这年头,如果你不会点儿R或者Python,你都不好意思说你是混数据圈的。
在你向一些大神请教的时候,他可能也会推荐你学习这两个高级编程语言,然后顺便在推荐你了解一下SQL以及Math。如果讲究点的,可能还会传授你一些Spark、AWS/云计算的经验。
嗯!差不多就这些了~
当前主流数据科学领域用的工具就是这些了。
但是,如果你想成为一个数据科学“英雄”,仅仅掌握一些主流的东西是不够的。
今天就给你推荐几个好用到爆的小工具~~
Linux
Linux名字应该是如雷贯耳了吧!但很多数据科学家对它的命令行并不熟悉。Bash脚本是计算机科学中最基本的工具,并且数据科学中很大一部分需要编程,因此这项技能至关重要。
![47e06162c637092c0aa99f12d1e08497bb547b30]()
我的Linux启动小企鹅
几乎可以肯定的是,你的代码会在linux上开发和部署,使用命令行完成一些工作是非常酷的。与数据科学一样,Python也无法独立于环境工作,并且你必须通过一些命令行界面来处理包、框架管理、环境变量、访问路径($PATH)等等。
Git
Git听名字,你也应该不陌生。大多数数据科学家对git似懂非懂。由于数据科学定义模糊,很多人都不遵循良好的软件开发实践。例如,有人甚至很长一段时间都不知道单元测试。
![963e6ee86d80f0d4bd3e66fee0776b50cdc0aaf7]()
当你在团队中编码时,你就会知道git是很重要的。如果团队成员提交的代码发生冲突,你得知道如何处理。或者你需要挑选部分代码修复bug、更新……将代码提交到开源或私有的repo(如Github)时,你也可以使用Coveralls之类的东西进行代码测试,并且还有其他框架帮助你在提交时方便地将代码部署到生产中。
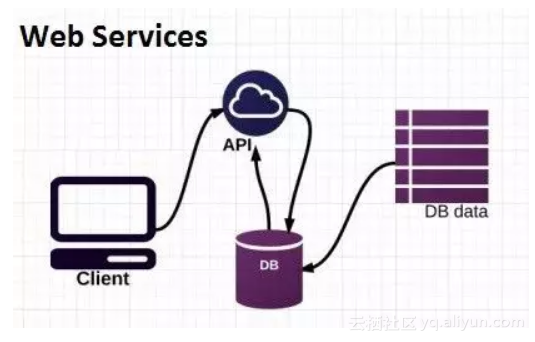
REST APIs
现在,你已经训练好了一个模型——然后该怎么办?没有人想看你的Jupyter notebook或者某种蹩脚的交互式shell脚本。此外,除非你在共享环境中进行训练,否则你的模型只能自己使用。仅仅拥有模型是不够的,而这正是大多数据科学家遇到困难的地方。
![8968cfd35057b45200bc2df62069ff2952606adf]()
要从模型中获得实际的预测结果,最好通过标准API调用或开发可用的应用程序。像Amazon SageMaker这样的服务已经得到普及,因为它可以让你的模型和可用程序无缝衔接。
如果你功力深厚,当然你也可以使用Python中的Flask框架自己构建一个。
![8bda4845e05a7a6139dc899c1a101d1ea4b73133]()
此外,在后端有许多Python包可进行API调用,因此了解API是什么以及如何在开发中使用API,这会让你有点儿与众不同。
Docker & Kubernetes
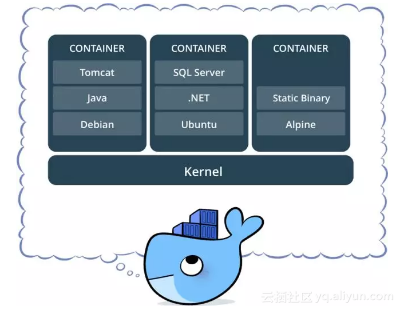
这两个工具棒极了。docker允许用户拥有一个生产就绪(production ready)的应用环境,而无需为每个在其上运行的单个服务集中配置生产服务器。与需要安装完整操作系统的虚拟机不同,docker容器在与主机相同的内核上运行,并且轻量得多。
![b2768d9c56590e2816c3660bcc6f5f56b327e270]()
想象一下像Python的venv这样的docker容器,有更多功能。 更高级的机器学习库(如Google的Tensorflow)需要特定的配置,而这些配置很难在某些主机上进行故障排除。因此,docker经常与Tensorflow一起使用,以确保用于模型训练的环境是开发就绪(development-ready)的。
![b372dc8762b374d03e7ee70c114690d2b0381df0]()
容器化且可扩展的应用程序
随着市场趋向于更多的微型服务和容器化应用,docker因其强大的功能越来越受欢迎。Docker不仅适用于训练模型,也适用于部署。将模型视作服务,你就可以将它们容器化,以便它们具有运行所需的环境,然后可以与应用程序的其他服务无缝交互。这样,你的模型具有可扩展性同时也具有了便携性。
![97618805fde96263e33b6777344ba38ada8402c9]()
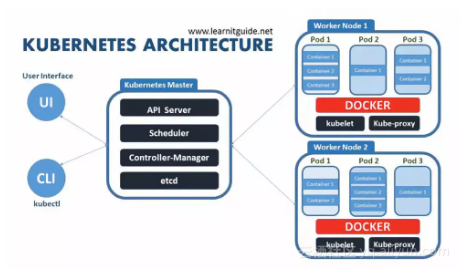
Kubernetes(K8s)是一个在多主机上进行规模管理和部署容器化服务的平台。本质上,这意味着您可以轻松地通过跨水平可扩展集群,管理和部署docker容器。
![73186321536f75f1e5797461bcffc511f645955b]()
由于谷歌正在使用Kubernetes来管理他们的Tensorflow容器(还有其他东西),他们进一步开发了Kubeflow,一个在Kubernetes上用于训练和部署模型的开源工作流。容器化的开发和生产正不断与机器学习和数据科学相结合,我相信这些技能对于2019年的数据科学家来说将是重要的。
![e954b9398336824234e557449ed9724c1ca7720b]()
Apache Airflow
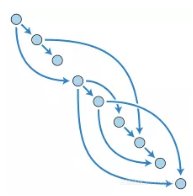
Airflow平台虽然很小众,但是却很酷。Airflow是一个Python平台,可以使用有向无环图(DAG)程序化地创建、调度和监控工作流。
![e502fa940373198983f8876ef6ffea277fddbdd5]()
DAG(有向无环图)
这基本上只是意味着你可以随时根据需要轻松地设置Python或bash脚本。与可自定义但不太方便的定时任务(cron job)相比,Airflow能让你在用户友好的GUI中控制调度作业。
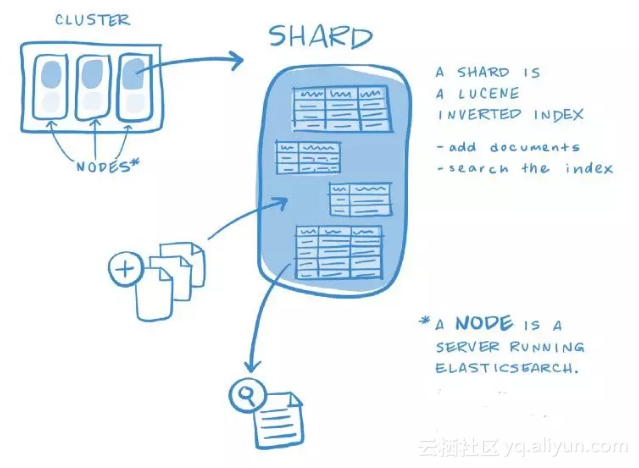
Elasticsearch
Elasticsearch同样比较小众。这个有点特别,取决于你是否有搜索/ NLP用例。但是,我可以告诉你在财富50强公司工作,我们有大量的搜索用例,这是我们堆栈中最重要的框架之一。与在Python中从头开始构建某些东西相反,Elastic通过Python客户端便捷地提供了所需的一切。
![73d6419b05a6eff7cf04e0f8ac2f154ecb31610d]()
Elasticsearch让你可以轻松地以容错和可扩展的方式索引和搜索文档。你拥有的数据越多,启动的节点就越多,查询执行的速度就越快。Elastic使用Okapi BM25算法,该算法在功能上非常类似于TF-IDF(词频-逆向文件频率,Elastic以前使用的算法)。它有一大堆花里胡哨的东西,甚至支持多语言分析器等定制插件。
![d74649cef726052de5723448238a9265307b453d]()
Elasticsearch index
由于它本质上是比较查询到的与索引中文档的相似性,因此它也可用于比较文档间的相似性。强烈建议先查看一下Elasticsearch是否提供了所需的一切,而不是直接从scikit-learn包中导入TF-IDF使用。
Homebrew(mac系统
Ubuntu有apt-get,Redhat有yum,而Windows 10甚至有OneGet 。这些包管理器通过命令行界面(CLI)安装、管理依赖项,并自动更新路径($PATH)。虽然mac系统不能开箱即用,但Homebrew可以通过终端命令轻易安装。
![7cb2b45a6b34429e8fec64670c04c5d9771e6b5c]()
弥补了OS系统无包管理的缺陷
不能在本地安装Apache Spark的小伙伴。可以访问官网,下载后解压,并将spark-shell命令添加到$ PATH中,或者在终端输入brew install apache-spark(注意:要想使用spark,你需要安装scala和java)。
原文发布时间为:2018-11-21
本文作者:蒋晔、小七、蒋宝尚
本文来自云栖社区合作伙伴“CDA数据分析师”,了解相关信息可以关注“CDA数据分析师”。