大部分概念Kubernetes官网都有详细介绍,Kubernetes中文官网 https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/
![]()
官网还提供一个比较好的功能是能在线互动,见互动教程,类似实操命令初步感受。
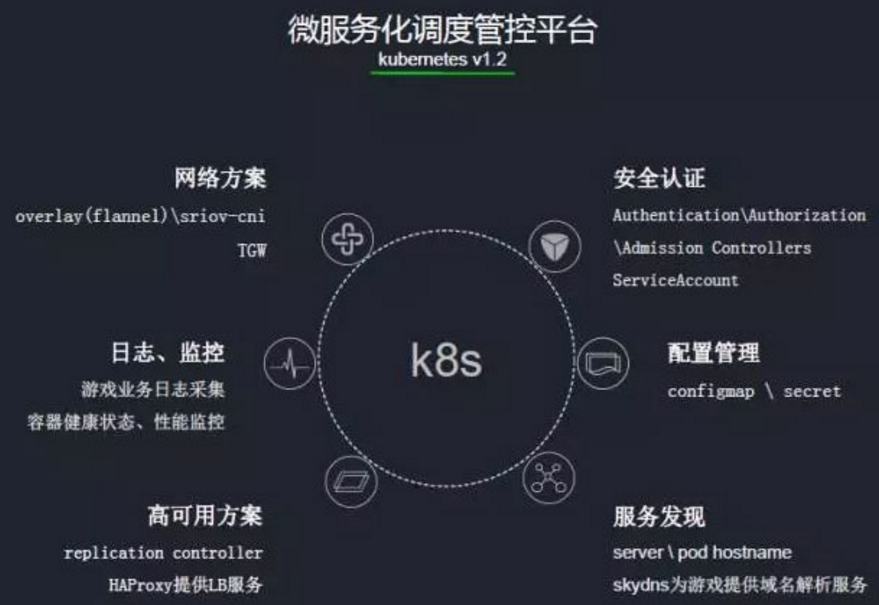
Kubernetes主要功能
- 基于容器的应用部署、维护和滚动升级
- 负载均衡和服务发现
- 跨机器和跨地区的集群调度
- 自动伸缩
- 无状态服务和有状态服务
- 广泛的 Volume 支持
- 插件机制保证扩展性
Kubernetes是谷歌开源的容器集群管理系统
Kubernetes 提供了很多的功能,它可以简化应用程序的工作流,加快开发速度。使用Kubernetes只需一个部署文件,使用一条命令就可以部署多层容器(前端,后台等)的完整集群。
核心概念
Kubernetes 主要由以下几个核心组件组成:
- etcd 保存了整个集群的状态;
- apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制;
- controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上;
- kubelet 负责维护容器的生命周期,同时也负责 Volume(CVI)和网络(CNI)的管理;
- Container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI);
- kube-proxy 负责为 Service 提供 cluster 内部的服务发现和负载均衡
典型的Kubernetes架构图
![]()
上图可以看到如下组件,使用特别的图标表示Service和Label:
- Pod
- Container(容器)
- Label(
![label]() )(标签)
)(标签)
- Replication Controller(复制控制器)
- Service(
![enter image description here]() )(服务)
)(服务)
- Node(节点)
- Kubernetes Master(Kubernetes主节点)
Pod
Pod在节点上,包含一组容器和卷。同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信。Pod是短暂的,不是持续性实体。如果Pod是短暂的,那么我怎么才能持久化容器数据使其能够跨重启而存在呢? Kubernetes支持卷的概念,因此可以使用持久化的卷类型。如果Pod是短暂的,那么重启时IP地址可能会改变,那么怎么才能从前端容器正确可靠地指向后台容器呢?这时可以使用Service。
Lable
一些Pod有Label。一个Label是attach到Pod的一对键/值对,用来传递用户定义的属性。比如,你可能创建了一个"tier"和“app”标签,通过Label(tier=frontend, app=myapp)来标记前端Pod容器,使用Label(tier=backend, app=myapp)标记后台Pod。然后可以使用Selectors选择带有特定Label的Pod,并且将Service或者Replication Controller应用到上面。
Replication Controller
Replication Controller确保任意时间都有指定数量的Pod“副本”在运行。如果为某个Pod创建了Replication Controller并且指定3个副本,它会创建3个Pod,并且持续监控它们。如果某个Pod不响应,那么Replication Controller会替换它,保持总数为3.如下面的动画所示:
如果之前不响应的Pod恢复了,现在就有4个Pod了,那么Replication Controller会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Replication Controller会立刻启动2个新Pod,保证总数为5。还可以按照这样的方式缩小Pod,这个特性在执行滚动升级时很有用。
当创建Replication Controller时,需要指定两个东西:
- Pod模板:用来创建Pod副本的模板
- Label:Replication Controller需要监控的Pod的标签。
现在已经创建了Pod的一些副本,那么在这些副本上如何均衡负载呢?我们需要的是Service。
Service
Service是定义一系列Pod以及访问这些Pod的策略的一层抽象。Service通过Label找到Pod组。因为Service是抽象的,所以在图表里通常看不到它们的存在,这也就让这一概念更难以理解。
假定有2个后台Pod,并且定义后台Service的名称为‘backend-service’,lable选择器为(tier=backend, app=myapp)。backend-service 的Service会完成如下两件重要的事情:
- 会为Service创建一个本地集群的DNS入口,因此前端Pod只需要DNS查找主机名为 ‘backend-service’,就能够解析出前端应用程序可用的IP地址。
- 现在前端已经得到了后台服务的IP地址,但是它应该访问2个后台Pod的哪一个呢?Service在这2个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个(如下面的动画所示)。通过每个Node上运行的代理(kube-proxy)完成。这里有更多技术细节。
如果不进入网络配置,那么达到透明的负载均衡目标所涉及的底层网络和路由相对先进。
有一个特别类型的Kubernetes Service,称为'LoadBalancer',作为外部负载均衡器使用,在一定数量的Pod之间均衡流量。比如,对于负载均衡Web流量很有用。
Pod与Service
每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,多个Pod副本组成了一个集群来提供服务,一般的做法是部署一个负载均衡器来访问它们,为这组Pod开启一个对外的服务端口如8000,并且将这些Pod的Endpoint列表加入8000端口的转发列表中,客户端可以通过负载均衡器的对外IP地址+服务端口来访问此服务。运行在Node上的kube-proxy其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并且在内部实现服务的负载均衡与会话保持机制。Service不是共用一个负载均衡器的IP地址,而是每个Servcie分配一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP。
Node IP
Node节点的IP地址,是Kubernetes集群中每个节点的物理网卡的IP地址,是真是存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信;
Pod IP
Pod的IP地址,是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,位于不同Node上的Pod能够彼此通信,需要通过Pod IP所在的虚拟二层网络进行通信,而真实的TCP流量则是通过Node IP所在的物理网卡流出的;
Cluster IP
Service的IP地址。特性如下:
仅仅作用于Kubernetes Servcie这个对象,并由Kubernetes管理和分配IP地址;
无法被Ping,因为没有一个“实体网络对象”来响应;
只能结合Service Port组成一个具体的通信端口;
Node IP网、Pod IP网域Cluster IP网之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与IP路由有很大的不同;
Node
节点(上图橘色方框)是物理或者虚拟机器,作为Kubernetes worker,通常称为Minion。每个节点都运行如下Kubernetes关键组件:
- Kubelet:是主节点代理。
- Kube-proxy:Service使用其将链接路由到Pod,如上文所述。
- Docker或Rocket:Kubernetes使用的容器技术来创建容器。
Kubernetes Master
集群拥有一个Kubernetes Master。Kubernetes Master提供集群的独特视角,并且拥有一系列组件,比如Kubernetes API Server。API Server提供可以用来和集群交互的REST端点。master节点包括用来创建和复制Pod的Replication Controller。
应用
Kubernetes进行蓝绿部署
应用程序更新到一个新版本时,部署功能能够帮您对容器进行滚动更新,若有异常可自动回滚。
Kubernetes在腾讯游戏的应用
接入容器数超过两万,接入的业务也有两百多款,包括手游、端游、页游。
![]()
基于Kubernetes的Spark集群部署
相比于在物理机上部署,在Kubernetes集群上部署Spark集群,具有以下优势:
- 快速部署:安装1000台级别的Spark集群,在Kubernetes集群上只需设定worker副本数目replicas=1000,即可一键部署。
- 快速升级:升级Spark版本,只需替换Spark镜像,一键升级。
- 弹性伸缩:需要扩容、缩容时,自动修改worker副本数目replicas即可。
- 高一致性:各个Kubernetes节点上运行的Spark环境一致、版本一致
- 高可用性:如果Spark所在的某些node或pod死掉,Kubernetes会自动将计算任务,转移到其他node或创建新pod。
- 强隔离性:通过设定资源配额等方式,可与WebService应用部署在同一集群,提升机器资源使用效率,从而降低服务器成本。
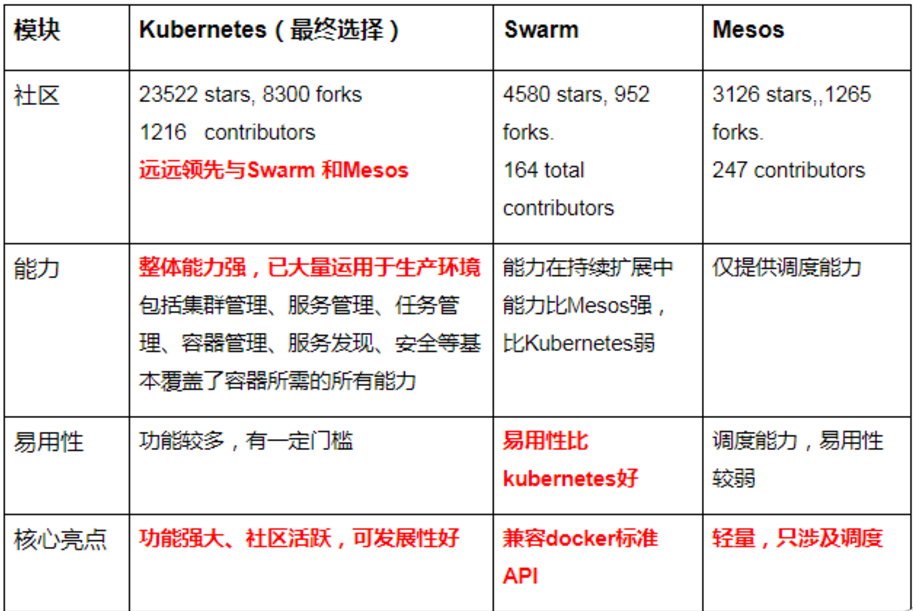
Kubernetes、Docker Swarm、 Mesos
![]()
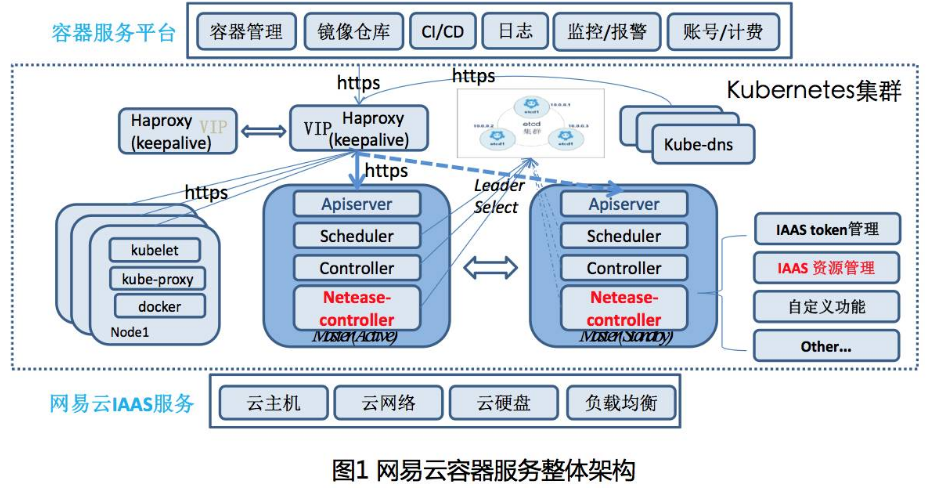
网易云容器如何解决Kubernetes在公有云上的问题
![]()
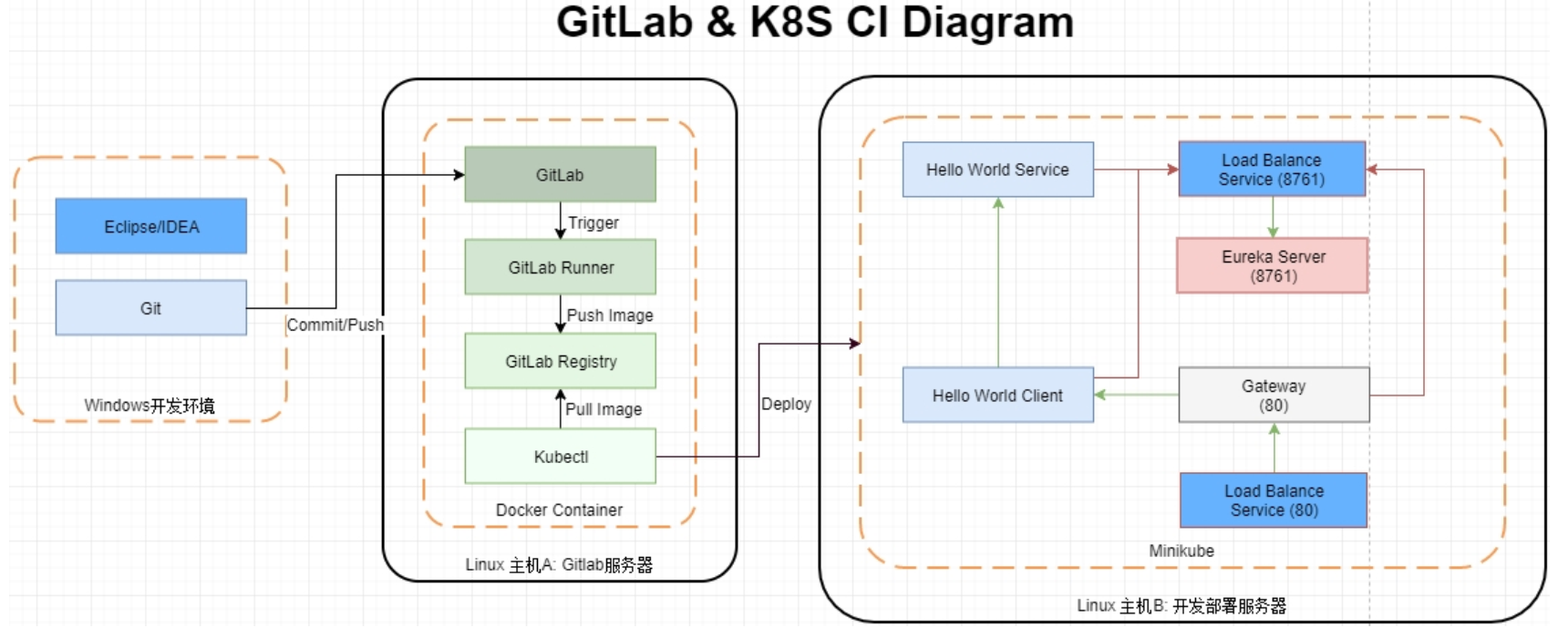
微服务持续集成 Spring Cloud + GitLab + Docker + K8S
![]()
微服务组成: Gateway api 网关 > 消费端 > 服务端 和 一个注册中心,共 4 个 Spring Boot 项目
![]()
Kubernetes实际要用起来问题还有很多,需要躺很多坑,搭建起一套Kubernetes环境就可能会让你从入门到放弃,再接再励。
资料来源:
http://www.dockone.io/article/932

 )(标签)
)(标签) )(服务)
)(服务)