

Java的几个不错的网站
Java核心技术卷 本丛书非常详细的讲解Java的核心概念、语法、重要特性和开发方法,包含大量案例,最近正在拜读。 Java白皮书,由Java设计者编写,阐述Java的一个简短的概述以及11个Java特性关键术语 上述11个特性的pdf阐述版 oracle官网/Java oracle官网/Java(中文) Java SE8 的 API Java Language and Virtual Machine Specifications Java Bug Database
最近在阅读源码的过程中发现自己对泛型和通配符的理解好像已经有点遗忘,还有就是有些混乱,今天借着这个机会就好好复习一下泛型知识。
最近在逛知乎,看源码的时候看到了关于泛型和通配符的一些知识。
在讨论这个之前,我们要明确自己的出发点
类型参数<T>用于第一种,声明泛型类或者泛型方法。无界通配符<?>主要用于第二种,使用泛型类或者泛型方法。
List<T>最该出现,是定义一个泛型List容器。
看看ArrayList源码头一行
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
…………
}
ArrayList<E>中的E也是类型参数。只不过习惯将容器中元素的类型与英文名一致Element,所以有了<E>。
之所以要给List带上泛型,是因为在对象存储进集合中后,会出现类型擦除的现象,而且也是在说明集合中所容纳的元素应该还是同一类型的。
比如如下一个方法
public static <T> List<T> reduce(List<T> list) {
//doSomething
}
这样的方法声明使用泛型,也是为了保持类型的一致,List<T>返回值前的<T>是在说明这个方法是一个泛型方法。
通配符是拿来使用定义好的泛型的。比如<?>声明List容器的变量类型,然后用一个实例对象给它赋值的时候就比较灵活。
List<?> list = new ArrayList<String>();
//这个时候通配符捕获到类型为String但是编译器却不能标识它为String
//可能会标识成一个代号,这种情况下,下列代码就会出现报错情况
List<?> list = new ArrayList<String>();
list.add("test");
list.add(1);
<? extends T> 是指"上界通配符"
<? super T> 是指"下界通配符"
上下界通配符这个地方前天学弟问了我一个问题,才发现泛型远远不是只是类型推断和集合规范,不多说直接上问题
先贴出3个类的实现
class AA {
private String aa;
public AA() {
}
public AA(String aa) {
this.aa = aa;
}
@Override
public String toString() {
return this.aa;
}
}
class BB extends AA {
private String bb;
public BB() {
}
public BB(String bb) {
this.bb = bb;
}
@Override
public String toString() {
return this.bb;
}
}
class CC extends BB {
private String cc;
public CC(String cc) {
this.cc = cc;
}
@Override
public String toString() {
return this.cc;
}
}
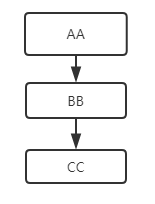
我们分析一下继承树的结构
AA类作为BB的直接父类,CC类的超类
BB类继承AA类作为CC类的父类
问题A:为什么下面的代码片段会报错
问题B:那么为什么下面这段代码不会报错
问题C:为什么下面这段代码又出现了问题
首先我们要理解什么是<? extends AA>这种使用?未知通配符搭配继承标志extends作为泛型参数整体作为上界通配符,它的出现规定了Collection的实现类中包含的元素种类为AA类或者AA类的子类
可是通过画出的继承树,确实BB和CC类是他的子类没有错,可为什么在这里程序出了问题,而且还是编译器的问题都没有一点运行的空间? 我们仔细想想泛型的作用,尤其是这种未知通配符的作用,我们再来看一段代码
public static void print(List<?> list) {
System.out.println(list.get(0).toString());
}
再从主函数中调用一下这个未知通配符作为参数的方法(该方法的目的是打印list集合的第一个对象的值)
AA father = new AA("AA");
BB son1 = new BB("BB");
CC grandSon = new CC("CC");
List<AA> testAAList = new ArrayList<>();
testAAList.add(father);
print(testAALis);
List<BB> testBBList = new ArrayList<>();
testBBList.add(son1);
print(testBBLis);
List<CC> testCCList = new ArrayList<>();
testCCList.add(grandSon);
print(testCCList);
那么我们在每次使用print方法的时候实际传入的泛型是什么?分别是AA BB CC,因为泛型为?未知通配符的list参数已经在使用print方法的时候确定了下来,那么我们再来考虑一下Java面向对象的基本思想多态赋予Java的能力
//正确代码
AA aa = new BB();
BB bb = new CC();
//错误代码
CC cc = new AA();
想必Java程序员一眼就能看出这段代码的问题,正是因为多态的存在,使得编译期父类的变量可以赋值为子类实例
我们有了这个概念之后再回过头来看看问题A
//错误代码
public void test(Collection<? extends AA> collection) {
collection.add(new BB());
collection.add(new CC());
}
虽然参数Collection使用了上界通配符这种写法规定泛型类型只能是AA或者AA的子类,但是这个未知通配符并不能在编译期正确地推断出首次使用add方法的时候传入参数的泛型类型去规定整个collection的类型,也正是因为这样,如果程序在使用collection调用add方法时先传入一个CC实例,再传入一个BB实例,那么泛型虽然还在,但是根据Java的多态,子类对象的变量不能够赋值为父类实例,也正是因为这一点,Java设计的上界通配符不能在add方法时调用成功,无论这个类是否为上界本身或上界的子类
问题A解决之后我们看一下问题B
问题B需要与问题C一起看待才能更加清晰
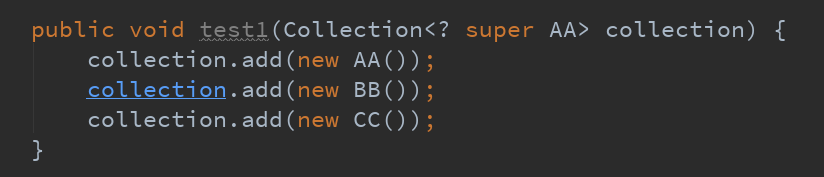
//问题B正确代码
public void test1(Collection<? super AA> collection) {
collection.add(new AA());
collection.add(new BB());
collection.add(new CC());
}
//问题C错误代码
public void test1(Collection<? super BB> collection) {
collection.add(new AA());
collection.add(new BB());
collection.add(new CC());
}
可以看到两个方法块只是换了参数的下届类型,就得出了全然不一样的结果,有人会说这不是下界通配符吗?为什么可以add子类,下界通配符的含义不是AA类和AA类的父类或超类吗?为什么下界为AA时collection可以调用add方法添加AA的子类或者AA本身? 再想想多态的含义,既然这个参数的泛型要求是AA本身或者AA的超类那为什么不能add AA的子类呢,这不就是多态的含义吗
问题3的错误代码问题显然也是错在了这里,也正是因为多态的要求,和上述前阐明的原因,根据Java的多态,子类对象的变量不能够赋值为父类实例 下界通配符也无法在编译期就得出范兴德确定类型,所以Java在这里做出了这两种编译报错来提醒我们不要犯这种小错误,编译期能够发现的问题就留在编译期,不要再等到运行阶段再发觉
要不是学弟问我问题,这个概念至少要等上一个月才能被我重新捡起,更让我觉得温故而知新,程序员也一样...

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273