在线快速查询,提高效率;PDF加水印防篡改,加强风险防控;多种查询方式,提升服务水平;长时间跨度查询,减少柜员工作量;整合数据,提高数据质量,统一客户体验;提供查询日志,查询留痕迹,控制风险。
作者介绍 杨旭钧
-
Geode 开源社区发起人,负责在国内推广Apache Geode,对国内Gemfire 用户提供技术咨询、培训及应用改造等工作。
-
多年银行、保险行业的金融系统的规划、设计和开发经验,参与过多个国内外银行、互联网电商与移动支付领域项目。
-
曾就职与VMware、 Accenture、慧聪等多家公司,服务客户包括花旗银行、中国外汇交易中心、中国人民银行、国家电网等。
本文来自云栖社区合作伙伴"DBAplus",原文发布时间:2016-06-15