一、Hadoop文件系统HDFS
-
构建单节点的伪分布式HDFS
-
构建4个节点的HDFS分布式系统
- nameNode
- secondnameNode
- datanode1
- datanode2
其中 datanode2动态节点,在HDFS系统运行时,==动态加入==。
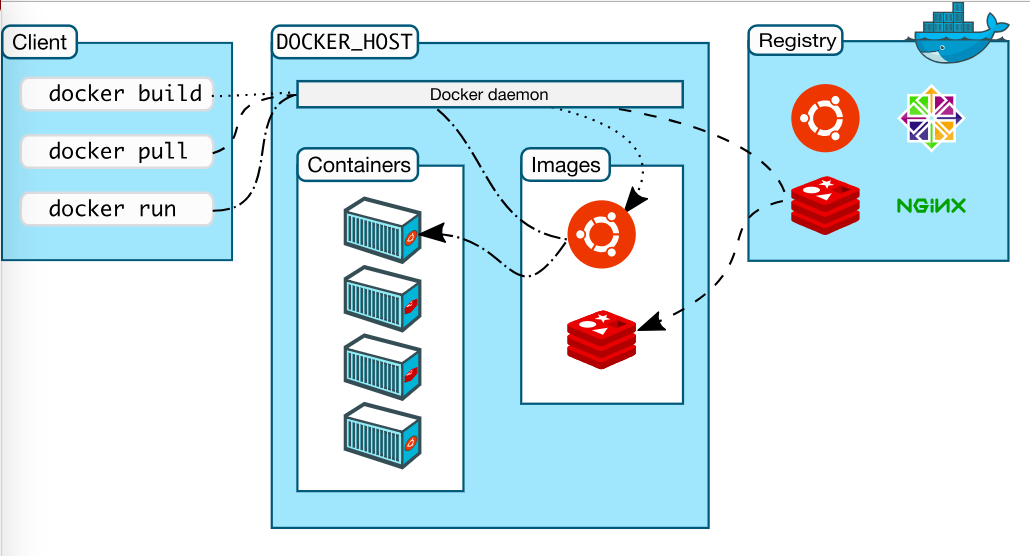
二、Mac docker环境
通常在mac os上搭建开发环境是非常方便的,两个docker软件:
- Docker for mac
- Docker toolBox
如果你要在本机做开发,配置IDE环境,想要连接到Docker中,推荐使用Docker toolBOX。docker for mac 版本没有docker0网桥。
在mac系统上又运行了一层虚拟机,只有这层虚拟机可以直连到docker网络。强烈建议开发不要再找docker for mac连接docker0的方法了,这个坑已经浪费了很多人的时间。
如果mac系统版本在10.13 以上,还会遇到创建网卡失败的问题,要注意关闭系统安全特性设置。
sudo spctl --master-disable
感谢作者@
仰望神的光,《macOS 10.13 安装Virtualbox失败》,https://blog.csdn.net/u013247765/article/details/78176079
docker 常用命令的总结,会在文章末尾附录。
三、Docker 镜像
构建Hadoop镜像文件。构建docker image有2中方式,(1)docker commit保存现有环境生成image(2)Dockfile,docker build生成image。通过实验,构建Dockerfile的速度很快,而且支持环境变量,同步文件等方式。开始可以用commit不断调整,最后确定Dockfile内容。而且Dockerfile文件结构清晰,方便查看。
FROM ubuntu:16.04
MAINTAINER wsn
RUN apt-get update
RUN apt-get install -y openjdk-8-jdk
RUN apt-get install -y vim
RUN apt install -y net-tools
RUN apt install -y iputils-ping
RUN apt-get install -y openssh-server
RUN mkdir /var/run/sshd
RUN echo 'root:root' |chpasswd
RUN sed -ri 's/^PermitRootLogin\s+.*/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed -ri 's/UsePAM yes/#UsePAM yes/g' /etc/ssh/sshd_config
RUN sed -ri 's/# StrictHostKeyChecking ask/StrictHostKeyChecking no/' /etc/ssh/ssh_config
RUN mkdir /root/.ssh
RUN ssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa
RUN cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64
ENV JRE_HOME /usr/lib/jvm/java-8-openjdk-amd64/jre
ENV PATH /opt/hadoop-2.6.5/bin:/opt/hadoop-2.6.5/sbin:/usr/lib/jvm/java-8-openjdk-amd64/bin:$PATH
ENV CLASSPATH ./:/usr/lib/jvm/java-8-openjdk-amd64/lib:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib
ADD hadoop-2.6.5.tar.gz /opt/
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
Dockerfile 解析
- ubuntu 16.04 为基础镜像,开始开发之前一定要apt-get update。
- PermitRootLogin、UsePAM、StrictHostKeyChecking 有关SSH的配置。
- ssh-keygen 生成公钥,保存到authorized_keys中。
- 配置JDK,hadoop的环境变量。
- hadoop-2.6.5.tar.gz 保存到与Dockerfile同一个目录,会自动解压到/opt目录下。注意hadoop的环境变量基石/opt/hadoop-2.6.5/bin下。
编译镜像,其中wsn/ubuntu_ssh_java_hadoop是镜像的名字,其中.代表当前目录。
docker bulid -t wsn/ubuntu_ssh_java_hadoop .
四、HDFS 伪分布式
HDFS系统中包括三种角色,namenode主控节点,datanode数据节点,secondenamenode主控节点的热备节点。伪分布式,就是在一台主机上启动3个进程,构建一套分布式系统。
在单节点上配置伪分布式很简单,修改 hadoop-env.sh,core-site.xml,hdfs-site.xml 。
core-site.xml包含2个属性,其中namenode代表节点hostname、域名,换成ip也可以;hadoop.tmp.dir是hadoop工作目录(可以设置docker volumn,实现持久化)。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
启动镜像
docker run --name namenode --rm wsn/ubuntu_ssh_java_hadoop
最后2步:
/opt/hadoop/bin/hadoop namenode -format
/opt/hadoop/sbin/start-hdfs.sh start
查看系统状态,jps会看到3个进程namenode,secondnamenode,datanode。
一些简单hdfs命令,这些命令可以帮助你对hdfs系统的测试。
hdfs dfs -ls /
hdfs dfs -mkdir /test
hdfs dfs -put 1.txt /test
五、Docker特性
(一) 分层
docker系统采用了分层的设计思想,在docker中运行的修改是不会自动保存,你可以调用commit生成新的镜像。或者采用挂载数据卷的方式,将数据和系统分类,实现数据持久化。
刚刚接触Docker对分层的意义了解不深。在构建Dockerfile的时候,每个RUN命令会构建一个层,image按层存储,此时就产生不同的镜像引用了相同的层,节省了存储空间,实现image hub高效存储。
docker挂载文件、文件夹命令。
docker -v 宿主机路径:container路径 image
(二)网络与内嵌DNS
在docker环境中,可以创建一个子网络
docker network create --subnet=172.18.0.0/16 hadoopnet
在第二节中讨论过,我们希望能过访问这个网络,在主机上添加路由信息
sudo route -n add 172.18.0.0/24 192.168.99.100
此时,我们可以创建一台绑定网段、ip的主机了,
docker run -it --name namenode --hostname namenode --network hadoopnet --ip 172.18.0.11 wsn/ubuntu_ssh_java_hadoop
当我们创建一台docker主机,设置了name、ip时,内嵌DNS提供了name和ip的解析,省却了修改hosts文件的麻烦。
(三)免密码登录
此例中,创建Dockerfile文件的时候,就生成了公钥,并写入authorize文件中。结果就是,所有的container的公钥都是一样的,而且写入了authorize文件,所以都实现了免密码登录。其实笔者不希望这样,对于docker的公钥问题留下待解决的问题。
在构建Dockerfile的时候,ssh_config文件StrictHostKeyChecking no,设置在首次ssh登录的时候,不用询问。
The authenticity of host 'namenode (172.18.0.11)' can't be established.
ECDSA key fingerprint is SHA256:4utoWe5uVp79ImYqkPPukjmrGIfvDC5demc1sx8sY9c.
Are you sure you want to continue connecting (yes/no)? yes
(四)启动脚本
docker 容器有一个特性,当没有前台应用的时候,docker自动停止(这个设计有什么优势我还不知道)。
我们在创建dockerfile的时候配置了CMD ,就是系统运行后前台命令。如果run docker的时候,配置了start-hdf.sh 命令,那么就会遇到脚本运行结束docker自动停止。
解决方法,在本地创建一个.sh文件,在docker run 的时候挂载到container中,run 命令设置运行这个docker容器中的sh文件。
/etc/init.d/ssh start
/opt/hadoop-2.6.5/sbin/start-dfs.sh
六、分布式Hadoop环境
在本地建立4个文件目录,namenode、secondnamenode、datanode、datanode2。
(一) namenode文件夹:
- hadoop
- namenode.sh #启动脚本
- run.sh #ssh start start-dfs.sh
- data #挂载到/opt/tmp
hadoop文件夹是容器内/opt/hadoop/etc/hadoop的挂载文件
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/tmp</value>
</property>
</configuration>
hdfs-site.xml,全部类型的节点都用这个配置,标注了namenode 和secondnamenode的域名/ip。
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.http.address</name>
<value>namenode:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>secondnamenode:50090</value>
</property>
</configuration>
slaves
secondnamenode
datanode
masters
secondnamenode
namenode.sh
docker run -it --name namenode --hostname namenode --network hadoopnet --ip 172.18.0.11 -d -v $PWD/data:/opt/tmp -v $PWD/hadoop:/opt/hadoop-2.6.5/etc/hadoop -v $PWD/run.sh:/opt/run.sh --rm wsn/ubuntu_ssh_java_hadoop /opt/run.sh
run.sh,如果没有格式化目录,首先格式化目录。```bash``使终端有一个前台进程。
#!/bin/bash
if [ ! -d "/opt/tmp/dfs" ];then
hadoop namenode -format
else
echo "already format"
fi
/etc/init.d/ssh start
/opt/hadoop-2.6.5/sbin/start-dfs.sh
bash
(二)secondnamenode,datanode 启动命令
docker run --name secondnamenode --hostname secondnamenode --network hadoopnet --ip 172.18.0.12 -d -v $PWD/data:/opt/tmp -v $PWD/hadoop:/opt/hadoop-2.6.5/etc/hadoop --rm wsn/ubuntu_ssh_java_hadoop
docker run --name datanode1 --hostname datanode1 --network hadoopnet --ip 172.18.0.13 -d -v $PWD/data:/opt/tmp -v $PWD/hadoop:/opt/hadoop-2.6.5/etc/hadoop --rm wsn/ubuntu_ssh_java_hadoop
这个两个节点已经写到namenode的slaves文件,secondnamenode在配置文件hdfs-site.xml设置为secondary。当namenode启动start-hdf.sh时会通过ssh,启动secondnamenode上的secondname进程和datanode进程。datanode容器会启动datanode进程,此时可以通过web界面查看了。
(三)datanode2 启动
docker run --name datanode2 --hostname datanode2 --network hadoopnet --ip 172.18.0.14 -d -v $PWD/data:/opt/tmp -v $PWD/hadoop:/opt/hadoop-2.6.5/etc/hadoop --rm wsn/ubuntu_ssh_java_hadoop
datanode2没有添加到namenode的slaves文件中,但是在datanode2的hdfs文件中配置了namenode和secondnamenode,所以datanode可以自动添加到HDFS系统中。
/opt/etc/hadoop/sbin/hadoop-daemon.sh start datanode
web,http://172.18.0.11:50070/dfshealth.html#tab-datanode
七、总结
Google 三篇论文,分别介绍了分布式文件系统、MapReduce、宽表。对应开源系统Hadoop中的HDFS、MapReduce、HBase。通过对HDFS系统的配置,了解了主从结构的网络,应该用什么样的配置文件。对HBase系统也有一些了解,在HBase中对master节点采用了zookeeper进行控制。
- 大数据对系统结构搭建非常重视,实际工作中运维难度大。
- Spark 是目前主流的大数据架构。
附录 docker 常用命令
![image]()
image
案例一:启动nginx,绑定80到连接本地的8080端口
docker run -p 8080:80 -d nginx
-d:后台运行,
案例二: 启动ubuntu
docker run ubuntu echo hello world
自动下载ubuntu ,并启动
案例三:替换docker 中文件
docker cp index.html containerId://usr/share/nginx/html
案例四:保存docker
docker commit -m "message" containerId
保存为一个新的image
案例五:dockerfile 文件创建docker image
FROM ubuntu
MAINTAINER wsn
RUN apt-get update
RUN apt-get install -y nginx
copy index.html /var/www/html
ENTRYPOINT ["/usr/sbin/nginx","-g","daemon off;"]
EXPOSE 80
当前目录下运行命令 docker build -t wsn/ubuntu-nginx .
wsn/ubuntu-nginx 作为容器的名字
案例六:docker分层
案例七:volumn 持久化
docker run -p 80:80 -d -v $PWD/html:/usr/share/nginx/html nginx
$PWD/html 挂载虚拟机的/usr/share/nginx/html目录下
案例八:进入docker虚拟机shell,-it交互方法
docker exec -it nginx /bin/bash