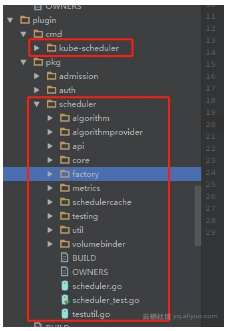
1.9中,kube-scheduler仍然是作为一个“plugin”放在k8s 代码中,在k8s根目录下的plugin目录中,cmd/kube-scheduler目录是其编译入口,pkg/scheduler目录是其主要核心代码。如图:
![4fe79201237cfa080240114804792ea5a46a482b]()
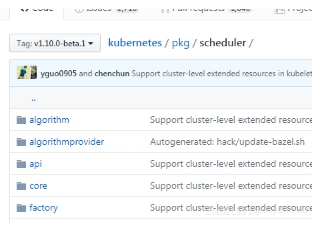
在即将发布的1.10中,社区将kube-scheduler从plugin中移出,嵌入到与api-server、kubelet等组件平级的目录。也即根目录下的cmd、pkg目录:
![a94dc6bda694982af9343ee9223c1428df8c9ebb]()
调度器的算法是如何生效的
调度器二进制启动
调度器可以在启动时指定其算法的来源。算法来源有三种:a)本地policy文件;b)policy configMap;c)指定提供者。
对象*scheduler.Config记录了算法来源,当启动参数中policy相关参数不为空时,会从相应的文件或者configMap中读取调度策略;否则检查algorithm-provider参数,这个参数会列出当前可用的provider,如果没有明确指定,那么代码将启动默认的provider:default
从policy读取的调度策略,其内容是一个policy结构
type Policy struct {
metav1.TypeMeta
// Holds the information to configure the fit predicate functions
Predicates []PredicatePolicy
// Holds the information to configure the priority functions
Priorities []PriorityPolicy
// Holds the information to communicate with the extender(s)
ExtenderConfigs []ExtenderConfig
// RequiredDuringScheduling affinity is not symmetric, but there is an implicit PreferredDuringScheduling affinity rule
// corresponding to every RequiredDuringScheduling affinity rule.
// HardPodAffinitySymmetricWeight represents the weight of implicit PreferredDuringScheduling affinity rule, in the range 1-100.
HardPodAffinitySymmetricWeight int32
}
代码会直接根据policy的内容,调用CreateFromKeys 方法去构建最终的scheduler
当没有指定policy时,如果没有指定provider,最后会执行下面这个函数
// Create creates a scheduler with the default algorithm provider. func (f *configFactory) Create() (*scheduler.Config, error) {
return f.CreateFromProvider(DefaultProvider)
}
随后也会调用CreateFromKeys 方法构建最终的genericScheduler
调度器算法注入
上面的过程中,会最终都调用到func (f *configFactory) CreateFromKeys。 这个函数将参数中的predicate算法、priority算法等注入到调用链中,这个调用链中的函数,会在每次调度pod时被调用。两个调用链分别是genericScheduler结构中的:
type genericScheduler struct {
...
predicates map[string]algorithm.FitPredicate
...
prioritizers []algorithm.PriorityConfig
...
}
当通过policy启动时,CreateFromKeys 方法的参数中的算法都记录到了policy对象中的成员变量里。而如果通过指定provider启动,参数中的算法都来自provider 的init方法。
我们通过阅读provider的init方法,以及init过程中引用到的plugins.go的一些方法,就能知道大概的流程是:
1.调度器的algorithmprovider目录下存放了一个defaults provider,以及一个plugins.go的文件,plugins.go提供了provider登记需要的一些方法。
2.plugins.go 中维护了一个全局的map:algorithmProviderMap, 这个map的key即provider的名字,value是一个结构,维护了两个string集合,用于记录该provider需要的prodicate算法名和priority算法名:
type AlgorithmProviderConfig struct {
FitPredicateKeys sets.String PriorityFunctionKeys sets.String
}
3.provider的init方法中调用factory.RegisterAlgorithmProvider方法,向上文的map中登记自己。登记时会提供自己本身包含的两类算法的集合。可参考defaults/defaults.go 中的:
registerAlgorithmProvider(defaultPredicates(), defaultPriorities())
defaultPredicates()、defaultPriorities()两个函数返回的就是两个集合,只有集合中的字符串对应的算法才会注入到genericScheduler ,从而被调用。而这里字符串和真实算法function的映射关系,分别记录在两个全局map:
fitPredicateMap 和priorityFunctionMap中,defaults.go中 调用的RegisterFitPredicate、RegisterMandatoryFitPredicate等许多方法均会将算法名和算法方法的映射记录到map中。
这里注意到,并不是所有的算法都会登记到集合中的,这里PodFitsPorts、PodFitsHostPorts、PodFitsResources等算法只是记录到map中,并没有登记到set中,但是也被调用了,这是因为这些算法都属于GeneralPredicates算法,在GeneralPredicates算法中被调用。而代码中下文我们会看到在default provider 中登记了GeneralPredicates算法
总结下来就是:要将predicate算法或prioirity算法的映射关系注册到全局map中,然后将算法名登记到provider中,再将provider登记到全局map中,在启动scheduler时指定provider的name,就可以使用相应的provider名下登记的算法来构造genericScheduler。
如何增加算法
上文中提及的plugins.go中, 还提供了一些额外的方法,比如:InsertPredicateKeyToAlgoProvider方法,可以将某个算法登记到指定的provider中。
因此,我们只要在init时将自定义的算法先注册到全局map中:
func init() {
factory.RegisterFitPredicate("PodFitsNeteaseResources", predicates.PodFitsNeteaseResources))
}
然后在defaults/defaults.go 的init方法尾部,调用InsertPredicateKeyToAlgoProvider将带有自定义算法的名字的set加入default provider即可:
factory.InsertPredicateKeyToAlgoProvider(factory.DefaultProvider, sets.NewString("PodFitsNeteaseResources"))
上述是一个比较规范的注册方式,也有投机取巧的方式,比如在default provider 的func defaultPredicates() 方法尾部增加一行:
factory.RegisterFitPredicate("PodFitsNeteaseResources", predicates.PodFitsNeteaseResources))
本文转自SegmentFault-
kube-scheduler的代码逻辑和二次开发