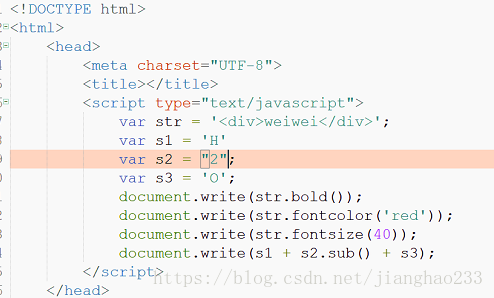
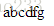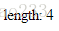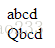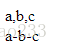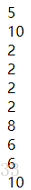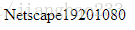1、js的String对象
** 创建String对象
*** var str = "abc";
** 方法和属性(文档)
*** 属性 length:字符串的长度
*** 方法
(1)与html相关的方法
- bold():加粗
- fontcolor(): 设置字符串的颜色
- fontsize(): 设置字体的大小
- link(): 将字符串显示成超链接
**** str4.link("hello.html")
- sub() sup(): 下标和上标
![]()
(2)与java相似的方法
- concat(): 连接字符串
** //concat方法
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var str1 = "abc";
var str2 = "dfg";
document.write(str1.concat(str2)); //连接字符串
</script>
</head>
<body>
</body>
</html>
输出:![]()
- charAt():返回指定指定位置的字符串
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var str3 = "abcdefg";
document.write(str3.charAt(20)); //字符位置不存在,返回空字符串
</script>
</head>
<body> </body>
</html>
输出:空
- indexOf(): 返回字符串位置
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var str4 = "poiuyt";
document.write(str4.indexOf("w")); //字符不存在,返回-1
</script>
</head>
<body> </body>
</html>
输出:![]()
- split():切分字符串,成数组
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var str5 = "a-b-c-d";
var arr1 = str5.split("-");
document.write("length: "+arr1.length);
</script>
</head>
<body> </body>
</html>
输出: ![]()
![]()
- replace() : 替换字符串
* 传递两个参数:
-- 第一个参数是原始字符
-- 要替换成的字符
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var str6 = "abcd";
document.write(str6);
document.write("<br/>");
document.write(str6.replace("a","Q"));
</script>
</head>
<body> </body>
</html>
输出:![]()
- substr()和substring()
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var str7 = "abcdefghuiop";
document.write(str7.substr(5,5)); //从第五位开始,向后截取五个字符
document.write("<br/>");
document.write(str7.substring(3,5));//从第三位开始到第五位结束[3,5)[左闭右开]
</script>
</head>
<body> </body>
</html>
输出:![]()
2、js的Array对象
** 创建数组(三种)
- var arr1 = [1,2,3];
- var arr2 = new Array(3); //长度是3
- var arr3 = new Array(1,2,3); //数组中的元素是1 2 3
- var arr = []; //创建一个空数组
** 属性:length:查看数组的长度
** 方法
- concat方法: 数组的连接
* var arr11 = [1,2,3];
var arr12 = [4,5,6];
document.write(arr11.concat(arr12));
- join():根据指定的字符分割数组
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var arr13 = new Array(3);
arr13[0] = "a";
arr13[1] = "b";
arr13[2] = "c";
document.write(arr13);
document.write("<br/>");
document.write(arr13.join("-"));
</script>
</head>
<body>
</body>
</html>
输出:![]()
- push():向数组末尾添加元素,返回数组的新的长度
** 如果添加的是一个数组,这个时候把数组当做一个整体字符串添加进去
* //push方法
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var arr14 = new Array(3);
arr14[0] = "tom";
arr14[1] = "lucy";
arr14[2] = "jack";
document.write("old array: "+arr14);
document.write("<br/>");
document.write("old length:"+arr14.length);
document.write("<br/>");
document.write("new length: "+arr14.push("zhangsan"));
document.write("<br/>");
document.write("new array: "+arr14);
</script>
</head>
<body>
</body>
</html>
输出:
![]()
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var arr15 = ["aaa","bbb","ccc"];
var arr16 = ["www","qqq"];
document.write("old array:"+arr15);
document.write("<br/>");
document.write("old length:"+arr15.length);
document.write("<br/>");
document.write("new length:"+arr15.push(arr16));
document.write("<br/>");
document.write("new array: "+arr15);
for(var i=0;i<arr15.length;i++) {
alert(arr15[i]);
}
</script>
</head>
<body>
</body>
</html>
输出:
![]()
- pop():表示 删除最后一个元素,返回删除的那个元素
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
var arr17 = ["zhangsan","lisi","wangwu","zhaoliu"];
document.write("old array: "+arr17);
document.write("<br/>");
document.write("return: "+arr17.pop());
document.write("<br/>");
document.write("new array: "+arr17);
</script>
</head>
<body>
</body>
</html>
输出:![]()
- reverse():颠倒数组中的元素的顺序
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>对象</title>
<script>
document.write("<hr/>");
var arr18 = ["zhangsan1","lisi1","zhaoliu1","niuqi1"];
document.write("old array: "+arr18);
document.write("<br/>");
document.write("new array:"+arr18.reverse());
</script>
</head>
<body>
</body>
</html>
输出:
![]()
3、js的Date对象
** 在java里面获取当前时间
Date date = new Date();
//格式化
//toLocaleString()
** js里面获取当前时间
var date = new Date();
//获取当前时间
var date = new Date();
document.write(date);
//转换成习惯的格式
document.write("<hr/>");
document.write(date.toLocaleString());
** 获取当前的年方法
getFullYear():得到当前的年
**** document.write("year: "+date.getFullYear());
** 获取当前的月方法
getMonth():获取当前的月
*** 返回的是 0-11月,如果想要得到准确的值,加1
**** var date1 = date.getMonth()+1;
document.write("month: "+date1);
** 获取当前的星期
getDay():星期,返回的是 (0 ~ 6)
** 外国朋友,把星期日作为一周的第一天,星期日返回的是 0
而星期一到星期六 返回的是 1-6
** document.write("week: "+date.getDay());
** 获取当前的日
getDate():得到当前的天 1-31
** document.write("day: "+date.getDate());
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>对象</title>
<script type="text/javascript">
var date = new Date();
var days = ['周日','周一','周二','周三','周四','周五','周六'];
document.write(days[date.getDay()])
</script>
</head>
<body>
</body>
</html>
输出:![]()
** 获取当前的小时
getHours():获取小时
** document.write("hour: "+date.getHours());
** 获取当前的分钟
getMinutes():分钟
** document.write("minute: "+date.getMinutes());
** 获取当前的秒
getSeconds(): 秒
** document.write("second: "+date.getSeconds());
** 获取毫秒数
getTime()
返回的是1970 1 1 至今的毫秒数
** 应用场景:
*** 使用毫秒数处理缓存的效果(不有缓存)
案例:输出当前年、月、日、时、分、秒(动态变化)
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
<script type="text/javascript">
document
var interval = setInterval("clock()",1000);
function clock(){
var date = new Date();
var div1 = document.getElementById('div1');
div1.innerHTML = formatDate(date);
}
function pause(){
clearInterval(interval);
}
function start(){
interval = setInterval("clock()",1000);
}
function formatDate(date){
var year = date.getFullYear();
var month = change(date.getMonth()+1);
var dd = change(date.getDate());
var hour = change(date.getHours());
var min = change(date.getMinutes());
var second = change(date.getSeconds());
return year + '-' + month + '-' + dd + ' ' + hour + ':' + min + ':' + second;
}
function change(num){
if(num < 10){
return "0" + num;
}
return num;
}
</script>
</head>
<body>
<div id="div1">
sdfas
</div>
<input type="button" value="暂停" onclick="pause()" />
<input type="button" value="开始" onclick="start()" />
</body>
</html>
输出:
![]()
4、js的Math对象
* 数学的运算
** 里面的都是静态方法,使用可以直接使用 Math.方法()
** ceil(x): 向上舍人
** floor(x):向下舍人
** round(x):四舍五入
** random():得到随机数(伪随机数)
- 得到0-9的随机数
Math.random()*10
Math.floor(Math.random()*10));
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>对象</title>
<script type="text/javascript">
var num = 5.0;
for(var i = 0; i < 100; i ++){
document.write(Math.ceil(Math.random()*10));
document.write("<br />")
}
</script>
</head>
<body>
</body>
</html>
输出:
![]()
5、js的全局函数
* 由于不属于任何一个对象,直接写名称使用
** eval() : 执行js代码(如果字符串是一个js代码,使用方法直接执行)
**** var str = "alert('1234');";
//alert(str);
eval(str);
** isNaN():判断当前字符串是否是数字
-- var str2 = "aaaa";
alert(isNaN(str2));
*** 如果是数字,返回false
*** 如果不是数字,返回true
** parseInt():类型转换
** var str3 = "123";
document.write(parseInt(str3)+1);
6、js的bom对象
** bom:broswer object model: 浏览器对象模型
** 包含对象:
*** navigator: 获取客户机的信息(浏览器的信息)
- navigator.appName
- document.write(navigator.appName);
*** screen: 获取屏幕的信息
- document.write(screen.width);
document.write("<br/>");
document.write(screen.height);
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>对象</title>
<script type="text/javascript">
document.write(navigator.appName);
document.write(screen.width) ;
document.write(screen.height) ;
</script>
</head>
<body>
</body>
</html>
输出:
![]()
*** location: 请求url地址
- href属性
**** 获取到请求的url地址
- document.write(location.href);
**** 设置url地址
- 页面上安置一个按钮,按钮上绑定一个事件,当我点击这个按钮,页面可以跳转到另外一个页面
- location.href = "hello.html";
**** <input type="button" value="tiaozhuan" onclick="href1();"/>
- 鼠标点击事件 onclick="js的方法;"
案例:跳转到百度
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>对象</title>
<script type="text/javascript">
function tz(){
location.href = 'http://www.baidu.com';
}
</script>
</head>
<body>
<input type="button" value="跳转" onclick="tz()" />
</body>
</html>
输出:
![]()
![]()
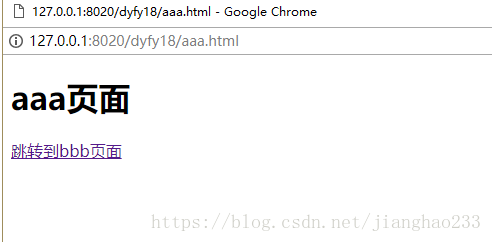
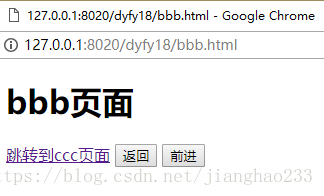
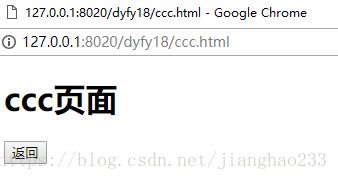
*** history:请求的url的历史记录
- 创建三个页面
1、创建第一个页面 a.html 写一个超链接 到 b.html
2、创建b.html 超链接 到 c.html
3、创建c.html
- 到访问的上一个页面
history.back();
history.go(-1);
- 到访问的下一个页面
history.forward();
history.go(1);
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
<script type="text/javascript">
var ww ;
function openWin(){
ww = open("aaa.html","","width=900,height=700");
}
function closeWin(){
ww.close();
}
</script>
</head>
<body>
<input type="button" value="打开子窗口" onclick="openWin()"/>
<input type="button" value="关闭子窗口" onclick="closeWin()"/>
</body>
</html>
输出:
![]()
![]()
![]()
![]()
**** window(窗口对象)
* 顶层对象(所用的bom对象都是在window里面操作的)
** 方法
- window.alert() : 页面弹出一个框,显示内容
** 简写alert()
- confirm(): 确认框
- var flag = window.confirm("显示的内容");
- open() : 打开一个新的窗口
** open("打开的新窗口的地址url","","窗口特征,比如窗口宽度和高度")
- 创建一个按钮,点击这个按钮,打开一个新的窗口
- window.open("hello.html","","width=200,height=100");
- close(): 关闭窗口(浏览器兼容性比较差)
- window.close();
- 做定时器
** setInterval("js代码",毫秒数) 1秒=1000毫秒
- 表示每三秒,执行一次alert方法
window.setInterval("alert('123');",3000);
** setTimeout("js代码",毫秒数)
- 表示在毫秒数之后执行,但是只会执行一次
- 表示四秒之后执行js代码,只会执行一次
window.setTimeout("alert('abc');",4000);
** clearInterval(): 清除setInterval设置的定时器
var id1 = setInterval("alert('123');",3000);//通过setInterval会有一个返回值
clearInterval(id1);
** clearTimeout() : 清除setTimeout设置的定时器
var id2 = setTimeout("alert('abc');",4000);
clearTimeout(id2);
9、document对象
* 表示整个的文档
** 常用方法
**** write()方法:
(1)向页面输出变量(值)
(2)向页面输出html代码
- var str = "abc";
document.write(str);
document.write("<hr/>");
**** getElementById();
- 通过id得到元素(标签)
- //使用getElementById得到input标签
var input1 = document.getElementById("nameid"); //传递的参数是标签里面的id的值
//得到input里面的value值
alert(input1.name); //标签对象.属性名称
//向input里面设置一个值value
input1.value = "bbbbb";
**** getElementsByName();
- 通过标签的name的属性值得到标签
- 返回的是一个集合(数组)
- //使用getElementsByName得到input标签
var inputs = document.getElementsByName("name1"); //传递的参数是 标签里面的name的值
//alert(inputs.length);
//遍历数组
for(var i=0;i<inputs.length;i++) { //通过遍历数组,得到每个标签里面的具体的值
var input1 = inputs[i]; //每次循环得到input对象,赋值到input1里面
alert(input1.value); //得到每个input标签里面的value值
}
**** getElementsByTagName("标签名称");
- 通过标签名称得到元素
- //演示getElementsByTagName
var inputs1 = document.getElementsByTagName("input"); //传递的参数,是标签名称
//alert(inputs1.length);
//遍历数组,得到每个input标签
for(var m=0;m<inputs1.length;m++) {
//得到每个input标签
var input1 = inputs1[m];
//得到value值
alert(input1.value);
}
**** 注意地方
**** 只有一个标签,这个标签只能使用name获取到,这个使用,使用getElementsByName返回的是一个数组,
但是现在只有一个元素,这个时候不需要遍历,而是可以直接通过数组的下标获取到值
//通过name得到input标签
var inputs2 = document.getElementsByName("name11")[0];
alert(inputs2.value);
var inputss = document.getElementsByTagName("input")[0];
alert(inputss.value);
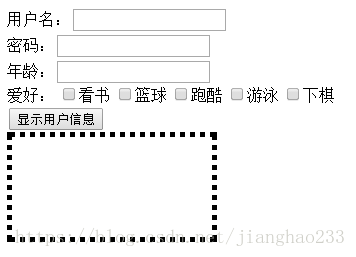
案例:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
用户名:<input type="text" id="username" /><br />
密码:<input type="text" id="password" /><br />
年龄:<input type="text" id="age" /><br />
爱好: <input type="checkbox" name="lover" value="看书" />看书
<input type="checkbox" name="lover" value="篮球" />篮球
<input type="checkbox" name="lover" value="跑酷" />跑酷
<input type="checkbox" name="lover" value="游泳" />游泳
<input type="checkbox" name="lover" value="下棋" />下棋<br />
<input type="button" value="显示用户信息" onclick="showUserInfo()"/>
<div id="showUserInfo" style="width:200px;height: 100px;border:5px dotted #000;">
</div>
</body>
</html>
<script type="text/javascript">
function showUserInfo(){
var username = document.getElementById("username").value;
var password = document.getElementById("password").value;
var age = document.getElementById("age").value;
var lovers = document.getElementsByName("lover");
var loverStr = "";
for(var i = 0; i < lovers.length; i++){
if(lovers[i].checked){
loverStr += lovers[i].value + ",";
}
}
loverStr = loverStr.substring(0,loverStr.length - 1);
var showUi = document.getElementById("showUserInfo");
var str = "用户名:" + username + "<br/>" + "密码:" + password + "<br/>年龄:" + age;
str += "<br>爱好:" + loverStr;
showUi.innerHTML = str;
}
</script>
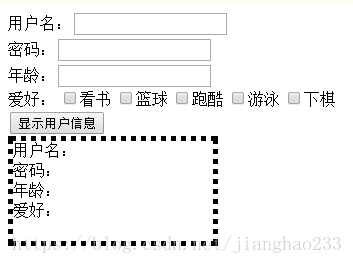
输出:
![]()
![]()
方法二:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
用户名:<input type="text" id="username" /><br />
密码:<input type="text" id="password" /><br />
年龄:<input type="text" id="age" /><br />
爱好: <input type="checkbox" name="lover" value="看书" />看书
<input type="checkbox" name="lover" value="篮球" />篮球
<input type="checkbox" name="lover" value="跑酷" />跑酷
<input type="checkbox" name="lover" value="游泳" />游泳
<input type="checkbox" name="lover" value="下棋" />下棋<br />
<input type="button" value="显示input value属性值信息" onclick="showUserInfo()"/>
<div id="showUserInfo" style="width:200px;height: 100px;border:5px dotted #000;">
</div>
</body>
</html>
<script type="text/javascript">
function showUserInfo(){
var inputs = document.getElementsByTagName("input");
var showUserInfo = document.getElementById("showUserInfo");
for(var i = 0; i < inputs.length; i++){
showUserInfo.innerHTML += inputs[i].value + " ";
}
}
</script>
输出:
![]()
![]()