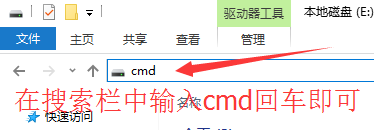
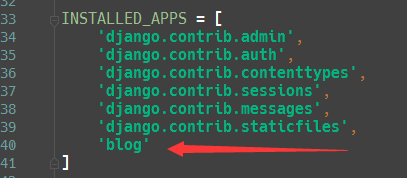
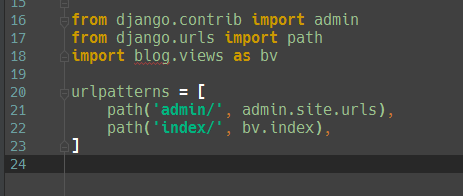
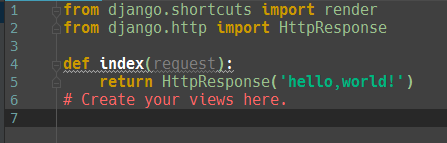

python爬虫爬取豆瓣电影
最近买了《python编程从入门到实践》,想之后写两篇文章,一篇数据可视化,一篇python web,今天这篇就当python入门吧。 一.前期准备: IDE准备:pycharm 导入的python库:requests用于请求,BeautifulSoup用于网页解析 二.实现步骤 1.传入url 2.解析返回的数据 3.筛选 4.遍历提取数据 三.代码实现 import requests # 导入网页请求库 from bs4 import BeautifulSoup # 导入网页解析库 # 传入URL r = requests.get("https://movie.douban.com/top250") # 解析返回的数据 soup=BeautifulSoup(r.content,"html.parser") #找到div中,class属性为item的div movie_list=soup.find_all("div",class_="item") #遍历提取数据 for movie in movie_list: title=movie.find("span",class_="titl...