考察内容包括numpy、pandas、matplotlib这3个库的内容
1、请写出numpy中创建数组的方式
答:np.arange、np.array、np.ones、np.zeros、np.full
2、numpy常规操作题:
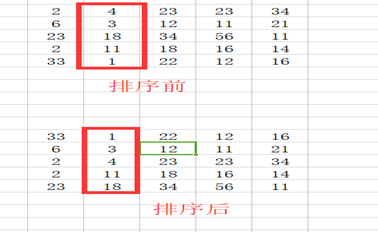
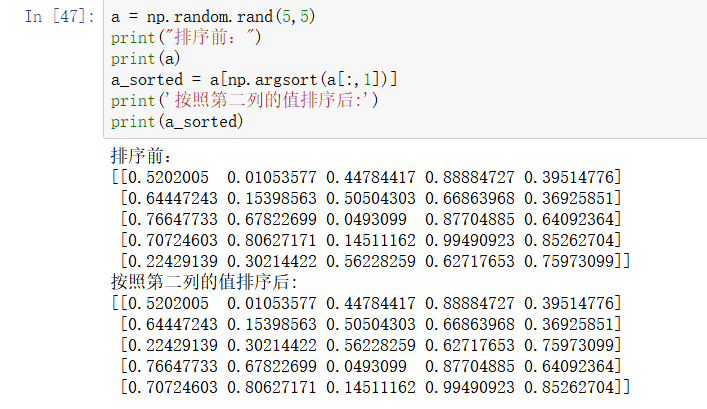
(1)用numpy中的随机函数np.random.rand(5,5),生成一个5x5的数组,并使用numpy中的切片、索引以及索引搜等方法,将数据根据第二列的数据大小进行重新排序(图中数据仅作为演示用)
a = np.random.rand(5,5)
print("排序前:")
print(a)
a_sorted = a[np.argsort(a[:,1])]
print('按照第二列的值排序后:')
print(a_sorted)
运行结果如下图所示:
(2) 用numpy至少两种方法生成如下所示的数组
第一种解法:
import numpy as np
m = np.ones((10,10))
m[1:-1,1:-1] = 0
print(m)
第二种解法:
import numpy as np
m = np.ones((10,10))
m[1:-1,1:-1] = np.zeros((8,8))
print(m)
第三种解法:
import numpy as np
m = np.zeros((10,10))
m[0] = 1
m[:,0] = 1
m[-1] = 1
m[:,-1] = 1
print(m)
(3)编写代码,判断第数组一中的每个元素在数组二中是否存在
数组一:[ 0 10 20 40 60]
数组二:[0, 40]
结果:[ True False False True False]
import numpy as np
m1 = np.array([0,10,20,40,60])
m2 = np.array([0, 40])
r1 = m1==m2[0]
r2 = m1==m2[1]
print(r1 | r2)
(4)编写代码,实现查找出两个numpy数组中相同的元素
数组一: [ 0 10 20 40 60]
数组二:[10, 30, 40]
结果:[10 40]
import numpy as np
m1 = np.array([0,10,20,40,60])
m2 = np.array([10,30,40])
print([k for k in m1 if k in m2])
(5)编写代码,实现查找出给定数组中比10大的数,返回新的数组values,同时给出比10大的数在原数组中的索引
给定数组:[[ 0 10 20] [20 30 40]]
求如下数组:
Values: [20 20 30 40]
索引数组: (array([0, 1, 1, 1]), array([2, 0, 1, 2]))
import numpy as np
a = np.array([[0,10,20],[20,30,40]])
pos = a > 10
Values = a[pos].ravel()
print(Values)
indexList = []
for i in range(2):
for j in range(3):
if pos[i][j]:
indexList.append([i,j])
indexArray = np.array(indexList).T
print(indexArray)
3、实时电影票房数据集
请使用tushare模块提供的api并结合numpy、scipy等模块,获取前一天电影排行数据中上映天数大于7中日平均票价最高的电影,分析该电影近一个星期的票房及电影票价的走势,要求分别绘制出票房走势和平均票价走势。
getDay7Movies函数的作用是获取上映时间超过7天的电影,返回值的数据类型为DataFrame
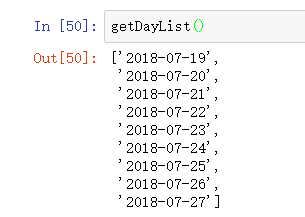
getDayList函数的作用是获取日期列表,列表中元素的数据类型为字符串str,如下图所示:
getMovieWeekRecord函数的作用是得到
电影最近一周的票房信息,需要一个参数,参数数据类型为字符串str,函数返回值的数据类型为DataFrame
drawBoxOffice函数的作用是画出
票房趋势图
drawAvgPrice函数的作用是画出
平均票价趋势图
解答代码如下,复制到py文件中可以直接运行,运行前安装tushare库命令:
pip install tushare
import tushare as ts
import datetime
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
def getDay7Movies():
movie_df = ts.day_boxoffice()
selected_df = movie_df[\
movie_df['MovieDay'].values.astype('int') > 7]
sorted_df = selected_df.sort_values(by='AvgPrice',ascending=False)
return sorted_df.reset_index(drop=True)
def getDayList():
day_list = []
now_time = datetime.datetime.now()
for i in range(-9,0):
day = now_time + datetime.timedelta(days=i)
dayStr = day.strftime("%Y-%m-%d")
day_list.append(dayStr)
return day_list
def getMovieWeekRecord(movieName):
day_list = getDayList()
record_list = []
for day in day_list:
try:
movie_all = ts.day_boxoffice(day)
record = movie_all[\
movie_all['MovieName'].values == movieName].copy()
record['date'] = day
record_list.append(record)
except Exception as e:
print(str(e))
return pd.concat(record_list).reset_index(drop=True)
def drawBoxOffice(movieWeekRecord):
x_ticks = [k[5:] for k in movieWeekRecord['date'].values]
x = range(len(x_ticks))
y = list(movieWeekRecord['BoxOffice'].values.astype("f"))
movieName = movieWeekRecord['MovieName'].iloc[0]
plt.title("《%s》电影最近一周票房走势图" %movieName)
plt.xlabel('日期')
plt.ylabel('单日票房')
plt.xticks(x,x_ticks)
plt.plot(x,y)
plt.show()
def drawAvgPrice(movieWeekRecord):
x_ticks = [k[5:] for k in movieWeekRecord['date'].values]
x = range(len(x_ticks))
y = list(movieWeekRecord['AvgPrice'].values.astype('int'))
movieName = movieWeekRecord['MovieName'].iloc[0]
plt.title("《%s》电影最近一周平均票价走势图" %movieName)
plt.xlabel('日期')
plt.ylabel('平均票价')
plt.xticks(x,x_ticks)
plt.ylim(min(y)-5,max(y)+5)
plt.plot(x,y)
plt.show()
if __name__ == "__main__":
day7Movies = getDay7Movies()
movieName = day7Movies.iloc[0]['MovieName']
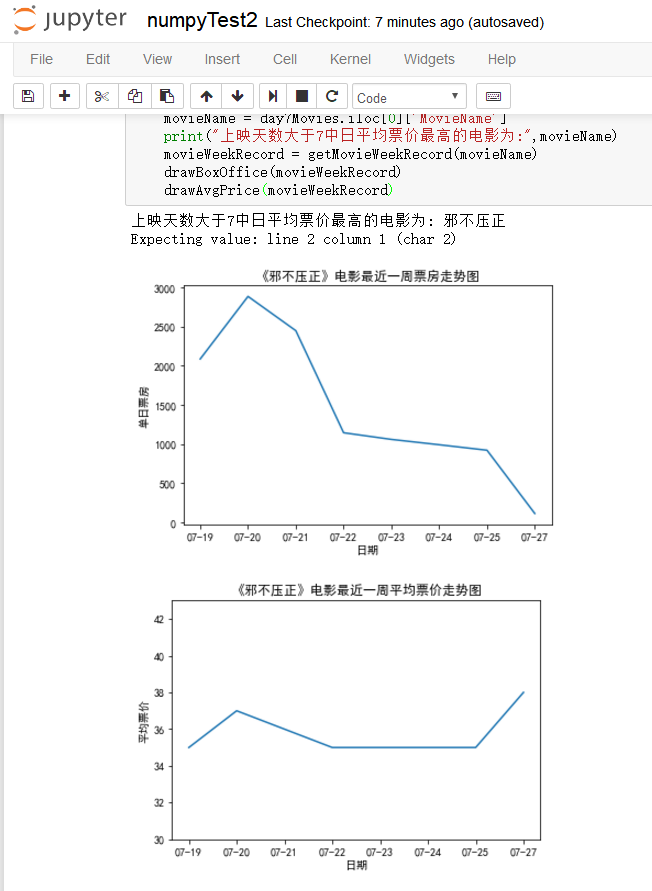
print("上映天数大于7中日平均票价最高的电影为:",movieName)
movieWeekRecord = getMovieWeekRecord(movieName)
drawBoxOffice(movieWeekRecord)
drawAvgPrice(movieWeekRecord)
运行结果如下图所示:
4、订单交易记录数据集
题目数据集csv文件下载链接: https://pan.baidu.com/s/1-pO92xn2NxGCSO5R3j1XTQ 密码: e1b4
文件中一部分数据如下图所示,其中包含:
order_id: 订单id号
account_id:消费账户id
bank_to:银行代码
account_to:消费账号
amoount:消费金额
k_symbol:备注
(1)根据bank_to字段,用numpy统计出每不同bank_to字段下所有消费记录的均值、最大值、最小值、并求和。
import pandas as pd
import numpy as np
df = pd.read_csv('order.csv',encoding='gbk')
df_sorted = df.groupby('bank_to').groups
df_sorted_keys = df_sorted.keys()
result_list = []
for key in df_sorted_keys:
group = {}
group['bank_to'] = key
amoutNdarray = df.values[df_sorted[key].values][:,4]
group['mean'] = np.mean(amoutNdarray)
group['max'] = np.max(amoutNdarray)
group['min'] = np.min(amoutNdarray)
result_list.append(group)
df_group = pd.DataFrame(result_list)
matrix = df_group.values
print(np.sum(matrix[:,1]),np.sum(matrix[:,2]),np.sum(matrix[:,3]))
(2) 然后将每个字段分类下的所有消费记录写入到一个新的csv文件中,
输出文件中包含:CD.csv IJ.csv QR.csv AB.csv ……….
import pandas as pd
df = pd.read_csv('order.csv',encoding='gbk')
df_sorted = df.groupby('bank_to')
for key,group in df_sorted:
print(key)
csvName = "%s.csv" %key
print(group.keys())
group.to_csv(csvName,columns=group.keys())
5、正态分布数据集
编写python代码,用随机函数生成一个有100个样本点的正态分布数据集,并根据数据集完成如下需求:
(1)求数据样本的偏度和分度,根据偏度和峰度值判断数据样本是正偏还是负偏,是高峡峰还是低阔峰。
(2)使用matplotlib库绘制出数据样本的分度直方图、
(3)编写代码说明在数据集中有多少个样本比1大,有多少个数据样本比1小。
答:(1)
import numpy as np
import pandas as pd
data = np.random.randn(100)
df = pd.DataFrame(data)
skew = df.skew()[0]
kurt = df.kurt()[0]
print("偏度为",skew)
print("峰度为",kurt)
print("样本是正偏" if skew > 0 else "样本是负偏")
print("样本是高峡峰" if kurt > 0 else "样本是低阔峰")
(2)(3)答案代码如下:
from matplotlib import pyplot as plt
import numpy as np
a = np.random.randn(100)
print("比1大的样本数量",np.sum(a>1))
print("比1小的样本数量",np.sum(a<1))
plt.hist(a)
plt.show()