概述:
- 面向过程:根据业务逻辑从上到下写垒代码
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
面向过程编程最易被初学者接受,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,即:将之前实现的代码块复制到现需功能处。随着时间的推移,开始使用了函数式编程,增强代码的重用性和可读性。今天学习新的编程方式:面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)
创建类和对象
面向对象编程是一种编程方式,此编程方式的落地需要使用 “类” 和 “对象” 来实现,所以,面向对象编程其实就是对 “类” 和 “对象” 的使用。
类就是一个模板,模板里可以包含多个函数,函数里实现一些功能。
对象则是根据模板创建的实例,通过实例对象可以执行类中的函数。
1 class people:
2 def wave(self):
3 print('Hello World!')
4
5 obj = people()
class为关键字,表示创建一个people的类 ,def wave为创建类中的函数,obj则是class创建的实例对象。
ps:类中的函数第一个参数必须是self, 类中定义的函数叫做 “方法”。
class people:
def jon(self):
print('say Hello!')
def tom(self,name):
print('say hello %s'%name)
obj = people()
obj.jon() #执行jon方法
obj.tom('Jerry') #执行tom方法
通过上面代码演示,你会认为使用函数式编程和面向对象编程方式来执行一个“方法”时函数要比面向对象简便
- 面向对象:【创建对象】【通过对象执行方法】
- 函数编程:【执行函数】
观察上述对比答案则是肯定的,然后并非绝对,场景的不同适合其的编程方式也不同。
总结:函数式的应用场景 --> 各个函数之间是独立且无共用的数据。
面向对象的三大特性
面向对象的三大特性是指:封装、继承和多态。
一、封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
所以,在使用面向对象的封装特性时,需要:
第一步:将内容封装到某处
# 创建类
class people:
def __init__(self,name,age):
self.name = name
self.age = age
#根据类people创建对象
#自动执行people类的__init__方法
p1 = people('xixi',21)
p2 = people('hehe',23)
上面代码__init__()称为构造方法,根据类创建对象时自动执行
将xixi,21分别封装到people的name和age属性中
self是一个形式参数,当执行p1 = people('xixi',21)时,self等于p1
同理p2 = people('hehe',23)时,self等于p2
所以,内容实际被封装到了对象,p1,p2中,每个对象都有name和age属性,都封装到对象p1,2中
第二步:从某处调用被封装的内容
调用被封装的内容时,有两种情况:
1、通过对象直接调用被封装的内容
对象 p1 和 p2 在存储到内存中,根据保存格式可以如此调用被封装的内容:对象.属性名
![]()
![]()
1 class people:
2 def __init__(self,name,age):
3 self.name = name
4 self.age = age
5 #根据类people创建对象
6 #自动执行people类的__init__方法
7 p1 = people('xixi',21)
8 print(p1.name) #直接调用p1对象的name属性
9 print(p1.age) #p1的age属性
10 p2 = people('hehe',23)
11 print(p2.name)
12 print(p2.age)
View Code
2、通过self间接调用被封装的内容
执行类中的方法时,需要通过self间接调用被封装的内容:
![]()
![]()
1 class people:
2 def __init__(self,name,age):
3 self.name = name
4 self.age = age
5
6 def attr(self):
7 print(self.name)
8 print(self.age)
9 #根据类people创建对象
10 #自动执行people类的__init__方法
11 p1 = people('xixi',21)
12 p1.attr()
13 p2 = people('hehe',23)
14 p2.attr()
View Code
Python默认会将p1传给self参数,即:p1.attr(p1),所以,此时方法内部的 self = p1,即:self.name 是 xixi ;self.age 是 12,同理,p2也是如此.
综上所述,对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过对象直接或者self间接获取被封装的内容。
练习:在终端输出如下信息
小明,10岁,男,上山去砍柴
小明,10岁,男,开车去东北
小明,10岁,男,最爱大保健
老李,90岁,男,上山去砍柴
老李,90岁,男,开车去东北
老李,90岁,男,最爱大保健
![]()
![]()
def kanchai(name, age, gender):
print "%s,%s岁,%s,上山去砍柴" %(name, age, gender)
def qudongbei(name, age, gender):
print "%s,%s岁,%s,开车去东北" %(name, age, gender)
def dabaojian(name, age, gender):
print "%s,%s岁,%s,最爱大保健" %(name, age, gender)
kanchai('小明', 10, '男')
qudongbei('小明', 10, '男')
dabaojian('小明', 10, '男')
kanchai('老李', 90, '男')
qudongbei('老李', 90, '男')
dabaojian('老李', 90, '男')
函数式编程
![]()
![]()
class Foo:
def __init__(self, name, age ,gender):
self.name = name
self.age = age
self.gender = gender
def kanchai(self):
print "%s,%s岁,%s,上山去砍柴" %(self.name, self.age, self.gender)
def qudongbei(self):
print "%s,%s岁,%s,开车去东北" %(self.name, self.age, self.gender)
def dabaojian(self):
print "%s,%s岁,%s,最爱大保健" %(self.name, self.age, self.gender)
xiaoming = Foo('小明', 10, '男')
xiaoming.kanchai()
xiaoming.qudongbei()
xiaoming.dabaojian()
laoli = Foo('老李', 90, '男')
laoli.kanchai()
laoli.qudongbei()
laoli.dabaojian()
面向对象编程
二、继承
继承: 面向对象中的继承和现实生活中的继承相同,即:子可以继承父的内容。
如:
男孩:talk,sleep,walk,eat
女孩:talk,sleep,walk,eat
![]()
![]()
class man:
def talk(self):
print '喵喵叫'
def eat(self):
# do something
def walk(self):
# do something
def slepp(self):
# do something
class woman:
def talk(self):
print '喵喵叫'
def eat(self):
# do something
def walk(self):
# do something
def slepp(self):
# do something
伪代码
上述代码不难看出,talk,sleep,walk,eat是男和女都具有的功能,而我们却分别的男和nv的类中编写了两次。如果使用 继承 的思想,如下实现:
people:talk,sleep,walk,eat
man:喝酒
woman:穿裙子
![]()
![]()
class people:
def eat(self):
# do something
def walk(self):
# do something
def eat(self):
# do something
def sleep(self):
# do something
# 在类后面括号中写入另外一个类名,表示当前类继承另外一个类
class man(people):
def 喝酒(self):
print '喝酒'
# 在类后面括号中写入另外一个类名,表示当前类继承另外一个类
class woman(people):
def 穿裙子(self):
print '穿裙子'
伪代码
![]()
![]()
class people:
def eat(self):
print "%s 吃 " %self.name
def walk(self):
print "%s 走 " %self.name
def sleep(self):
print "%s 睡 " %self.name
def talk(self):
print "%s 说 " %self.name
class man(people):
def __init__(self, name):
self.name = name
def drink(self):
print '喝酒'
class woman(Animal):
def __init__(self, name):
self.name = name
def wear(self):
print '穿裙子'
# ######### 执行 #########
p1 = man('yu')
p1.eat()
p2 = man('li')
p2.drink()
p3 = Dog('liu')
p3.eat()
实例演示
所以,对于面向对象的继承来说,其实就是将多个类共有的方法提取到父类中,子类仅需继承父类而不必一一实现每个方法。
注:除了子类和父类的称谓,你可能看到过 派生类 和 基类 ,他们与子类和父类只是叫法不同而已。
那么问题又来了,多继承呢?
- 是否可以继承多个类
- 如果继承的多个类每个类中都定了相同的函数,那么那一个会被使用呢?
1、Python的类可以继承多个类,Java和C#中则只能继承一个类
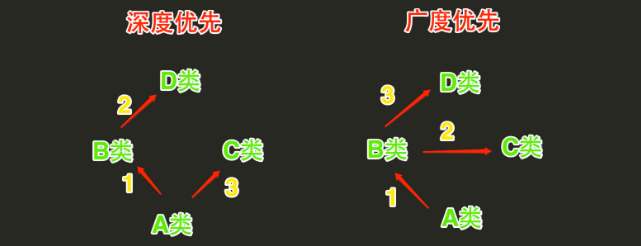
2、Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先
![]()
- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了跟多的功能,也是之后推荐的写法,从写法上区分的话,如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类。
经典类:
class p1:
pass
class p2(p1):
pass
新式类:
class p1(object):
pass
class p2(p1):
pass
![]()
![]()
class D:
def bar(self):
print 'D.bar'
class C(D):
def bar(self):
print 'C.bar'
class B(D):
def bar(self):
print 'B.bar'
class A(B, C):
def bar(self):
print 'A.bar'
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> D --> C
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar()
经典类多继承
![]()
![]()
class D(object):
def bar(self):
print 'D.bar'
class C(D):
def bar(self):
print 'C.bar'
class B(D):
def bar(self):
print 'B.bar'
class A(B, C):
def bar(self):
print 'A.bar'
a = A()
# 执行bar方法时
# 首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
# 所以,查找顺序:A --> B --> C --> D
# 在上述查找bar方法的过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
a.bar()
新式类继承
经典类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去D类中找,如果D类中么有,则继续去C类中找,如果还是未找到,则报错
新式类:首先去A类中查找,如果A类中没有,则继续去B类中找,如果B类中么有,则继续去C类中找,如果C类中么有,则继续去D类中找,如果还是未找到,则报错
注意:在上述查找过程中,一旦找到,则寻找过程立即中断,便不会再继续找了
三、多态
Pyhon不支持Java和C#这一类强类型语言中多态的写法,但是原生多态,其Python崇尚“鸭子类型”。
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
我们并不关心对象是什么类型,到底是不是鸭子,只关心行为。
鸭子类型在动态语言中经常使用,非常灵活,使得python不想java那样专门去弄一大堆的设计模式。
![]()
![]()
class F1:
pass
class S1(F1):
def show(self):
print 'S1.show'
class S2(F1):
def show(self):
print 'S2.show'
def Func(obj):
print obj.show()
s1_obj = S1()
Func(s1_obj)
s2_obj = S2()
Func(s2_obj)
python'鸭子类型'
总结
以上就是本节对于面向对象初级知识的介绍,总结如下:
- 面向对象是一种编程方式,此编程方式的实现是基于对 类 和 对象 的使用
- 类 是一个模板,模板中包装了多个“函数”供使用
- 对象,根据模板创建的实例(即:对象),实例用于调用被包装在类中的函数
- 面向对象三大特性:封装、继承和多态.
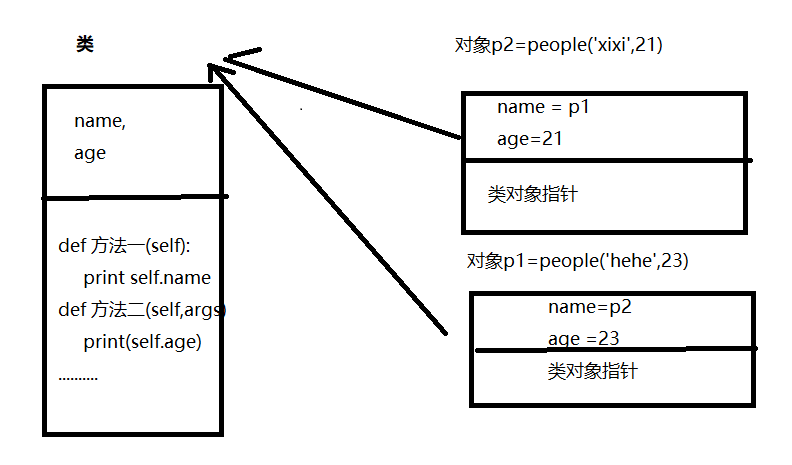
类和对象在内存中是如何保存?
类以及类中的方法在内存中只有一份,而根据类创建的每一个对象都在内存中需要存一份,大致如下图:
![]()
如上图所示,根据类创建对象时,对象中除了封装 name 和 age 的值之外,还会保存一个类对象指针,该值指向当前对象的类。
当通过p1执行 【方法一】 时,过程如下:
- 根据当前对象中的 类对象指针 找到类中的方法
- 将对象 p1当作参数传给 方法的第一个参数 self