前言
前端时间利用ES开发一个"附近地理位置+其它信息"查询搜索的功能(据了解,Redis和PostgreSQL也能实现同样的功能),实践中遇到了不少的问题,所以通过这篇文章记录下踩填坑过程。
es with docker
个人喜好,一般使用中间件都喜欢用Docker运行较新版本的,用docker pull elasticsearch命令拉下来的版本一般不会是最新的,所以可以从这里找到最新版本的拉取命令,稍加改造后我需要的是这样的:docker run --name elasticsearch -e "ES_JAVA_OPTS=-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 docker.elastic.co/elasticsearch/elasticsearch-oss:6.3.2
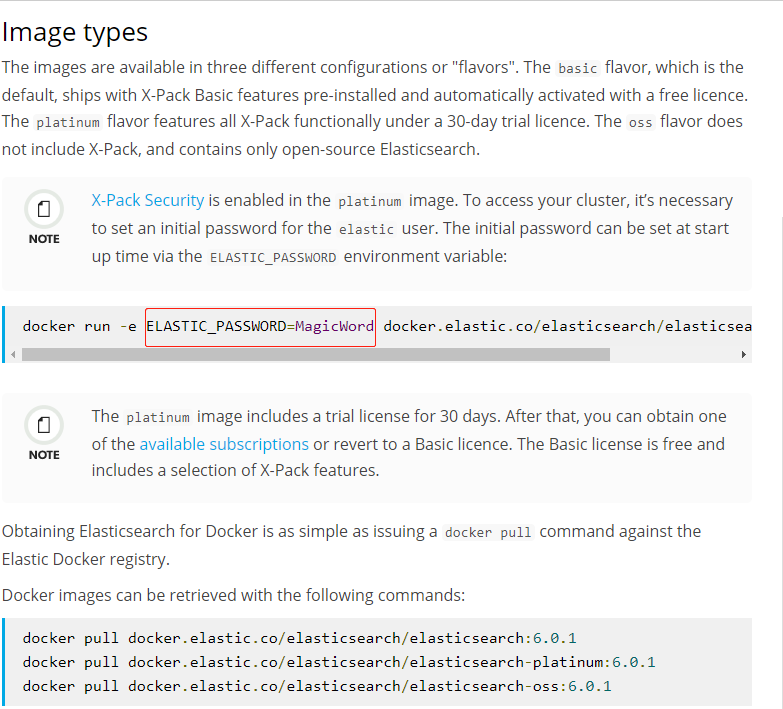
注意到这里指定的镜像是elasticsearch-oss:6.3.2,这个-oss表示不包括X-Pack的ES镜像,这也是在6.0+版本后划分的,剩下两种类型是basic(默认)和platinum,具体官方说明可以看下图。
![Elasticsearch Docker Image Types]()
Elasticsearch Docker Image Types
如果启动失败,使用命令docker logs elasticsearch查看日志即可,-f参数用于监听,其中一种启动错误是要求你修改vm.max_map_count这个系统环境参数,Linux可参考命令sysctl -w vm.max_map_count=262144设置即可(其它系统在文末官方参考链接中有更详细介绍)。
create mapping
这部分是重点,之前遇到的坑就是type mapping这块。
- "_id is not configurable"
es2.0+版本中,_id是可以配置的,网上也有一堆告诉你怎么设置,但es6.3.2中创建mapping并指定_id配置的时候,es返回错误中就出现了上面那句,在社区可以找到了这个Discuss。高版本中的_id是不能配置了,一般来说,在添加Document的时候,如果只指定Index和Document Type,那么es会随机给这个_id分配一个值,但如果添加的时候指定这个_id值,那么ES就不会再随机分配这个值。不过注意,即使你指定的_id是一个数值,但在实际保存和返回中都是字符串类型;
- "Mapping with Index not_analyzed is not working"
这个问题在Github上也有相关的Issues,我在这里先还原下当初创建mapping的配置:
{
"properties": {
# 当初的想法是指定shopId这个字段不要分析,然后keyword字段要进行分析
"shopId": {
"type": "integer",
"index": "not_analyzed"
},
"location": {
"type": "geo_point"
},
"keyword":{
"type": "text",
"index": "analyzed",
"analyzer": "ik_max_word"
}
}
}
创建完上述mapping后访问http://localhost:9200/{index}/{type}/_mapping,但返回结果(如下)和上面指定的mapping并不相同:
{
"{index}": {
"mappings": {
"{type}": {
"properties": {
"shopId": {
"type": "integer"
},
"location": {
"type": "geo_point"
},
"keyword": {
"type": "text",
"analyzer": "ik_max_word"
},
}
}
}
}
}
之后还是在官方文档中找到答案,发现确实有两点值得记录一下。
第一点:es5.0之后,为字符串新增了keyword类型,而之前的版本中只有text类型,通过index属性判断是否需要分词(默认分词)。es5.0之后使用keyword type代替index这个属性,所以指定"type": "text"就是分词,指定"type": "keyword"就是不分词;
第二点:不需要为type为数字类型integer、long,日期类型date、布尔类型boolean等指定"index": "not_analyzed"属性(而且在高版本es中这也是错误的语法,index只能指定为"index": true | false,false意味着不可查询),因为这些类型就是不分词的,如果要分词请修改为text类型。
ik analysis
IK是国内用得比较多的中文分词器,与ES安装集成也比较简单,首先进入dockerdocker exec -it elasticsearch bash,然后用命令./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.2/elasticsearch-analysis-ik-6.3.2.zip安装即可(需对应es版本),安装完使用docker restart elasticsearch重启服务即可。IK支持两种分词方式,ik_smart和ik_max_word,前者分词粒度没有后者细,可以针对实际情况进行选择。
head plugin
elasticsearch-head插件也是测试的时候用得比较多的插件,以前用ES2的时候是借助plugin脚本安装的,但这种方式在ES5.0之后被废弃了,然后作者也推荐了好几种方式,可以借助npm运行该服务,或者用docker运行服务,不过为了简单起见我最后选的是Chrome extension这种方式。
参考链接
Install Elasticsearch with Docker
Mapping
Text datatype
Keyword datatype
how-to-not-analyze-in-elasticsearch
elasticsearch-analysis-ik
elasticsearch-head