开篇
当抛弃所有虚的东西之外,我决定好好的把java的基础再过一遍,包括java源码、effective java、阿里的java代码编程规范。希望能够进一步夯实自己的基础,增加自己的底气。
java部分的内容我会着重看看java的集合类和java的concurrent包下的多线程部分,有兴趣的同学可以撸下这部分代码,另外jdk8的源码部分可以去github上面找,已经有人在上面贡献了。
就让我以HashSet做一个开局吧。
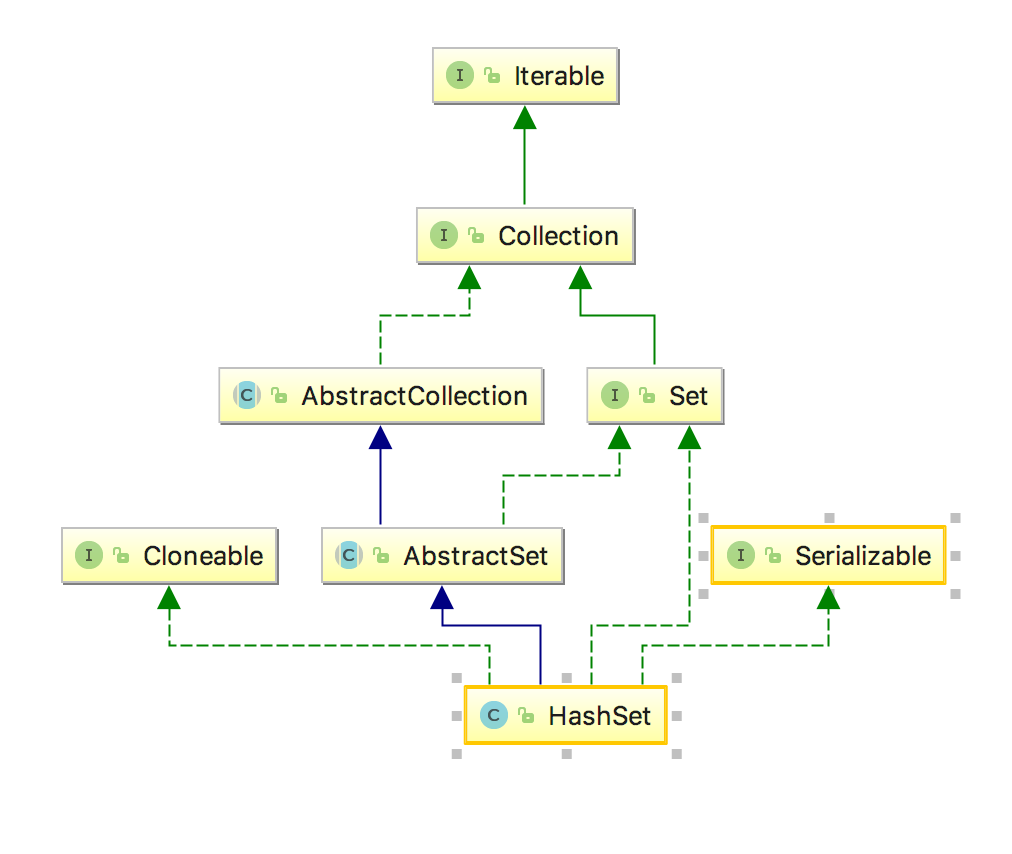
HashSet类图
构造函数
在HashSet内部我们使用HashMap<E,Object> map对象来实际存储HashSet的集合对象,由于HashSet当中保存的只是key而没有value,所以在实际的HashMap当中map的key保存的是HashSet集合当中的值,map的value是固定的一个Object对象,也就是当前的PRESENT对象。
知道了HashSet内部的存储方式是采用HashMap的,那么其实我们后面的增删改查其实操作的就是HashMap对象,所以后面的分析其实就是在分析HashMap的操作。
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
}
HashSet核心方法分析
size()方法
HashSet的size方法直接调用的HashMap的size方法,而HashMap的size方法内部直接范围内部计数变量值size。
public int size() {
return map.size();
}
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int modCount;
int threshold;
final float loadFactor;
public int size() {
return size;
}
isEmpty()方法
HashSet的isEmpty方法直接调用的HashMap的isEmpty方法,而HashMap的isEmpty方法内部直接比较size==0是否相等来确定是否为空,所以总结起来还是比较size的值。
public boolean isEmpty() {
return map.isEmpty();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean isEmpty() {
return size == 0;
}
contains()方法
HashSet的contains方法直接调用HashMap的containsKey方法来判断key是否存在,而containsKey内部通过根据key的hash值,通过计算的hash值找到table的槽位,如果第一个元素的key就是查询的key就直接返回,否则就依次遍历冲突链逐个进行比较解决。
这里需要说明的就是hash方法内部其实就是对key取了个hashcode()的值。
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
add()方法
HashSet的add方法内部通过HashMap.put()方法来实现key的添加,在HashMap内部真正执行的是putVal()方法,在putVal()的内部执行其实按照以下顺序执行的。
- 如果HashMap内部的桶数组没有初始化就创建一个桶数组
- 通过hash值找到桶下标,如果对应位置为空就直接创建一个Node节点newNode
- 通过hash值找到桶下标,如果对于位置不为空那么就直接比较key是否相等,如果相等就直接返回,如果遍历完成后都没有找到那么在链表的最后连接一个新创的节点
- 在新增节点后判断是否超过上限需要进行resize动作,resize()函数也是一个很有意思的过程,这个放到HashMap当中去分析吧
- ++modCount这个会记录值的变更然后通过比较值抛出更改异常
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
remove()方法
HashSet的remove方法内部通过调用HashMap的remove方法来实现key的删除。
HashMap的remove方法内部逻辑通过对key进行hash定位到hash桶的下标,然后遍历桶下面的列表节点通过比较key是否相同进行删除。
删除后同样会--size减少size,更新 ++modCount。
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
clear()方法
HashSet的clear方法内部调用HashMap的clear方法,在HashMap的内部clear当中就是直接把HashMap的桶的值的每个下标的值为null就可以了,估计内部会进行垃圾回收?
public void clear() {
map.clear();
}
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}
迭代器
在java的集合对象中,迭代器的实现是非常巧妙的部分,这块内容各位如果真心想了解一定好好看看,我尽量保证能够将这个过程讲解清楚。
HashSet的iterator()方法内部通过HashMap的keySet()方法,核心分析如下:
在keySet()方法当中,我们通过构造函数创建一个KeySet的类对象并调用方法iterator()。
在方法iterator()当中会创建KeyIterator对象并返回这个对象
在创建KeyIterator对象的过程中,我们会先初始化父类HashIterator的对象,在初始化HashIterator类的过程当中我们会赋值hash桶并遍历hash桶找到第一个非空元素
执行HashSet的iterator方法会调用KeyIterator对象的next()方法,会把在初始化HashIterator对象的时候第一个非空元素进行返回,然后按照下面的顺序进行遍历
遍历的过程为先遍历第一个非空hash桶的所有元素,如果遍历完这个hash桶那么就找下一个非空的hash桶继续遍历,所有整个next过程是按照桶的顺序进行遍历的
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
关键点
HashSet的实现支持null的key,同时HashSet的内部不支持重复的key,最后一定好好研究iterator。