阐述LEGB前,需要先对Python的命名空间、作用域有一定的了解。
命名空间
命名空间表示变量的可见范围,一个变量名可以定义在多个不同的命名空间,相互之间并不冲突,但同一个命名空间中不能有两个相同的变量名。比如:两个叫“张三”的学生可以同时存在于班级A和班级B中,如果两个张三都是一个班级,那么带来的麻烦复杂很多了,在Python中你不能这么干。
在Python中用字典来表示一个命名空间,命名空间中保存了变量(名字)和对象的映射关系,在Python中命名空间出现在哪些地方呢?有函数范围内的命名空间(local),有模块范围内的命名空间(global),有python内建的命名空间(built-in),还有类对象的所有属性组成的命名空间。
命名空间的生命周期
所有的命名空间都是有生命周期的,对于python内建的命名空间,python解析器启动时创建,一直保留直至直python解析器退出时才消亡。而对于函数的local命名空间是在函数每次被调用的时候创建,调用完成函数返回时消亡,而对于模块的global命名空间是在该模块被import的时候创建,解析器退出时消亡。
作用域
一个作用域是指一段程序的正文区域,可以是一个函数或一段代码。一个变量的作用域是指该变量的有效范围。Python的作用域是静态作用域,因为它是由代码中得位置决定的,而命名空间就是作用域的动态表现。
什么是LGB
Python2.2之前定义了三个作用域,分别是:
- global作用域,对应的global命名空间,一个模块最外层定义的一个作用域。
- local作用域,对应local命名空间,由函数定义的。
- builtin作用域,对应builtin命名空间,python内部定义的最顶层的作用域,在这个作用域里面定义了各种内建函数:open、range、xrange、list等等。
那时的Python作用域规则叫做LGB规则,变量(名字)的引用按照local作用域、global作用域、builtin作用域的顺序来查找。
看一段代码:
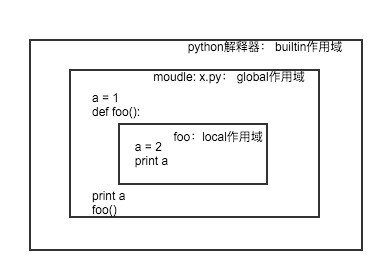
a = 1
def foo():
a = 2
print a [1]
print a [2]
foo()
运行结果:
1
2
[1]处输出结果为2,Python首先会在函数foo定义的local作用域中查找名字a,如果找到了直接输出,没有没找到就会在模块定义的global作用域中查找,如果还没找到,就到Python内建的builtin作用域中查找a,如果还没找到就报异常:NameError: name 'a' is not defined。引用过程如图:
[2]处输出结果为1,查找顺序同样是按照LGB规则,只不过这里的local作用域就是global作用域。
LEGB规则
Python2.2开始引入嵌套函数,嵌套函数为python提供了闭包实现。
a = 1
def foo():
a = 2
def bar():
print a //[1]
return bar
func = foo()
func()
函数bar和a=2捆包在一起组成一个闭包,因此这里a=2即使脱离了foo所在的local作用域,但调用func的时候(其实就是调用bar)查找名字a的顺序是LEGB规则,这里的E就是enclosing的缩写,代表的“直接外围作用域”这个概念。查找a时,在bar对应的local作用域中没有时,然后在它外围的作用域中查找a。LEGB规定了查找一个名称的顺序为:local-->enclosing-->global-->builtin。
LEGB含义解释:
L-Local(function);函数内的名字空间
E-Enclosing function locals;外部嵌套函数的名字空间(例如closure)
G-Global(module);函数定义所在模块(文件)的名字空间
B-Builtin(Python);Python内置模块的名字空间
一个有趣的测试
在Python2中运行下边代码:
i = 20
l = [i for i in range(10)]
print i
在Python3中运行下边代码:
i = 20
l = [i for i in range(10)]
print(i)
得到的结果是什么?
在python2中运行,结果为 9
在python3中运行,结果为 20
原因在于,python3中列表解析自带闭包,也就是遵从上边说的LEGB规则