原文:
SQLServer中重建聚集索引之后会影响到非聚集索引的索引碎片吗
本文出处:http://www.cnblogs.com/wy123/p/7650215.html
(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误进行修正或补充,无他)
上午(20171011)看到qq群里发了一个云栖大会的链接,点进去看了一下sqlserver的专场,刚好是提问环节
有人问了一个问题,原话记不清楚了,
大概的意思(他自己认为)就是说:“SQLServer中重建聚集索引之后会影响非聚集索引的碎片情况,也要顺带重建非聚集索引”
我想大概是他自己认为“重建聚集索引之后会影响到非聚集索引的索引碎片”
提问者跟专家交流这个观点,一开始提问之后还撤了几句堆表RID,聚集表key值啥的。
专家一开始说这两者没有关系(重建聚集索引之后不会影响到非聚集索引的索引碎片),后面被提问之后可能是有点紧张,改口说没注意过这个问题。
首先抛出结论:对于聚集索引表,重建聚集索引之后不会影响到非聚集索引的索引碎片,重建聚集索引跟非聚集索引碎片之间的没有关系,完全不搭嘎的。
这些问题,其实尝试自己测试一下不就清楚了么?
聚集索引重建之后,对非聚集索引是否有影响
首先,暂且先不扯聚集表堆表啥的了,直接说聚集表,
非聚集索引在叶级直接存储的是聚集索引的key值,在重建聚集索引(或者重组)前后,非聚集索引存储的对应的key值是不变的
重建聚集索引之后,数据的屋里存储位置可能会发生变化,这是会影响到聚集索引的物理存储和碎片情况
但是对于非聚集索引来说,非聚集索引存储的对应的聚集索引的key值是不变的,
那非聚集索引的碎片跟聚集索引的重建与否有个毛的关系。
正如我手机里记录了某个人的电话号码,我只要拨通这个电话就能找到他,我管他是去北京上班还是去南京出差了,跟他在人具体哪里(重建聚集索引,物理位置变化)有毛关系。
这些问题如果不确定的话,测试一下就出来结果了啊,我觉得没有任何疑问的。
测试,测试表TestFragment中,Id1字段类型为uniqueidentifier,建立聚集索引,
利用uniqueidentifier的随机性,大批量写入数据之后其碎片变得很大
相反,Id2字段类型INT,以递增的值写入数据,大批量写入数据之后其索引碎片会很小
然后重现Id1上的索引,观察Id2上的索引碎片会不会因为Id1上的索引重建而发生变化
create table TestFragment
(
Id1 uniqueidentifier,
Id2 int,
OtherCol2 varchar(50)
)
go
create unique clustered index IDX_Id1 on TestFragment(Id1);
go
create unique index IDX_Id2 on TestFragment(Id2);
go
begin tran
declare @i int = 0
while @i<1000000
begin
insert into TestFragment values(NEWID(),@i+1,NEWID());
set @i = @i+1
end
commit
go
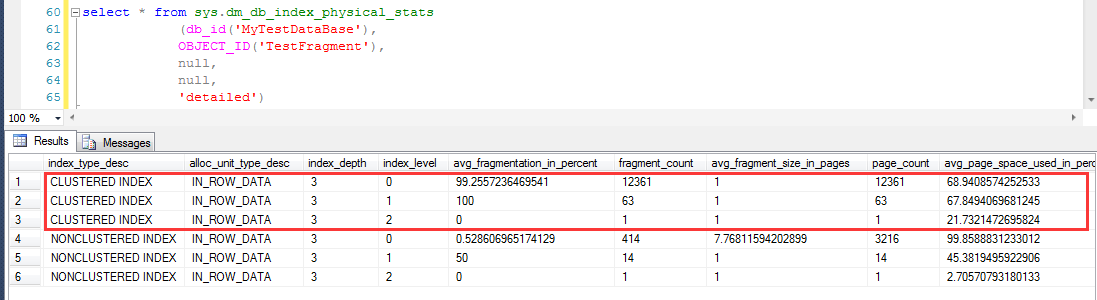
写入100W数据之后观察两个索引上的碎片,
对于聚集索引(Id1上的索引IDX_Id1):
很明显,聚集索引(因为是uniqueidentifier类型的字段),
其avg_fragmentation_in_percent很高(99.2557236469541),同时avg_page_space_used_in_percent较低(68.9408574252533)
对于非聚集索引(Id1上的索引IDX_Id2):
Id2索引因为是递增的,其avg_fragmentation_in_percent很低(0.528606965174129),也就是说碎片程度很低
![]()
这里姑且不管聚集索引与非聚集索引的碎片程度,这里重点关注“重建聚集索引之后是否会对非聚集索引碎片情况产生影响”
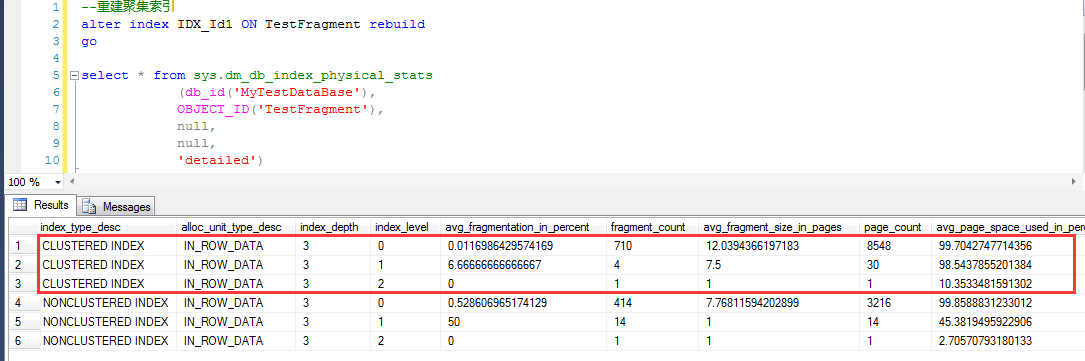
这里重建聚集索引之后,重新观察索引碎片情况,看截图sys.dm_db_index_physical_stats的查询结果
可以很清楚地发现,重建聚集索引之后,聚集索引本身的碎片发生了很大的变化,碎片基本完全消除(avg_fragmentation_in_percent0.0116986429574169),
但是非聚集索引的碎片情况并没有发生任何一点变化。
![]()
从理论上也不难理解:
聚集索引和非聚集索引是两个完全独立的物理存储结构(当然也可以说是逻辑存储结构)
其唯一的联系就是非聚集索引B树叶子节点会存储聚集索引的Key值
其存储的聚集索引的key值不是其物理位置,聚集索引或者说数据本身的位置变化并不会因为key值的变化
因此说重建还是重组聚集索引不会影响到非聚集索引的碎片情况
堆表的碎片消除
对于堆表的索引碎片消除,也是可以通过alter table xxx rebuild重建的,
当然也有一种很挫的做法就不想提了(fix heap fragmentation by creating and dropping a clustered index.)
记住这是一种很挫的做法,可能是SQL Server 2008之前的版本中,alter table xxx rebuild语法被支持之前的无奈之举,
这里暂不表述这种做法。
对于堆表,alter table xxx rebuild可以通过重建表来消除碎片,但其功能不限于次,还会重建堆表上的非聚集索引
测试示例
create table TestHeapFragment
(
Id1 uniqueidentifier,
Id2 int,
OtherCol2 varchar(50)
)
go
create unique index IDX_Id1 on TestHeapFragment(Id1);
go
create unique index IDX_Id3 on TestHeapFragment(OtherCol2);
go
begin tran
declare @i int = 0
while @i<1000000
begin
insert into TestHeapFragment values(NEWID(),@i+1,NEWID());
set @i = @i+1
end
commit
go
通过alter table xxx rebuild对堆表重建,发现非聚集索引也会因为堆表的重建而发生索引重建。
![]()
If you think you can use ALTER TABLE … REBUILD to fix heap fragmentation, you can, but it causes all the nonclustered indexes to be rebuilt as the heap record locations obviously change.
暂时不清楚alter table xxx rebuild的具体实现过程,但是从各种表现来看,他在重建表的过程中确实也重建了非聚集索引。
但是“重建表的过程中确实也重建了非聚集索引”可以认为是“使得非聚集索引变得更加好,而不是变坏”,
这里要说明的是alter table xxx rebuild重建堆表不会对对表上的非聚集索引产生副作用
强调一点,
对于非聚集表,alter table xxx rebuild会重建所有的非聚集索引
对于聚集表,alter table xxx rebuild只会重建聚集索引,但是不会重建非聚集索引
说实话,提问者所说的“重建聚集索引之后会影响到非聚集索引碎片”这个观点我也是第一次听说,
如果真的了解索引的话,应该知道这两者(重建聚集索引与非聚集索引碎片)之间没有必然的关系,
对于莫名其妙的结论,到底是道听途说还是真有其事,为什么不自己动手试一试?
参考:
https://www.red-gate.com/simple-talk/sql/database-administration/sql-server-heaps-and-their-fragmentation/
https://www.sqlskills.com/blogs/paul/a-sql-server-dba-myth-a-day-2930-fixing-heap-fragmentation/