基于python的Scrapy爬虫框架实战
2018年7月19日笔记
1.伯乐在线
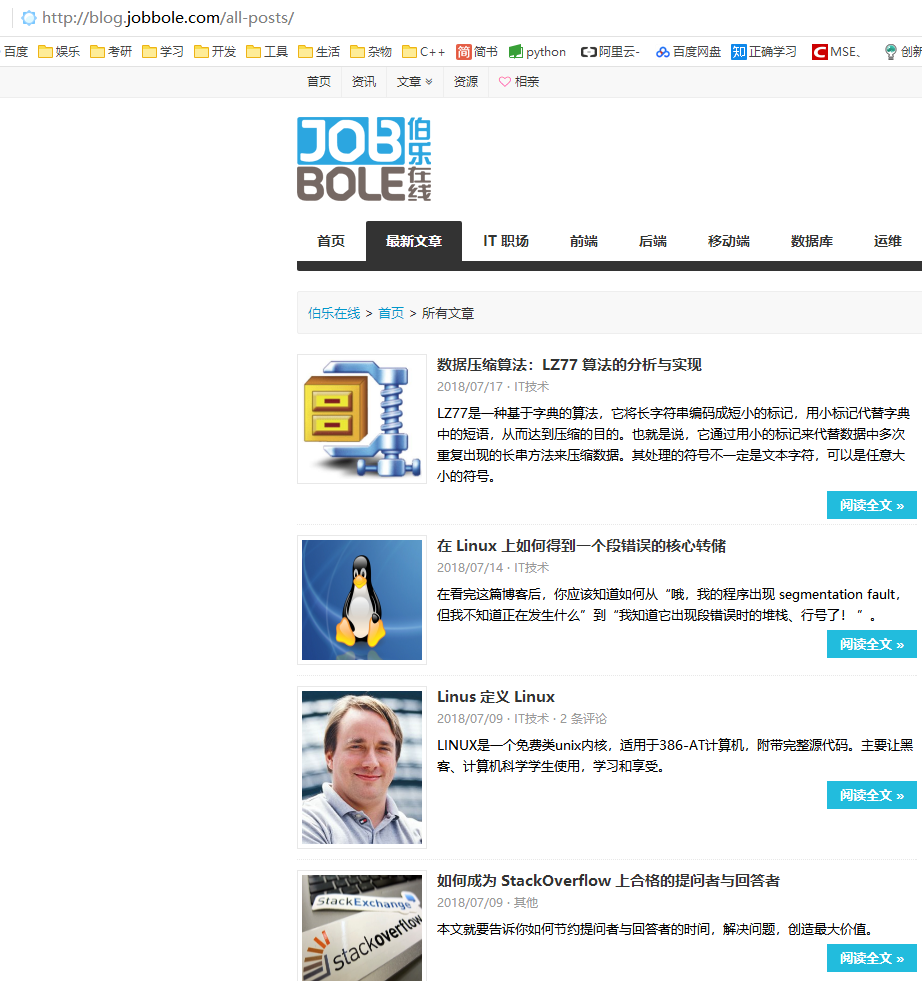
网站页面如下图所示:
![网站页面.png]()
网站页面.png
1.1 新建爬虫工程
命令:scrapy startproject BoleArticle
![新建爬虫工程命令]()
新建爬虫工程命令
命令:
scrapy genspider article "blog.jobbole.com"
注意:运行此命令时必须在爬虫工程文件夹内,如下图路径所示。
![新建爬虫文件命令]()
新建爬虫文件命令
1.2 编辑items.py文件
6个字段:title、publishTime、category、digest、detailUrl、img_url,数据类型为scrapy.Field对象
import scrapy
from scrapy import Field
class BolearticleItem(scrapy.Item):
title = Field()
publishTime = Field()
category = Field()
digest = Field()
detailUrl = Field()
img_url =Field()
1.3 编辑article.py文件
parse函数用于解析最大共有多少页,并将每一个目录页面的链接通过字符串拼接的方法传给下一级解析函数
scrapy.Request函数里面有2个参数:第1个参数数据类型是字符串,是下一级解析页面的url链接;
第2个参数数据类型是函数对象,是ArticleSpider里面函数的函数名。
parse1函数用于解析每一个目录页面的文章信息,共有6个字段:title、publishTime、category、digest、detailUrl、img_url,publishTime字段是通过正则表达式找到的,具体是使用re.search方法。其他字段通过xpath可以找到。
import scrapy
from ..items import BolearticleItem
import re
class ArticleSpider(scrapy.Spider):
name = 'article'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
pageNum = response.xpath("//a[@class='page-numbers']/text()")[-1].extract()
for i in range(1,int(pageNum)+1):
url = "http://blog.jobbole.com/all-posts/page/{}/".format(i)
yield scrapy.Request(url,callback=self.parse1)
def parse1(self,response):
def find(xpath, pNode=response):
if len(pNode.xpath(xpath)):
return pNode.xpath(xpath).extract()[0]
else:
return ''
article_list = response.xpath("//div[@class='post floated-thumb']")
for article in article_list:
item = BolearticleItem()
item['title'] = find("div[1]/a/@title",article)
pTagStr = find("div[2]/p",article)
item['publishTime'] = re.search("\d+/\d+/\d+",pTagStr).group(0)
item['category'] = find("div[2]/p/a[2]/text()",article)
item['digest'] = find("div[2]/span/p/text()",article)
item['detailUrl'] = find("div[2]/p/a[1]/@href",article)
item['img_url'] = find("div[1]/a/img/@src",article)
yield item
1.4 编辑pipelines.py文件
在管道类初始化时,删除并新建表article1
下面一段代码中有2处需要修改:1.数据库名,第4行的变量database;2.数据库连接的密码,第8行的变量passwd
代码第28行变量insert_sql的数据类型是字符串,通过字符串拼接形成插入数据的sql语句。
理解变量fieldStr、valueStr形成过程的难点是字符串的join方法和推导式
每次插入数据后都执行self.conn.commit()
import pymysql
from time import time
def getConn(database ="bolearticle"):
args = dict(
host = 'localhost',
user = 'root',
passwd = '... your password',
charset = 'utf8',
db = database
)
return pymysql.connect(**args)
class BolearticlePipeline(object):
startTime = time()
conn = getConn()
cursor = conn.cursor()
drop_sql = "drop table if exists article1"
cursor.execute(drop_sql)
create_sql = "create table article1(title varchar(200) primary key,publishtime varchar(30)," \
"category varchar(30),digest varchar(500)," \
"detailUrl varchar(200),img_url varchar(200));"
cursor.execute(create_sql)
def process_item(self, item, spider):
fieldStr = ','.join(['`%s`'%k for k in item.keys()])
valuesStr = ','.join(['"%s"'%v for v in item.values()])
insert_sql = "insert into article1(%s) values(%s)" %(fieldStr,valuesStr)
self.cursor.execute(insert_sql)
self.conn.commit()
return item
1.5 编辑settings.py文件
关键点是最后3行要开启管道,CONCURRENT_REQUESTS变量设置为96能够较好利用多线程性能
ROBOTSTXT_OBEY设置为False,意思是不遵守爬虫协议,也称机器人协议。如果设置为True,即遵守爬虫协议,则可能访问受限。
BOT_NAME = 'BoleArticle'
SPIDER_MODULES = ['BoleArticle.spiders']
NEWSPIDER_MODULE = 'BoleArticle.spiders'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 96
ITEM_PIPELINES = {
'BoleArticle.pipelines.BolearticlePipeline': 300,
}
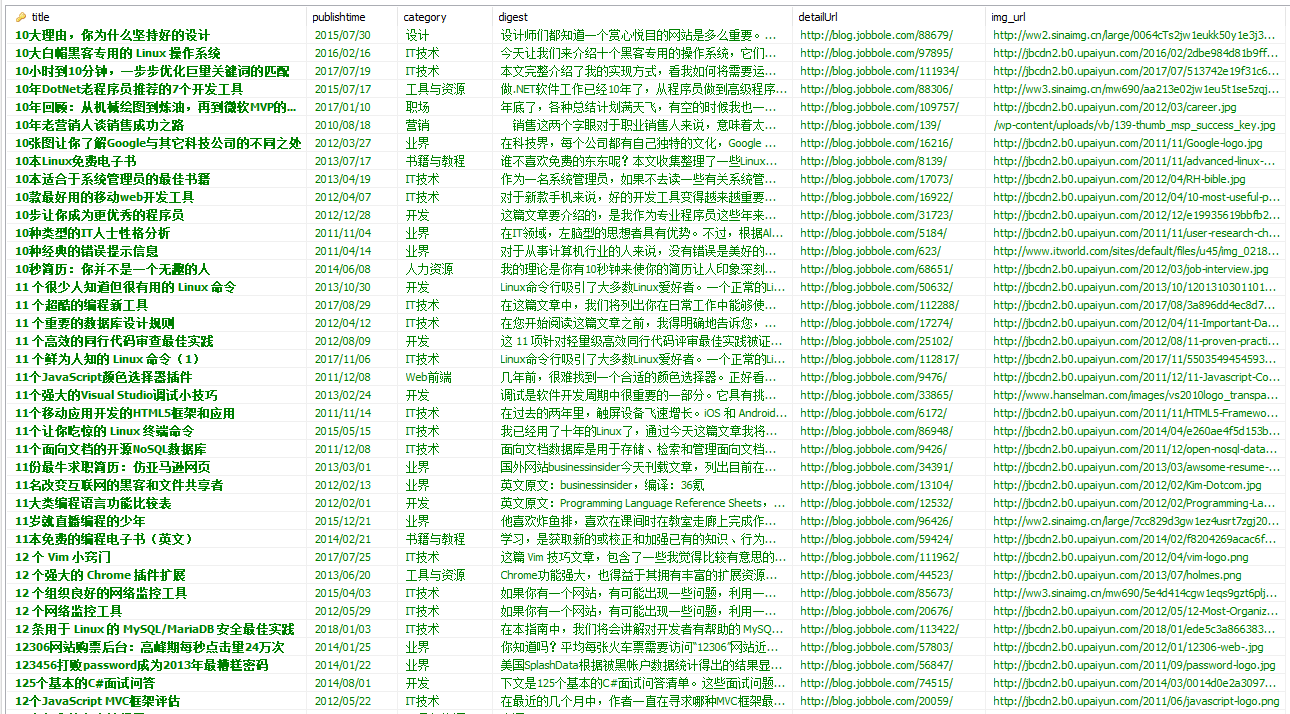
1.6 运行结果
在命令行中运行命令:scrapy crawl article
查看数据库,结果截图如下:
![图片.png-117.4kB]()
图片.png-117.4kB
2.网易新闻图片
网址:http://news.163.com/special/photo-search/#q=%E4%B8%AD%E5%9B%BD
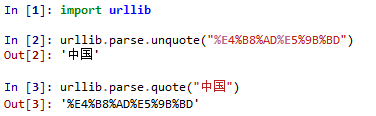
用urllib.parse.unquote方法查看%E4%B8%AD%E5%9B%BD的中文对应字符,如下图所示:
![图片.png-3.8kB]()
图片.png-3.8kB
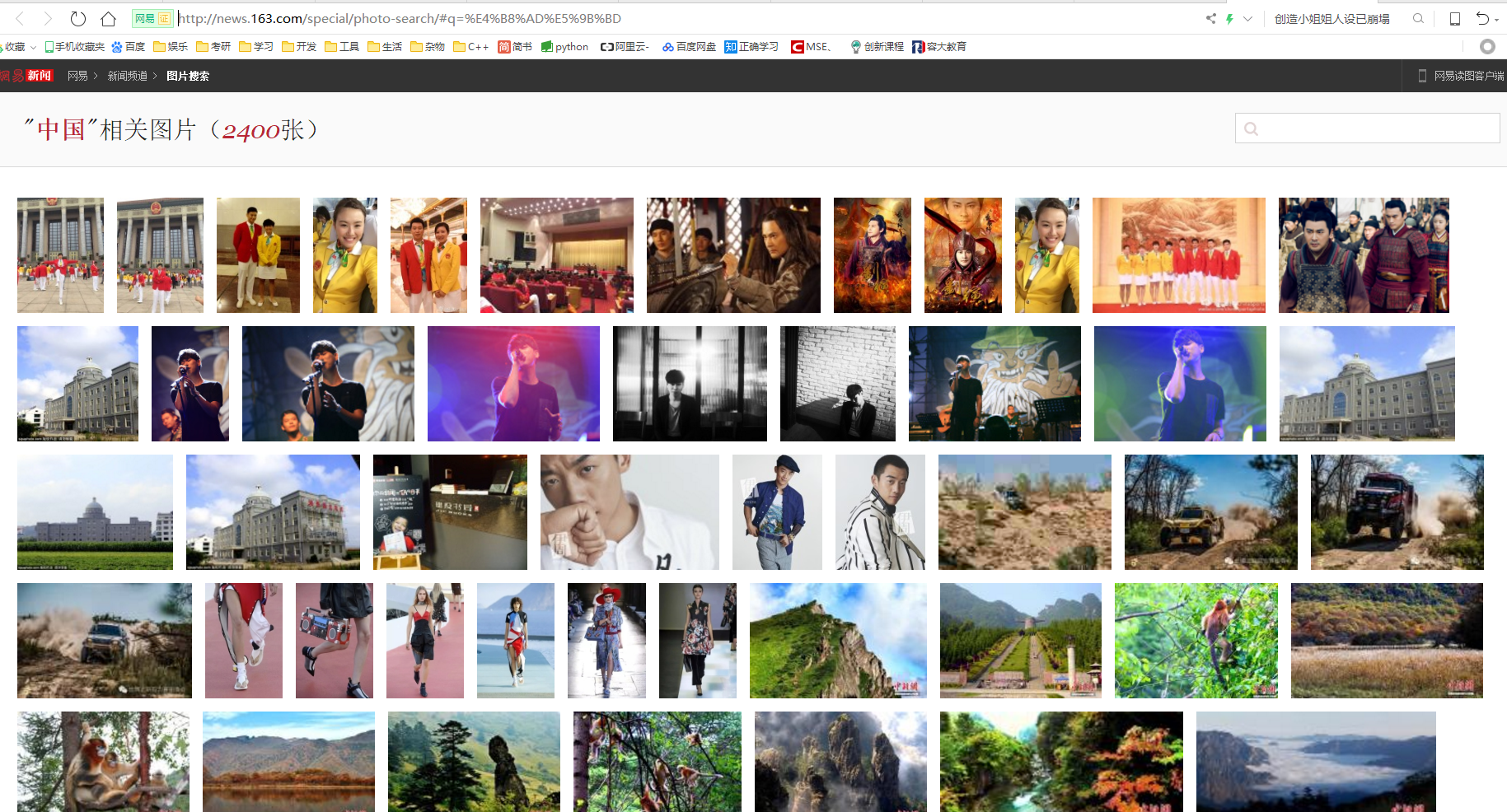
网站页面如下图所示,需要爬取2400张图片:
![图片.png-2954.8kB]()
图片.png-2954.8kB
2.1 新建爬虫工程
新建爬虫工程命令:scrapy startproject NeteasyImage
进入爬虫工程文件夹:cd .\NeteasyImage
新建爬虫文件命令:scrapy genspider image "news.163.com"
2.2 编辑items.py文件
3个字段:id、img_url、img_title
import scrapy
from scrapy import Field
class NeteasyimageItem(scrapy.Item):
id = Field()
img_url = Field()
img_title = Field()
2.3 编辑image.py文件
image_number变量是下载图片的数量。
start_urls变量数据类型为列表,其中的每个元素的数据类型为字符串,是获取图片链接的请求url。
start_urls中的元素发出请求返回的内容为json类型的文本。
json.loads方法中有1个参数,参数数据类型为字符串,这个方法的作用可以把字符串转为字典,要求字符串必须以{开头,以}结束。
对于下图的json文本来说,需要删除左边的var jsonres=,删除最后一个字符;
转化后的字典赋值给jsonLoad变量,jsonLoad['hits']数据类型为列表,当中有图片的链接,标题等。
id字段用来判断是第几张图。
![图片.png-111.3kB]()
图片.png-111.3kB
import scrapy
import json
from ..items import NeteasyimageItem
class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['netease.com']
image_number = 2000
urlBefore = "http://uvs.youdao.com/search?site=photogalaxy.163.com" \
"&sort=time&channelid=&q=%E4%B8%AD%E5%9B%BD&length=100&start={}"
start_urls = []
for i in range(0, image_number, 100):
start_urls.append(urlBefore.format(i))
count = 0
def parse(self, response):
jsonStr = response.text.lstrip("var jsonres=").strip().strip(";")
jsonLoad = json.loads(jsonStr)
for image in jsonLoad['hits']:
self.count += 1
item = NeteasyimageItem()
item['id'] = self.count
item['img_title'] = image['setname']
item['img_url'] = image['imgsrc']
yield item
2.4 编辑settings.py文件
关键点是最后3行要开启管道,CONCURRENT_REQUESTS变量设置为96能够较好利用多线程性能
ROBOTSTXT_OBEY设置为False,意思是不遵守爬虫协议,也称机器人协议。如果设置为True,即遵守爬虫协议,则可能访问受限。
import os
BOT_NAME = 'NeteasyImage'
SPIDER_MODULES = ['NeteasyImage.spiders']
NEWSPIDER_MODULE = 'NeteasyImage.spiders'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 96
CONCURRENT_ITEMS = 200
IMAGES_STORE = os.getcwd() + '/images/'
ITEM_PIPELINES = {
'NeteasyImage.pipelines.NeteasyimagePipeline': 300,
}
2.5 编辑pipelines.py文件
下面代码比较难懂的地方是item_completed函数中的results参数
results数据类型为列表,列表中的第一个元素为元组,元组中第一个元素result[0][0]数据类型为布尔,是下载结果是否成功。
result[0][1]是下载图片返回的一些信息,数据类型为字典,其中有3个键值对,3个键为url、path、checksum。格式如下所示。
{'url': 'http://img2.cache.netease.com/photo/0003/2016-07-18/t_BS95B1C900AJ0003.jpg', 'path':
'full/98979c89e2b5e6ef9926183dab4e8bf5a8efa8a4.jpg', 'checksum': '15d5231fcd77d81ddd58d7db6a07c1ce'}
url是下载图片的链接,path是下载图片保存的路径,checksum是下载图片的文件校验和。
用os.rename方法重命名图片文件。
from scrapy.pipelines.images import ImagesPipeline
import scrapy
from .settings import IMAGES_STORE as images_store
import os
class NeteasyimagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(item['img_url'])
def item_completed(self, results, item, info):
if results[0][0]:
old_path = images_store + results[0][1]['path']
fileName = "{}-{}.jpg".format(item['id'],item['img_title'])
new_path = images_store + fileName
os.rename(old_path,new_path)
2.6 运行结果
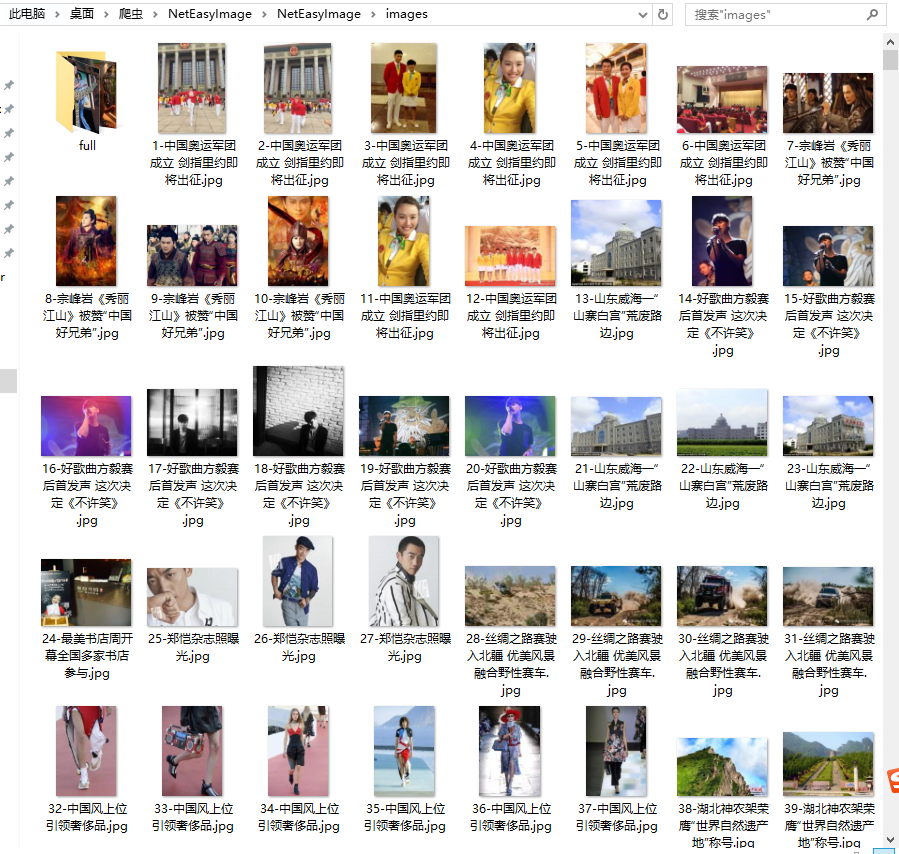
在命令行中运行命令:scrapy crawl image
查看图片保存的文件夹,如下图所示:
![图片.png-641.4kB]()
图片.png-641.4kB