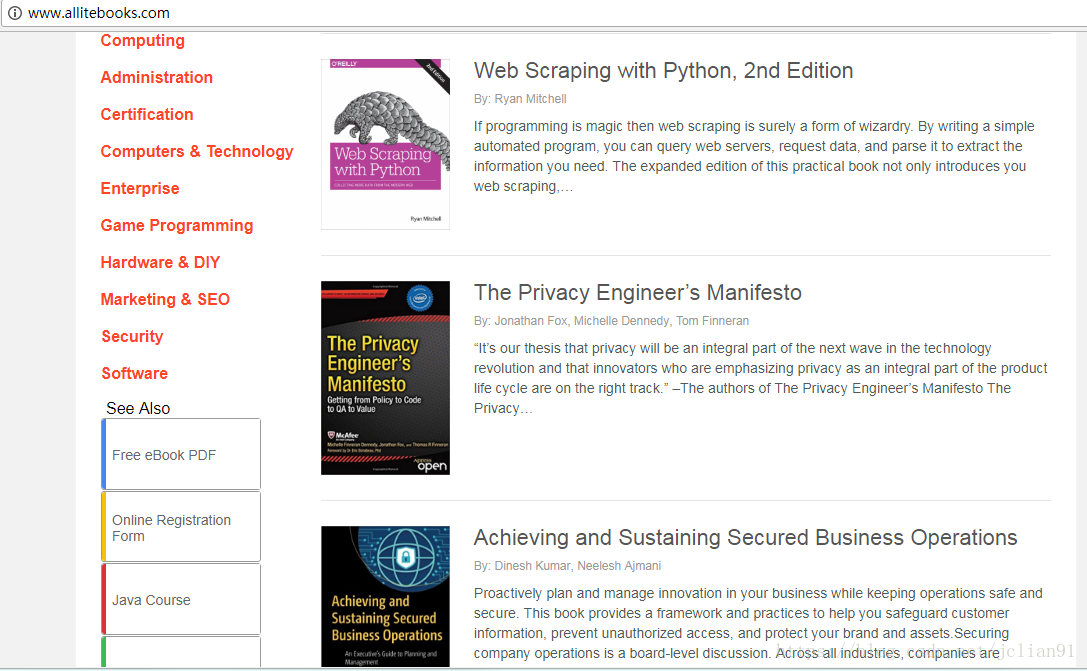
近段时间,笔者发现一个神奇的网站:http://www.allitebooks.com/ ,该网站提供了大量免费的编程方面的电子书,是技术爱好者们的福音。其页面如下:
![]()
那么我们是否可以通过Python来制作爬虫来帮助我们实现自动下载这些电子书呢?答案是yes.
笔者在空闲时间写了一个爬虫,主要利用urllib.request.urlretrieve()函数和多线程来下载这些电子书。
首先呢,笔者的想法是先将这些电子书的下载链接网址储存到本地的txt文件中,便于永久使用。其Python代码(Ebooks_spider.py)如下, 该代码仅下载第一页的10本电子书作为示例:
import urllib.request
from bs4 import BeautifulSoup
def get_content(url):
html = urllib.request.urlopen(url)
content = html.read().decode('utf-8')
html.close()
return content
base_url = 'http://www.allitebooks.com/'
urls = [base_url]
for i in range(2, 762):
urls.append(base_url + 'page/%d/' % i)
book_list =[]
for url in urls[:1]:
try:
content = get_content(url)
soup = BeautifulSoup(content, 'lxml')
book_links = soup.find_all('div', class_="entry-thumbnail hover-thumb")
book_links = [item('a')[0]['href'] for item in book_links]
print('\nGet page %d successfully!' % (urls.index(url) + 1))
except Exception:
book_links = []
print('\nGet page %d failed!' % (urls.index(url) + 1))
if len(book_links):
for book_link in book_links:
try:
content = get_content(book_link)
soup = BeautifulSoup(content, 'lxml')
link = soup.find('span', class_='download-links')
book_url = link('a')[0]['href']
if book_url:
book_name = book_url.split('/')[-1]
print('Getting book: %s' % book_name)
book_list.append(book_url)
except Exception as e:
print('Get page %d Book %d failed'
% (urls.index(url) + 1, book_links.index(book_link)))
directory = 'E:\\Ebooks\\'
with open(directory+'book.txt', 'w') as f:
for item in book_list:
f.write(str(item)+'\n')
print('写入txt文件完毕!')
可以看到,上述代码主要爬取的是静态页面,因此效率非常高!运行该程序,显示结果如下:
![]()
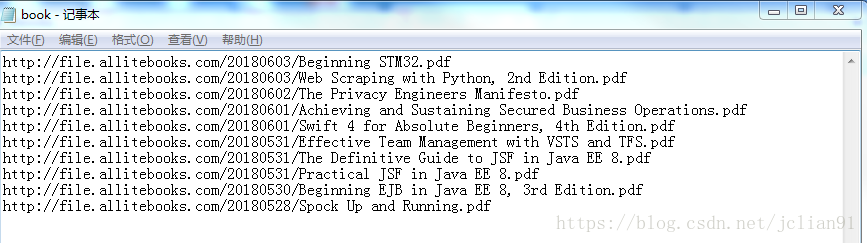
在book.txt文件中储存了这10本电子书的下载地址,如下:
![]()
接着我们再读取这些下载链接,用urllib.request.urlretrieve()函数和多线程来下载这些电子书。其Python代码(download_ebook.py)如下:
import time
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
import urllib.request
def download(url):
book_name = 'E:\\Ebooks\\'+url.split('/')[-1]
print('Downloading book: %s'%book_name)
urllib.request.urlretrieve(url, book_name)
print('Finish downloading book: %s'%book_name)
def main():
start_time = time.time()
file_path = 'E:\\Ebooks\\book.txt'
with open(file_path, 'r') as f:
urls = f.readlines()
urls = [_.strip() for _ in urls]
executor = ThreadPoolExecutor(len(urls))
future_tasks = [executor.submit(download, url) for url in urls]
wait(future_tasks, return_when=ALL_COMPLETED)
end_time = time.time()
print('Total cost time:%s'%(end_time - start_time))
main()
运行上述代码,结果如下:
![]()
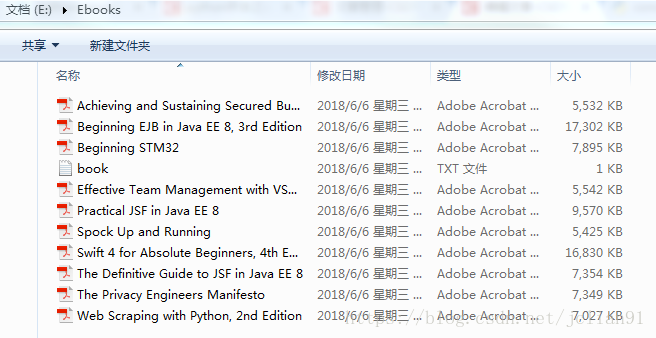
再去文件夹中查看文件:
![]()
可以看到这10本书都已成功下载,总共用时327秒,每本书的平均下载时间为32.7,约半分钟,而这些书的大小为87.7MB,可见效率相当高的!
怎么样,看到爬虫能做这些多有意思的事情,不知此刻的你有没有心动呢?心动不如行动,至理名言~~
本次代码已上传github, 地址为:
https://github.com/percent4/Examples-of-Python-Spiders .
注意:本人现已开通两个微信公众号: 用Python做数学(微信号为:python_math)以及轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~