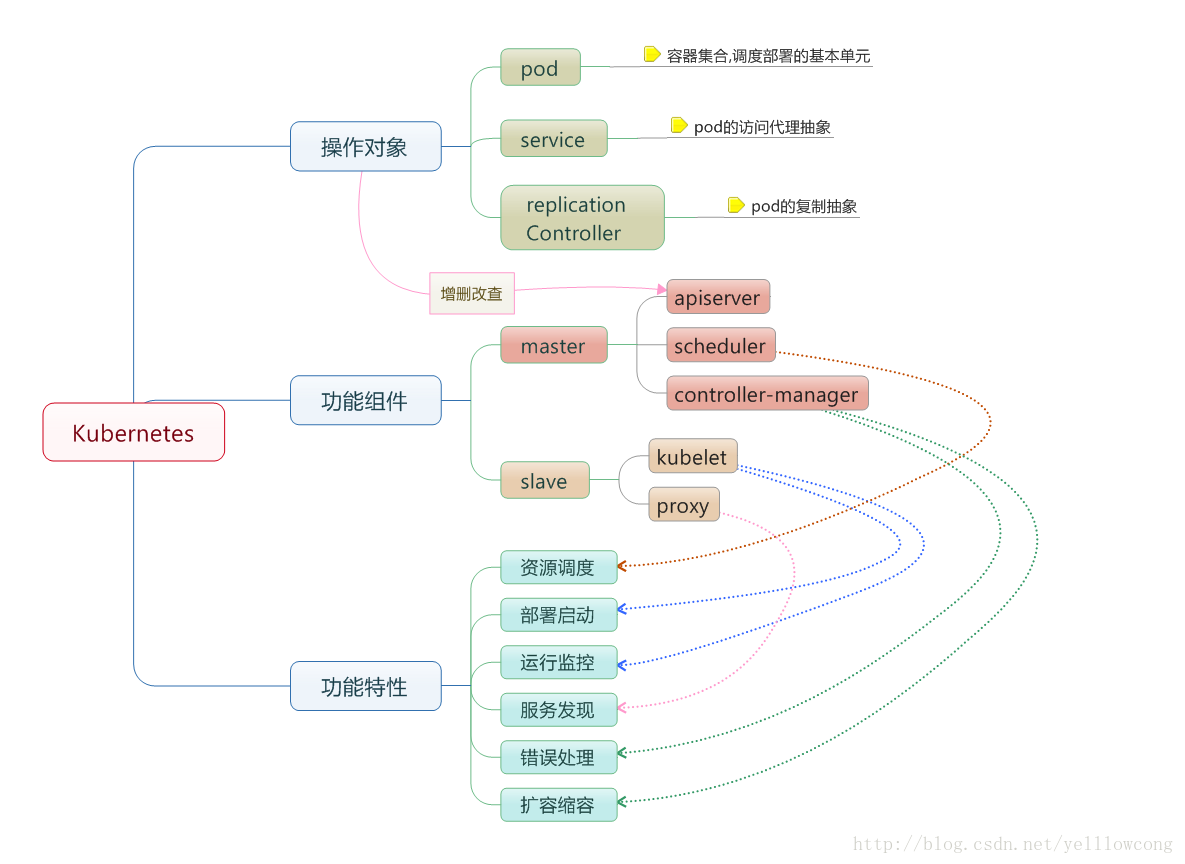
Kubernate安装的时候,需要先安装主节点,然后安装从节点,主节点中,需要注意配置文件的配置,而且ETCD最好做单独服务,让etcd先启动后,然后再启动kubernate的master和node子节点,Master节点 有apiServer ,Scheduler,Controller-manager,Node节点有:kubelet和proxy和flanned,flanned是用来管理docker容器网络的,而且需要结合etcd来使用。
kubernate容器的调度模型
![这里写图片描述]()
服务配置
| 服务器 |
服务 |
| master |
apiserver, controller-manager, scheduler |
| node |
flannel, docker, kubelet, kube-proxy |
| etcd |
etcd |
在安装前,一定要先安装ETCD,然后是kubernetes-master,最后是kubernetes-node, 在子节点和从节点中,都需要安装flannel ,通过flannel对Kubernetes集群的网络进行管理
准备工作
a.关闭SELINUX
关闭SELINUX,可以解决程序安装然后 不执行的问题。
#修改配置文件
vim /etc/selinux/config
#设定不可用
SELINUX=disabled
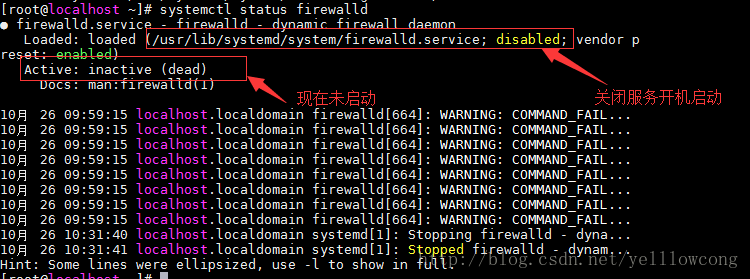
关闭防火墙
#关闭防火墙,就不用天天管他了,还要配置ip啥的,烦人
systemctl stop firewalld.service
systemctl disable firewalld.service
#查看防火墙状态
systemctl status firewalld
![这里写图片描述]()
安装etcd 和安装flanned
关于Etcd和flanned的安装,大家可以查看我的文章,http://blog.csdn.net/yelllowcong/article/details/78303626
系统架构
| ip地址 |
节点 |
服务 |
| 192.168.66.100 |
master |
etcd、kube-apiserver、kube-controller-manager和kube-scheduler组件 |
| 192.168.66.101 |
node |
flannel 、kubelet、kube-proxy |
1、主节点安装
1.1安装Etcd
#安装
etcd yum install etcd
#启动服务
systemctl start etcd
#开机启动
systemctl enable etcd
#获取节点数据,看本生好不好用,然后再进行下一步,配置ETCD的操作(很重要,不进行这步,容易发生错误,不知道是那个地方的问题)
etcdctl get /
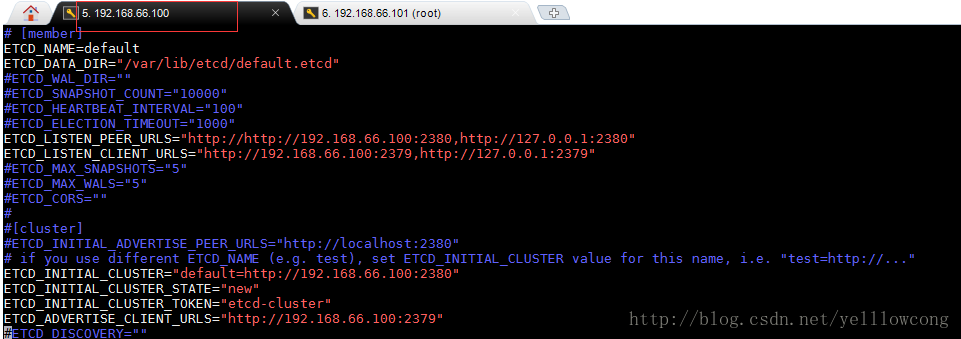
#配置etcd
vim /etc/etcd/etcd.conf
#配置文件 # [member]
ETCD_NAME=default
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://192.168.66.100:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.66.100:2379,http://127.0.0.1:2379" #[cluster]
ETCD_INITIAL_CLUSTER="default=http://192.167.66.100:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_ADVERTISE_CLIENT_URLS="http://192.168.66.100:2379" #重启服务
systemctl restart etcd
#设定容器网络
etcdctl set /atomic.io/network/config '{"Network":"172.17.0.0/16"}'
![这里写图片描述]()
PS:其中网络号172.17.0.0/16与docker中的docker0网络一致(若不一致,可修改docker0网络或者配置上述etcd网络);atomic.io与下面的Flannel配置中的FLANNEL_ETCD_PREFIX对应
![这里写图片描述]()
1.2kubernetes-master 安装
yum install kubernetes-master
1.2.1配置apiserver
配置文件/etc/kubernetes/apiserver,内容包括:绑定主机的IP地址、端口号、etcd服务地址、Service所需的Cluster IP池、一系列admission控制策略等
1、-insecure-bind-address参数默认为127.0.0.1,即API-server绑定的安全IP只有127.0.0.1,相当于一个白名单,修改成如下值后,表示运行所有节点进行访问。
-insecure-bind-address=“0.0.0.0” (这个地方需要注意一点,现在我还没有遇到这个问题,我设定的是当前主机的ip,所以也没啥问题)
2、去掉SecurityContextDeny,ServiceAccount,这是权限相关的,测试就不要加上这两个
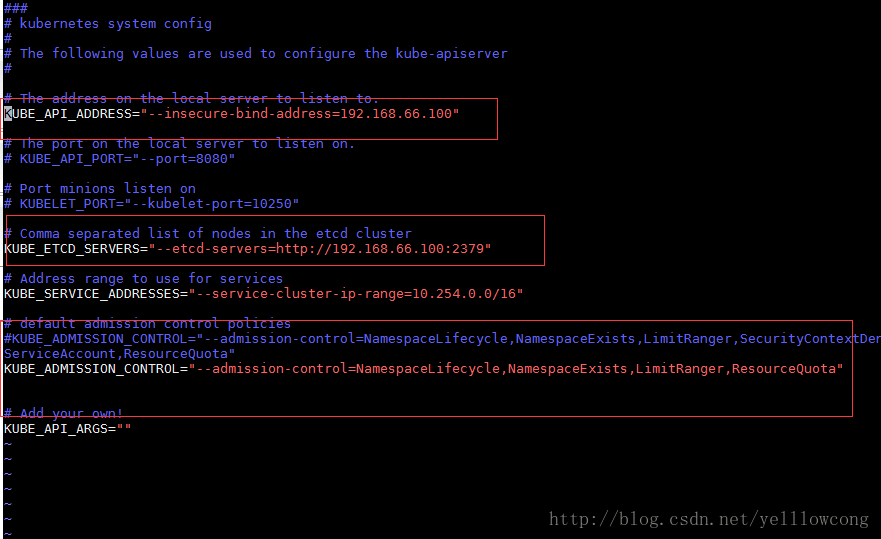
vim /etc/kubernetes/apiserver
# API server的访问地址 ,这个需要修改,不然就只能自己本机访问
KUBE_API_ADDRESS="--insecure-bind-address=192.168.66.100" # 监听端口号 # KUBE_API_PORT="--port=8080" # Port minions listen on # KUBELET_PORT="--kubelet-port=10250" # ETCD服务的配置
KUBE_ETCD_SERVERS="--etcd-servers=http://192.168.66.100:2379" # Address range to use for services
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16" # default admission control policies #KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota" #去掉SecurityContextDeny,ServiceAccount,这是权限相关的
KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQuota" # Add your own!
KUBE_API_ARGS=""
![这里写图片描述]()
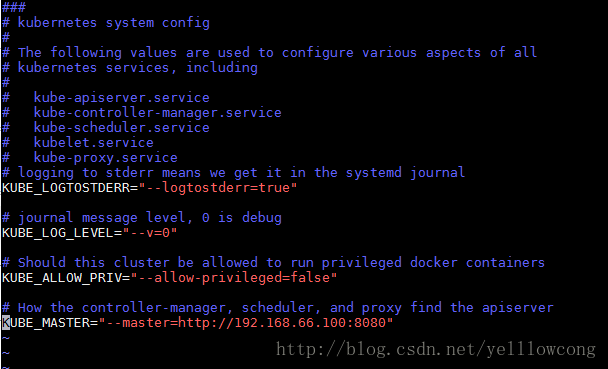
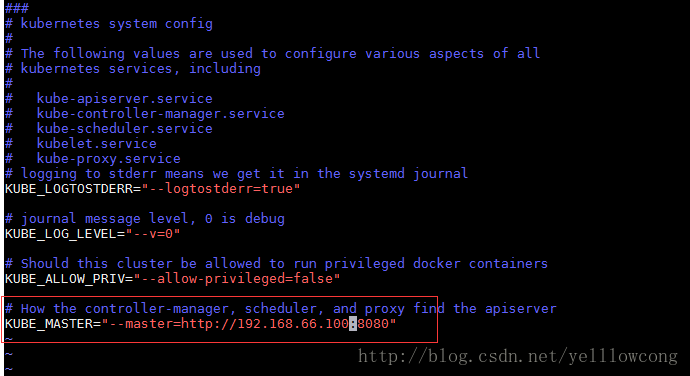
1.2.3配置Kubernate全局
配置文件/etc/kubernetes/config,文件的内容为所有服务都需要的参数
vim /etc/kubernetes/config
KUBE_LOGTOSTDERR="--logtostderr=true" # journal message level, 0 is debug
KUBE_LOG_LEVEL="--v=0" # Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="--allow-privileged=false" # How the controller-manager, scheduler, and proxy find the apiserver #设定maseter节点
KUBE_MASTER="--master=http://192.168.66.120:8080"
![这里写图片描述]()
1.2.4启动服务
完成后,通过systemctl start命令启动3个服务。同时,使用systemctl enable命令将服务加入开机启动列表中。
#让配置生效
systemctl daemon-reload
#启动服务
systemctl start etcd kube-apiserver.service kube-controller-manager kube-scheduler
#重启服务
systemctl restart etcd kube-apiserver.service kube-controller-manager kube-scheduler
#设定开机启动
systemctl enable etcd kube-apiserver.service kube-controller-manager kube-scheduler
#
通过systemctl status 来验证服务启动的状态。
#日志查看
cat /var/log/messages |grep kube
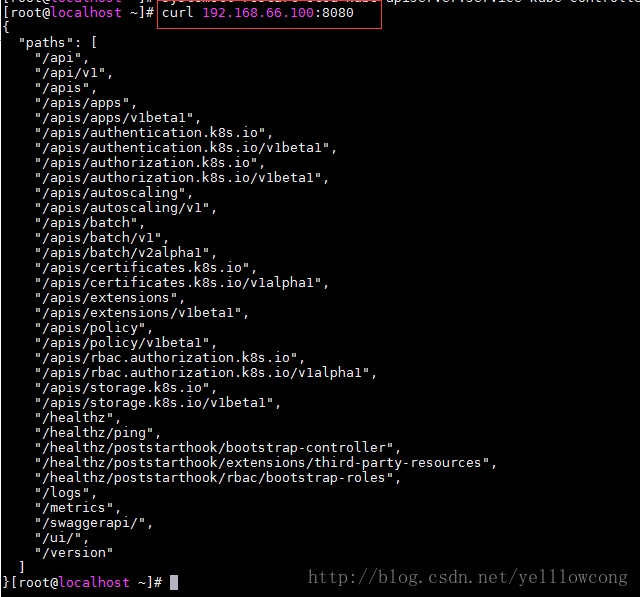
1.2.5测试master服务
获取节点的数据的时候,需要和/etc/kubernetes/apiserver 配置的KUBE_API_ADDRESS一致,不然就会连接不上
#这个ip需要和 curl 192.168.66.100:8080
![这里写图片描述]()
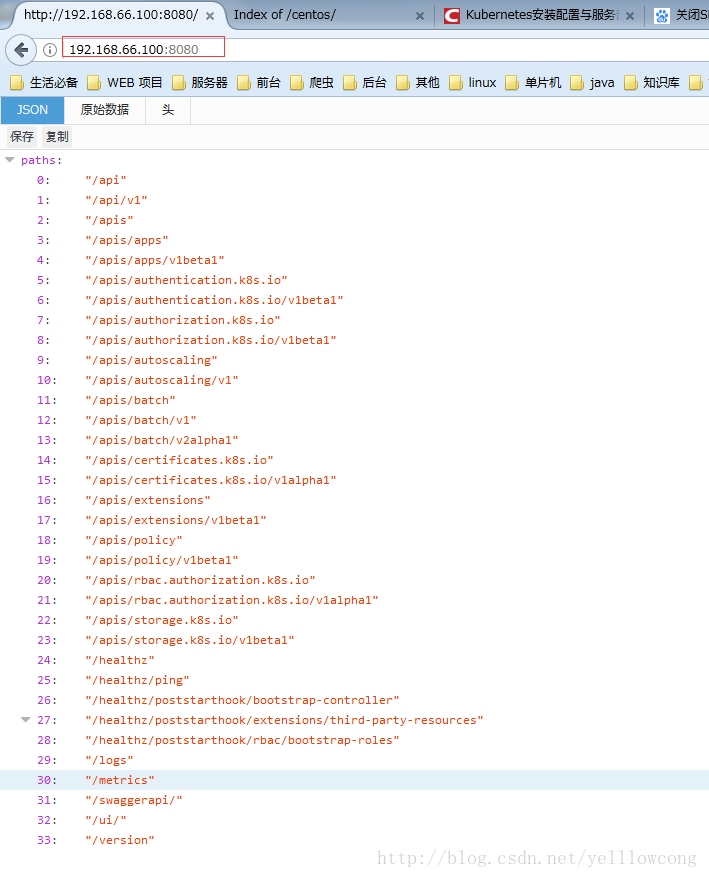
外网访问
![这里写图片描述]()
当使用的是127.0.0.1:8080的时候,访问不了服务,所以需要和KUBE_API_ADDRESS 自己配置的一致,不然就GG了
![这里写图片描述]()
2、子节点安装
2.1docker安装
yum install docker
#查看版本好,看docker是否安装成功
docker version
#设定开机启动
systemctl enable docker
#启动docker服务
systemctl start docker
2.1安装Flanneld
#安装
yum install flannel
#配置
vim /etc/sysconfig/flanneld
#设定etcd的服务地址
FLANNEL_ETCD_ENDPOINTS="http://192.168.66.100:2379" #设置etcd设定的网络信息
FLANNEL_ETCD_PREFIX="/atomic.io/network" #这个是设定flanneld的启动参数
FLANNEL_OPTIONS="--logtostderr=false --log_dir=/var/log/k8s/flannel/ --etcd-prefix=/atomic.io/network --etcd-endpoints=http://192.168.66.100:2379 --iface=eth0" #配置完成后需要重启flanneld
systemctl start flanneld
#设定开机启动
systemctl enable flanneld
#重启docker,这样就可以引用flanneld的网桥配置了
systemctl restart docker
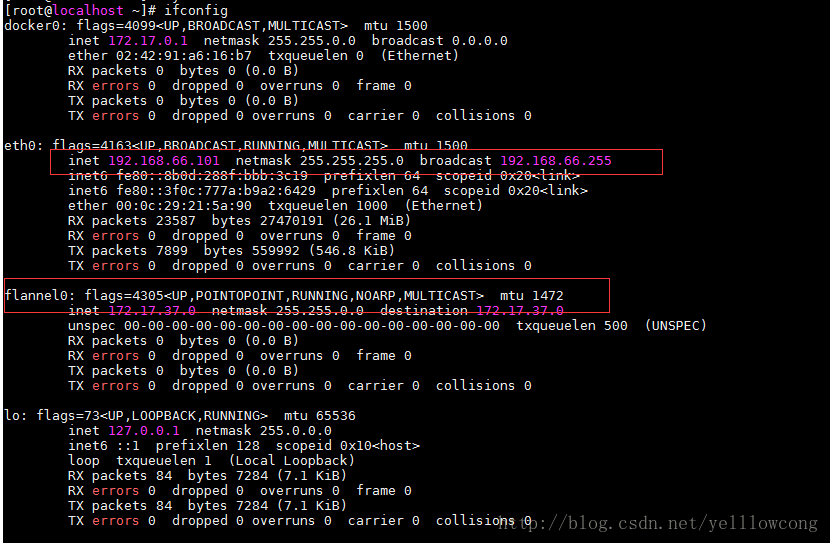
#ifconfig 查看flannel0 是否出来了,配置是否正确
ifconfig
![这里写图片描述]()
配置成功后,可以看到flannel0 网桥了,我的子节点(192.168.66.101)看到了flannel0网卡,以及docker0的网卡都修改成功了
![这里写图片描述]()
2.3kubernetes-node安装
2.3.1安装
yum install kubernetes-node
2.3.2配置kubernetes
设定api server,通过修改/etc/kubernetes/config文件的KUBE_MASTER ,
vim /etc/kubernetes/config
# journal message level, 0 is debug
KUBE_LOG_LEVEL="--v=0" # Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="--allow-privileged=false" #设定api server
KUBE_MASTER="--master=http://192.168.66.100:8080"
![这里写图片描述]()
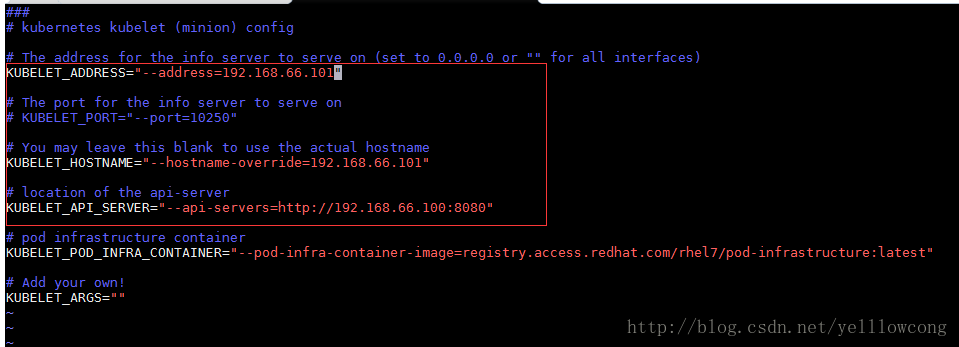
2.3.3配置kubelet组件
修改/etc/kubernetes/kubelet
vim /etc/kubernetes/kubelet
KUBELET_ADDRESS="--address=192.168.66.101" # The port for the info server to serve on # KUBELET_PORT="--port=10250" # 配置本机的地址
KUBELET_HOSTNAME="--hostname-override=192.168.66.101" # 配置apiserver api-server服务地址
KUBELET_API_SERVER="--api-servers=http://192.168.66.100:8080" # pod infrastructure container
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest" # Add your own!
KUBELET_ARGS=""
![这里写图片描述]()
2.3.3启动服务
#启动服务
systemctl start kubelet kube-proxy
#设定开机启动
systemctl enable kubelet kube-proxy
测试集群
在master节点运行,也就是主节点(192.168.66.100)
#直接获取节点,可能报错,导致这个问题的原因就是默认找本地的localhost:8080端口
kubectl get nodes
#指定ip,访问就正常了
kubectl -s http://192.168.66.100:8080 get nodes
若正常工作,可获取工作节点信息及运行状态为Ready,如下图:
![这里写图片描述]()
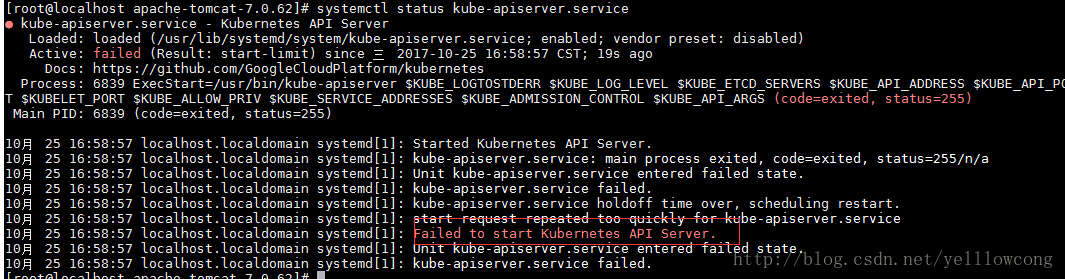
错误集合
1、 Failed to start Kubernetes API Server.
![这里写图片描述]()
导致这个问题的根本原因,是ip端口占用,导致服务启动失败。
2、The connection to the server localhost:8080 was refused - did you specify the right host or port?
默认就跑去连接自己本机的api server,所以导致了这个问题 ,可以通过指定连接的节点来解决这个问题
kubectl -s http://192.168.66.100:8080 version
![这里写图片描述]()
指定节点连接,指定连接,正常使用。
![这里写图片描述]()
本文转自掘金-
Kubernate之安装-yellowcong





 本文转自掘金-
本文转自掘金-
