本文默认读者已经对Docker有一定了解,且清楚使用Docker进行部署的优势。
1.安装Docker(Mac)
官网:https://docs.docker.com/docker-for-mac/install/
1.1 下载 Docker for Mac
地址:https://store.docker.com/editions/community/docker-ce-desktop-mac
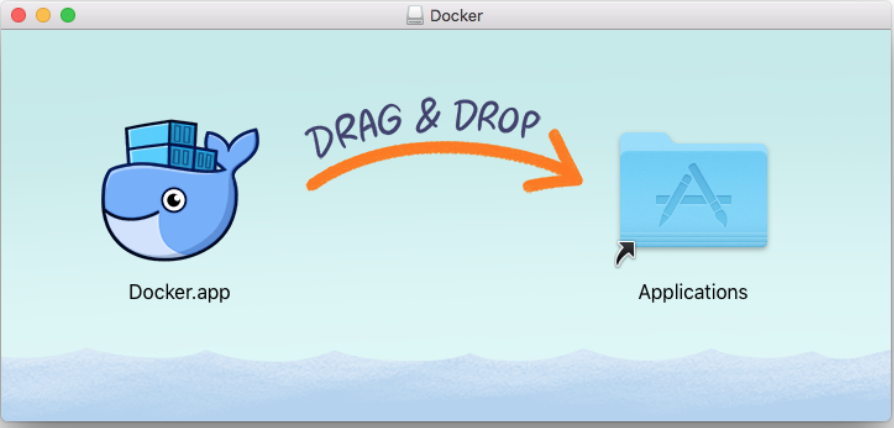
1.2 下载完成以后,双击打开文件Docker.dmg
1.3双击Docker.app启动
Mac顶部状态栏会出现鲸鱼图标
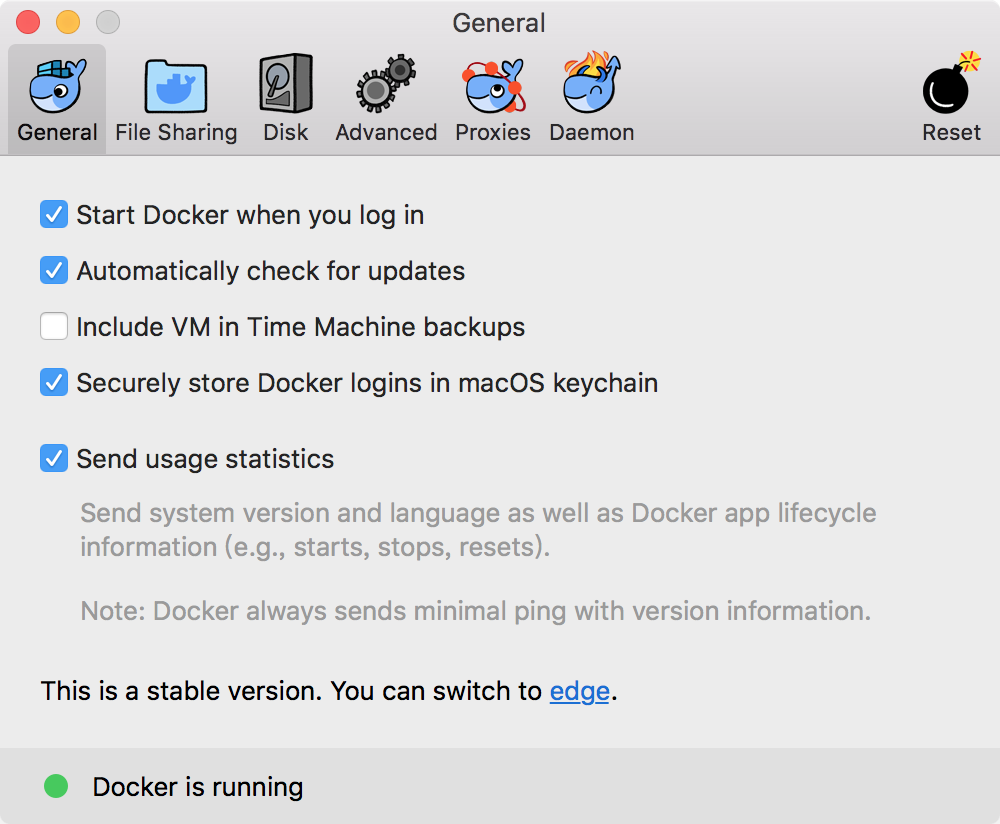
1.4点击鲸鱼图标可以进行设置
1.5 Check versions
$ docker --version
Docker version 18.03, build c97c6d6
$ docker-compose --version
docker-compose version 1.21.2, build 8dd22a9
$ docker-machine --version
docker-machine version 0.14.0, build 9ba6da9
1.6 Hello Word
1.6.1 打开命令行终端,通过运行简单的Docker映像测试您的安装工作。
$ docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
ca4f61b1923c: Pull complete
Digest: sha256:ca0eeb6fb05351dfc8759c20733c91def84cb8007aa89a5bf606bc8b315b9fc7
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
...
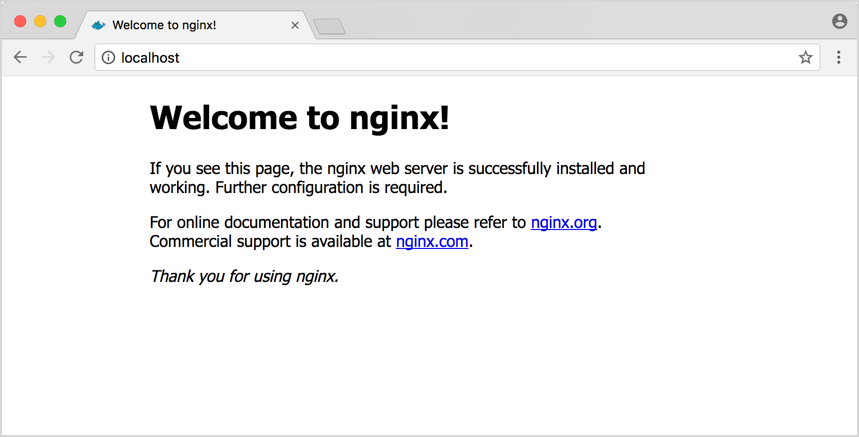
1.6.2 启动Dockerized web server
$ docker run -d -p 80:80 --name webserver nginx
1.6.3 打开浏览器,输入http://localhost/
常用命令:
docker ps 查看正在运行的容器
docker stop停止正在运行的容器
docker start启动容器
docker ps -a查看终止状态的容器
docker rm -f webserver命令来移除正在运行的容器
docker list 列出本地镜像
docker rmi 删除的镜像
2.使用Docker安装Nginx
Docker Store 地址:https://store.docker.com/images/nginx
其实在上文中Hello World即已经安装了nginx。
2.1 拉取 image
docker pull nginx
3.2 创建Nginx容器
docker run --name mynginx -p 80:80 -v /Users/gaoguangchao/Work/opt/local/nginx/logs:/var/log/nginx -v /Users/gaoguangchao/Work/opt/local/nginx/conf.d:/etc/nginx/conf.d -v /Users/gaoguangchao/Work/opt/local/nginx/nginx.conf:/etc/nginx/nginx.conf:ro -v /Users/gaoguangchao/Work/opt/local/nginx/html:/etc/nginx/html -d nginx
-d 以守护进程运行(运行在后台)
--name nginx 容器名称;
-p 80:80 端口映射
-v 配置挂载路径 宿主机路径:容器内的路径
关于挂载
-
- 为了能直接修改配置文件,以实现对Nginx的定制化,需要进行Docker的相关目录挂在宿主机上。
-
- 需要挂载的目录/文件:
/etc/nginx/conf.d /etc/nginx/nginx.conf /etc/nginx/html
-
- 有一点尤其需要注意,当挂载的为文件而非目录时,需要注意以下两点:
- a. 挂载文件命令: -v 宿主机路径:容器内的路径:ro
- b.宿主机需要先创建后文件,无法自动创建,反之将报错
nginx.conf 示例
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
upstream demo {
server 127.0.0.1:8080;
}
server {
listen 80;
server_name request_log;
location / {
root html;
#index index.html index.htm;
proxy_connect_timeout 3;
proxy_send_timeout 30;
proxy_read_timeout 30;
proxy_pass http://demo;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}
2.3 浏览器访问
在调试过程中往往不会很顺利,这里的技巧是通过阅读error.log中的异常日志进行
2.4 配置反向代理
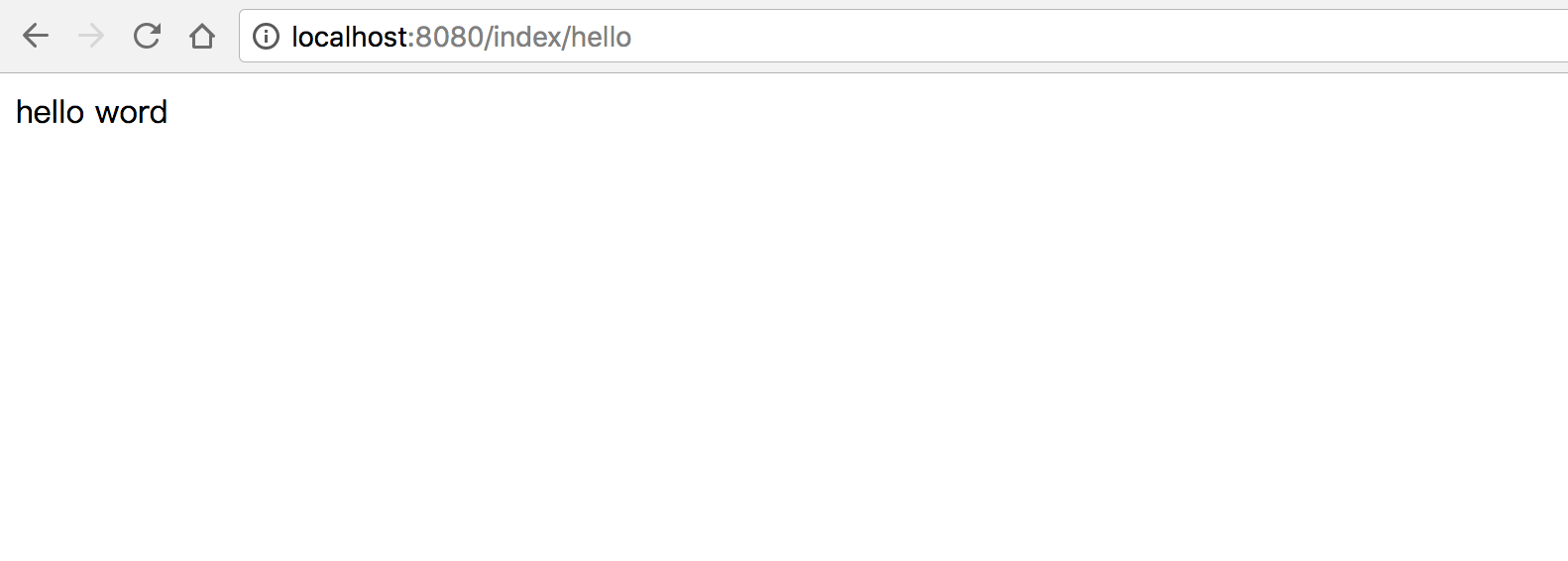
此处是本机启动一个 SpringBoot web server,端口为:8080,浏览器访问:http://localhost:8080/index/hello
按照上节中nginx.conf示例中的配置方式,增加upstream、server、proxy_pass相关配置,对80端口进行监听,重启nginx容器。
docker restart mynginx
浏览器访问:http://localhost/index/hello,可以看到正常访问。
3.使用Docker安装Openresty
Openresty是在Nginx基础上做了大量的定制扩展,其安装过程和Nginx基本一致。
Docker Store 地址:https://store.docker.com/community/images/openresty/openresty
3.1 拉取 image
docker pull openresty/openresty
3.2 创建Openresty容器
docker run -d --name="openresty" -p 80:80 -v /Users/gaoguangchao/Work/opt/local/openresty/nginx.conf:/usr/local/openresty/nginx/conf/nginx.conf:ro -v /Users/gaoguangchao/Work/opt/local/openresty/logs:/usr/local/openresty/nginx/logs -v /Users/gaoguangchao/Work/opt/local/openresty/conf.d:/etc/nginx/conf.d -v /Users/gaoguangchao/Work/opt/local/openresty/html:/etc/nginx/html openresty/openresty
注意事项和安装Nginx基本一致,在此不再赘述。
4.使用Docker安装Kafka
Docker Store 地址:https://store.docker.com/community/images/spotify/kafka
4.1 拉取 image
docker pull spotify/kafka
4.2 创建Kafka容器
运行命令:
docker run -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=`127.0.0.1` --env ADVERTISED_PORT=9092 spotify/kafka
2181为zookeeper端口,9092为kafka端口
输出启动日志:
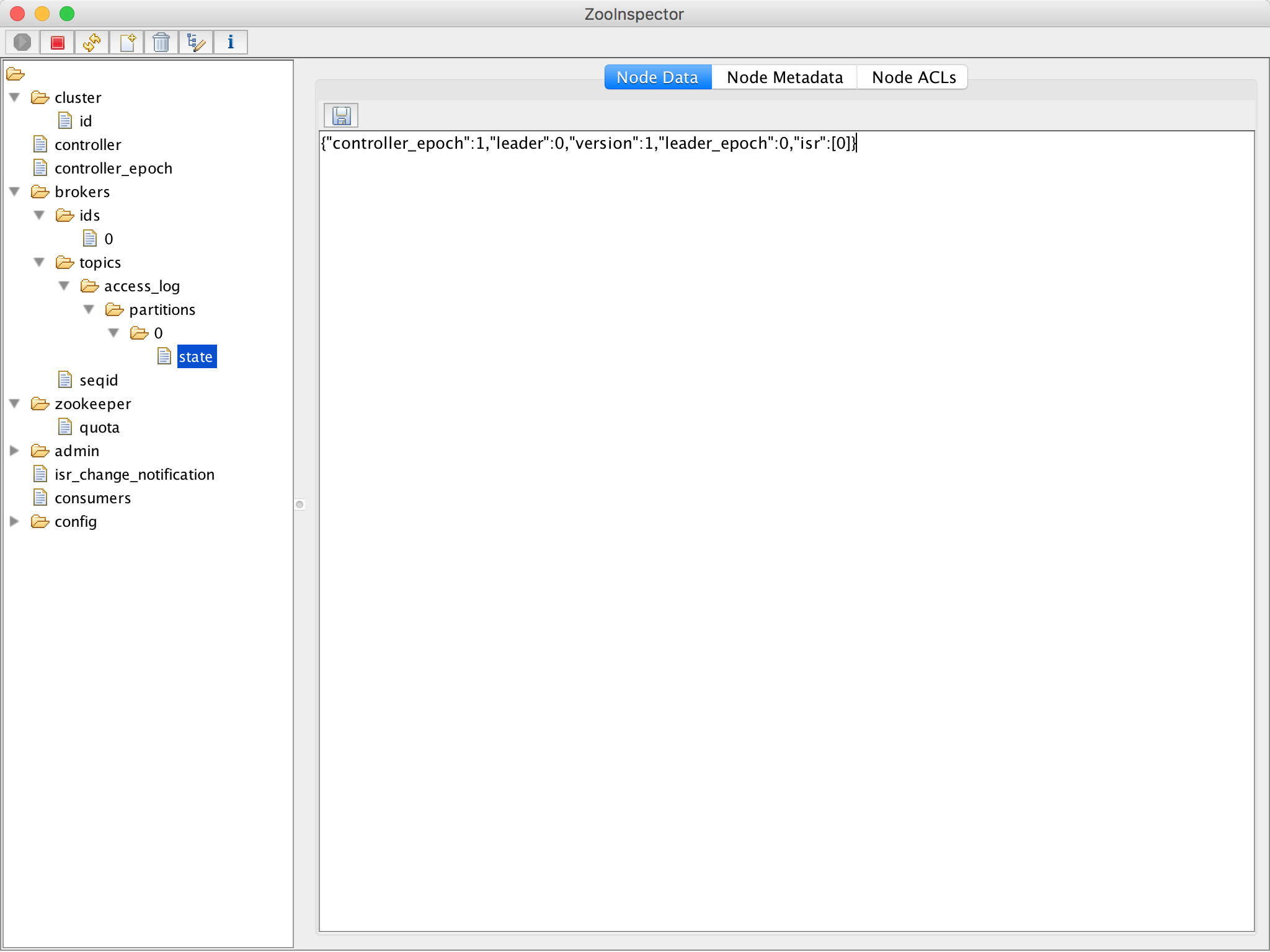
4.3 Check zookeeper是否启动
可以使用一些可视化客户端连接端口,进行监控,如zooInspector、Idea Zookeeper Plugin等
5.使用Docker安装Kafka Manager
Kafka Manager 是Yahoo开源的kafka监控和配置的web系统,可以进行kafka的日常监控和配置的动态修改。
Docker Store 地址:https://store.docker.com/community/images/sheepkiller/kafka-manager
5.1 拉取 image
docker pull sheepkiller/kafka-manager
5.2 创建Kafka Manager容器
运行命令:
docker run -it --rm -p 9000:9000 -e ZK_HOSTS="127.0.0.1:2181" -e APPLICATION_SECRET=letmein sheepkiller/kafka-manager
2181为上节中部署的zookeeper端口,9000为kafka-manager的web端口
输出启动日志:
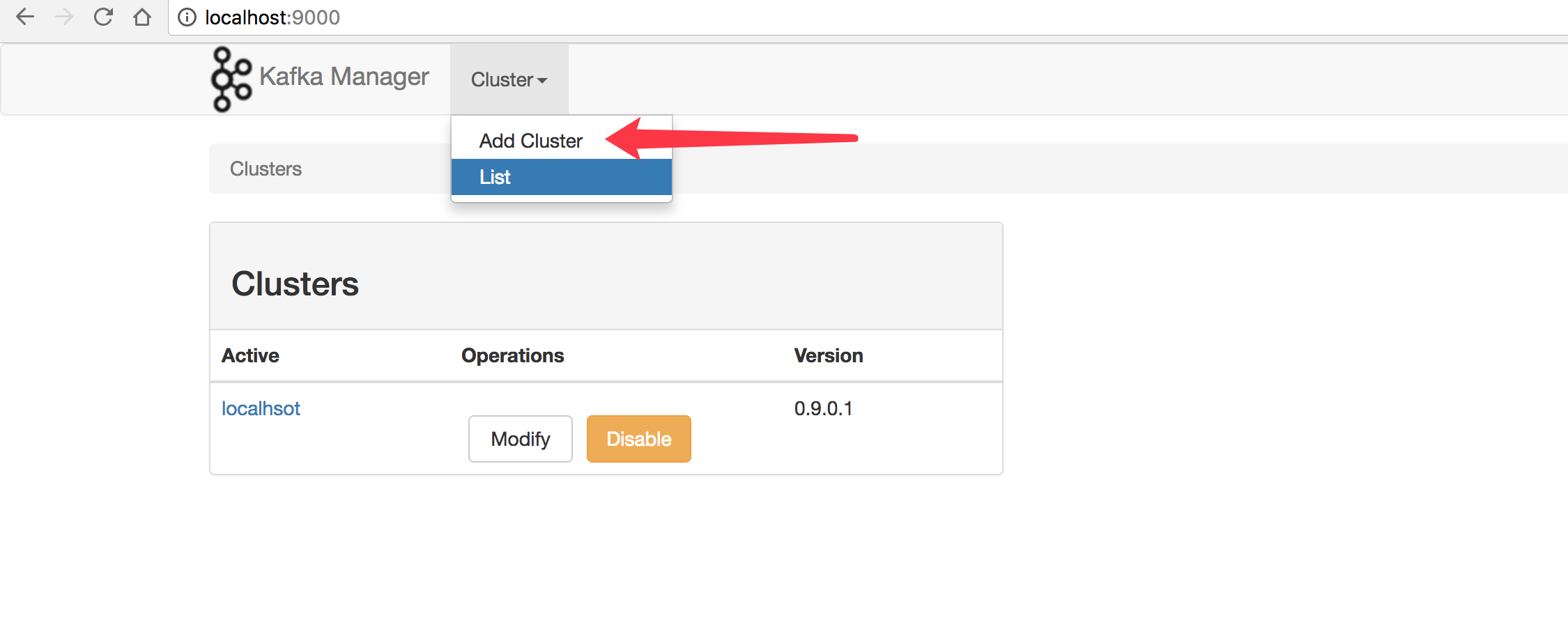
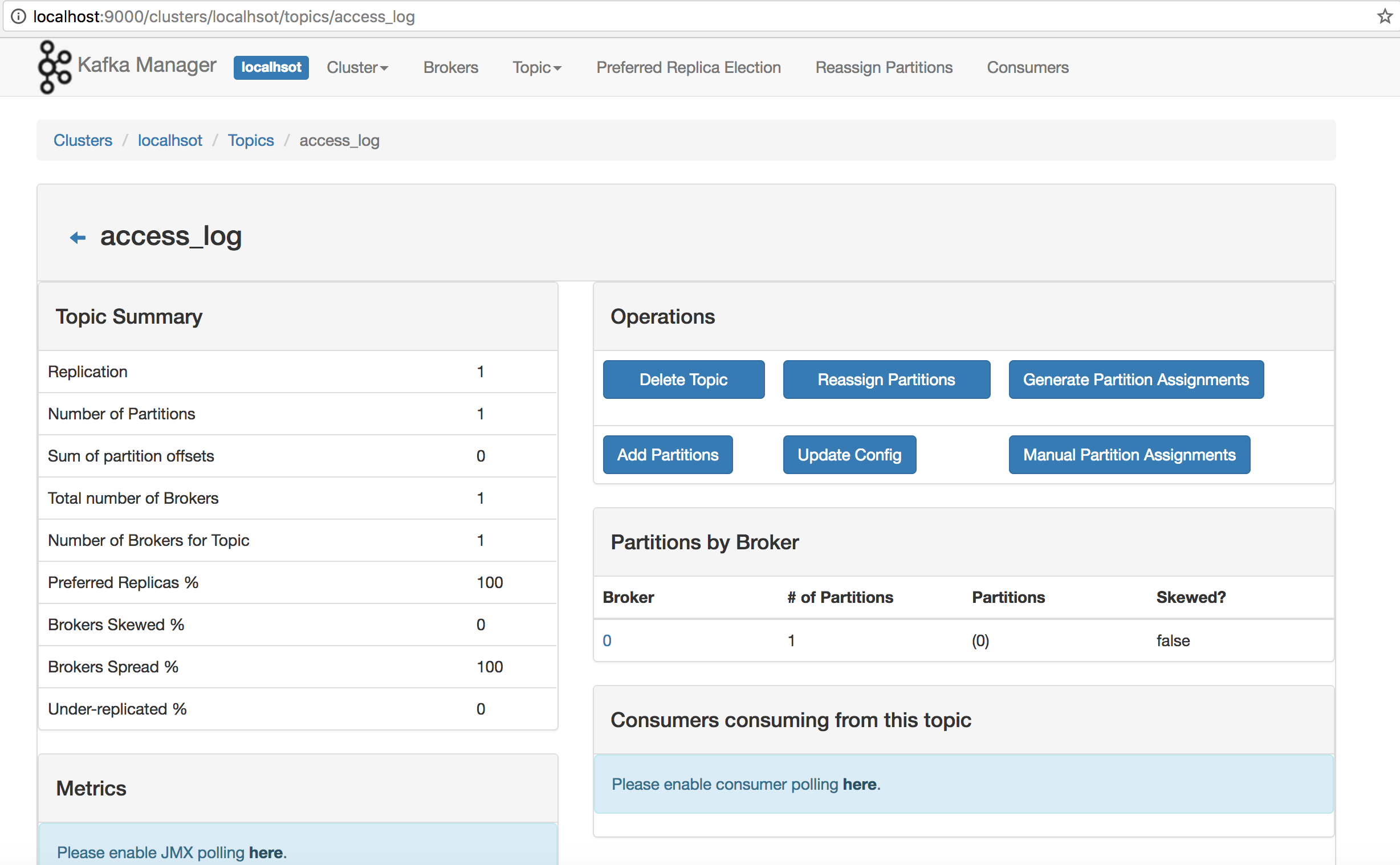
5.3 访问Kafka Manager
浏览器访问:http://localhost:9000
按照页面上的操作按钮进行kafka集群的注册,具体使用方式再次不做详细介绍。
注册配置后的界面:
6.Kafka消息生产与消费
6.1创建maven项目
** pom依赖**
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>${org.slf4j-version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-1.2-api</artifactId>
<version>${log4j2-version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j2-version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j2-version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j2-version}</version>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.1.0</version>
</dependency>
</dependencies>
6.2 增加log4j2配置
配置log4j2为能正常打印debug日志,方便进行异常排查 (重要)
在resources目录下增加log4j2.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="WARN">
<Properties>
<Property name="pattern_layout">%d %-5p (%F:%L) - %m%n</Property>
<Property name="LOG_HOME">/logs</Property>
</Properties>
<appenders>
<Console name="CONSOLE" target="SYSTEM_OUT">
<PatternLayout pattern="%d %-5p (%F:%L) - %m%n"/>
</Console>
</appenders>
<loggers>
<root level="debug" includeLocation="true">
<appender-ref ref="CONSOLE"/>
</root>
</loggers>
</configuration>
关于log4j2的使用,有兴趣的可以了解:Log4j1升级Log4j2实战
6.3 创建生产者示例
package com.moko.kafka;
import org.apache.kafka.clients.producer.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
public class MokoProducer extends Thread {
private static final Logger LOGGER = LoggerFactory.getLogger(MokoProducer.class);
private final KafkaProducer<String, String> producer;
private final String topic;
private final boolean isAsync;
public MokoProducer(String topic, boolean isAsync) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "78c4f4a0f989:9092");//broker 集群地址
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "MokoProducer");//自定义客户端id
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//key 序列号方式
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//value 序列号方式
this.producer = new KafkaProducer<String, String>(properties);
this.topic = topic;
this.isAsync = isAsync;
}
@Override
public void run() {
int seq = 0;
while (true) {
String msg = "Msg: " + seq;
if (isAsync) {//异步
producer.send(new ProducerRecord<String, String>(this.topic, msg));
} else {//同步
producer.send(new ProducerRecord<String, String>(this.topic, msg),
new MsgProducerCallback(msg));
}
seq++;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 消息发送后的回调函数
*/
class MsgProducerCallback implements Callback {
private final String msg;
public MsgProducerCallback(String msg) {
this.msg = msg;
}
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (recordMetadata != null) {
LOGGER.info(msg + " be sended to partition no : " + recordMetadata.partition());
} else {
LOGGER.info("recordMetadata is null");
}
if (e != null)
e.printStackTrace();
}
}
public static void main(String args[]) {
new MokoProducer("access-log", false).start();//开始发送消息
}
}
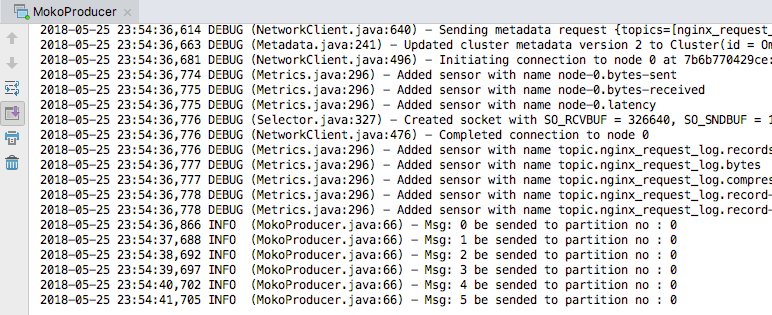
简单运行后,打印日志如下:
6.4 创建消费者示例
package com.moko.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Properties;
public class MokoCustomer {
private static final Logger LOGGER = LoggerFactory.getLogger(MokoCustomer.class);
public static void main(String args[]) throws Exception {
String topicName = "access-log";
Properties props = new Properties();
KafkaConsumer<String, String> consumer = getKafkaConsumer(props);
consumer.subscribe(Arrays.asList(topicName));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
if (!records.isEmpty()) {
LOGGER.info("=========================");
}
for (ConsumerRecord<String, String> record : records) {
LOGGER.info(record.value());
}
}
}
private static KafkaConsumer<String, String> getKafkaConsumer(Properties props) {
props.put("bootstrap.servers", "172.18.153.41:9092");
props.put("group.id", "group-1");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
return new KafkaConsumer<String, String>(props);
}
}
简单运行后,打印日志如下:
6.5 注意事项
由于是在本机使用Docker搭建的环境,遇到最多的问题就是网络问题,如host等的配置,但是只要意识到这点,通过注意分析各种异常日志,便不难排查解决。
7.结语
致此,本文就介绍完了如何使用Docker搭建 Nginx/Openresty - Kafka - kafkaManager。
后续将会继续介绍如何使用Docker搭建一套 nginx+lua+kafka实现的日志收集的教程,敬请期待。
欢迎关注 高广超的简书博客 与 收藏文章 !
欢迎关注 头条号:互联网技术栈 !
个人介绍:
高广超:多年一线互联网研发与架构设计经验,擅长设计与落地高可用、高性能、可扩展的互联网架构。
本文首发在 高广超的简书博客 转载请注明!