原文:
把项目中那些恶心的无处存储的大块数据都丢到FastDFS之快速搭建
在我们开发项目的时候,经常会遇到大块数据的问题(2M-100M),比如说保存报表中1w个人的ID号,他就像一个肿瘤一样,存储在服务器哪里都
觉得恶心,放在redis,mongodb中吧,一下子你就会收到报警,因为内存满了。。。放在mysql吧???你还得建立一个text字段,和一些小字段混在一起,
还是有点恶心,还得单独拆出来,还得怕有些sql不规范的人挺喜欢select * 的,这速度挺恶心的呀。。。直接放到硬盘吧,没扩展性,你1T大小的硬盘又能
怎样,照样撑爆你,放在hadoop里面吧,对.net程序员来说,没有这个缘分,好不容易微软有一个.net hadoop sdk,说放弃就放弃了,兼具以上各种特性,
最后目光只能落到FastDFS上了。
一: FastDFS
fastDFS的本意是一个分布式的文件系统,所以大家可以上传各种小文件,包括这篇和大家说到的那些一坨一坨的数据,同样你也可以认为是一些小文件,
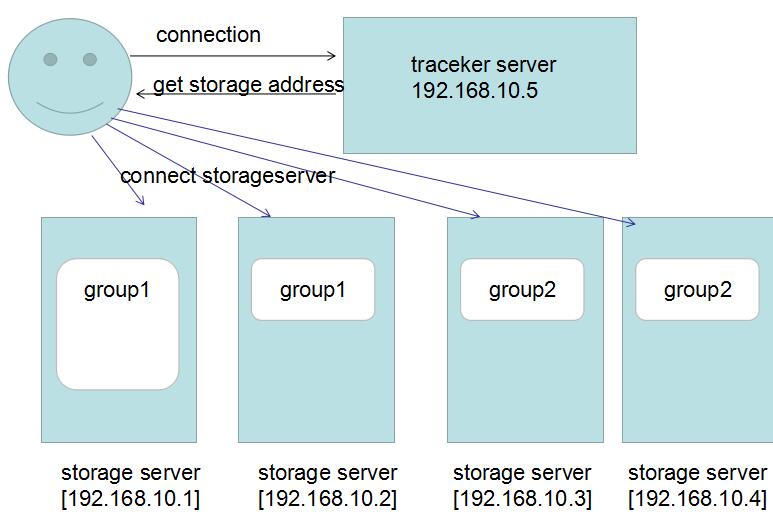
下面我画一下它的大概架构图:
![]()
我来解释一下:
1. fastDFS是按照Group的形式对file进行分组存储的,这里的group1你可以理解成C盘,group2理解成D盘,所有的数据都是在Group来划分的。
2. 为了提高读取性能和热备份,我们把group1放到了两台机器上,大概可能觉得有点浪费,对吧,事实就是这样。
3. 为了提高扩展性,因为单机是有存储上限的,这时候你可以再新建一个group2,也就是D盘,放到另外机器上,这样你就扩容了,对吧。
4. trackerServer主要用来保存group和storage的一些状态信息,主要和client端进行交互,返回正确的storeage server地址,这个和hadoop的
namenode其实是同一个角色的。
5. 这里要注意的一个地方就是,client端在存储file的时候,需要告诉trackerserver,你需要存储到哪一个group中,比如group1还是group2?
二:下载安装【CentOS】
为了方便测试,这里我部署到一台CentOS了。
1. 下载fastDFS基础包: https://github.com/happyfish100/libfastcommon/releases
![]()
2. 然后下载fast源码包:https://github.com/happyfish100/fastdfs/releases
![]()
3. wget之后,先把libfastcommon给安装一下
tar -xzvf V1.0.36
cd libfastcommon-1.0.36
./make.sh && ./make.sh install
再把fastdfs安装一下。
tar -xzvf V5.11
cd fastdfs-5.11
./make.sh &&./make.sh install
这样的话,我们的fast就算安装好了,因为是默认安装,所以配置文件是在 /etc/fdfs目录下,启动服务在/etc/init.d下。
[root@localhost ~]# cd /etc/fdfs
[root@localhost fdfs]# ls
client.conf client.conf.sample storage.conf.sample storage_ids.conf.sample tracker.conf.sample
[root@localhost fdfs]# cd /etc/init.d
[root@localhost init.d]# ls
fdfs_storaged fdfs_trackerd functions netconsole network README
[root@localhost init.d]#
然后再把两个storage.conf.sample 和 tracker.conf.sample中copy出我们需要配置的文件。
[root@localhost fdfs]# cp storage.conf.sample storage.conf
[root@localhost fdfs]# cp tracker.conf.sample tracker.conf
[root@localhost fdfs]# ls
client.conf client.conf.sample storage.conf storage.conf.sample storage_ids.conf.sample tracker.conf tracker.conf.sample
[root@localhost fdfs]#
4. tracker.conf 配置
这个配置文件,主要是配置里面的base_path。
# the base path to store data and log files
base_path=/usr/fast/fastdfs-5.11/data/tracker
指定完路径之后,我们创建一个data文件夹和tracker文件夹。
5. storage.conf 配置
这个配置文件,我们主要配置三样东西。
1. 本storage服务器的groupname,大家看过架构图应该也明白了,对吧。
2. 为了提高磁盘读写,可以指定本groupname的file存储在哪些磁盘上。
3. 指定和哪一台trackerserver进行交互。
# the name of the group this storage server belongs to
#
# comment or remove this item for fetching from tracker server,
# in this case, use_storage_id must set to true in tracker.conf,
# and storage_ids.conf must be configed correctly.
group_name=group1
# the base path to store data and log files
base_path=/usr/fast/fastdfs-5.11/data/storage
# path(disk or mount point) count, default value is 1
store_path_count=1
# store_path#, based 0, if store_path0 not exists, it's value is base_path
# the paths must be exist
store_path0=/usr/fast/fastdfs-5.11/data/storage/0
#store_path1=/home/yuqing/fastdfs2
# tracker_server can ocur more than once, and tracker_server format is
# "host:port", host can be hostname or ip address
tracker_server=192.168.23.152:22122
然后在data目录下创建storage和0文件夹
6.启动 FastDFS,可以看到22122的端口已经启动了,说明搭建成功
[root@localhost ~]# /etc/init.d/fdfs_trackerd start
Starting fdfs_trackerd (via systemctl): [ OK ]
[root@localhost ~]# /etc/init.d/fdfs_storaged start
Starting fdfs_storaged (via systemctl): [ OK ]
[root@localhost 0]# netstat -tlnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22122 0.0.0.0:* LISTEN 4346/fdfs_trackerd
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN 1786/dnsmasq
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1129/sshd
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 1128/cupsd
tcp 0 0 0.0.0.0:23000 0.0.0.0:* LISTEN 4171/fdfs_storaged
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1556/master
tcp6 0 0 :::22 :::* LISTEN 1129/sshd
tcp6 0 0 ::1:631 :::* LISTEN 1128/cupsd
tcp6 0 0 ::1:25 :::* LISTEN 1556/master
[root@localhost 0]#
三:使用C#客户端
在github上有一个C#的客户端,大概可以使用一下:https://github.com/smartbooks/FastDFS.Client 或者通过nuget上搜一下:
![]()
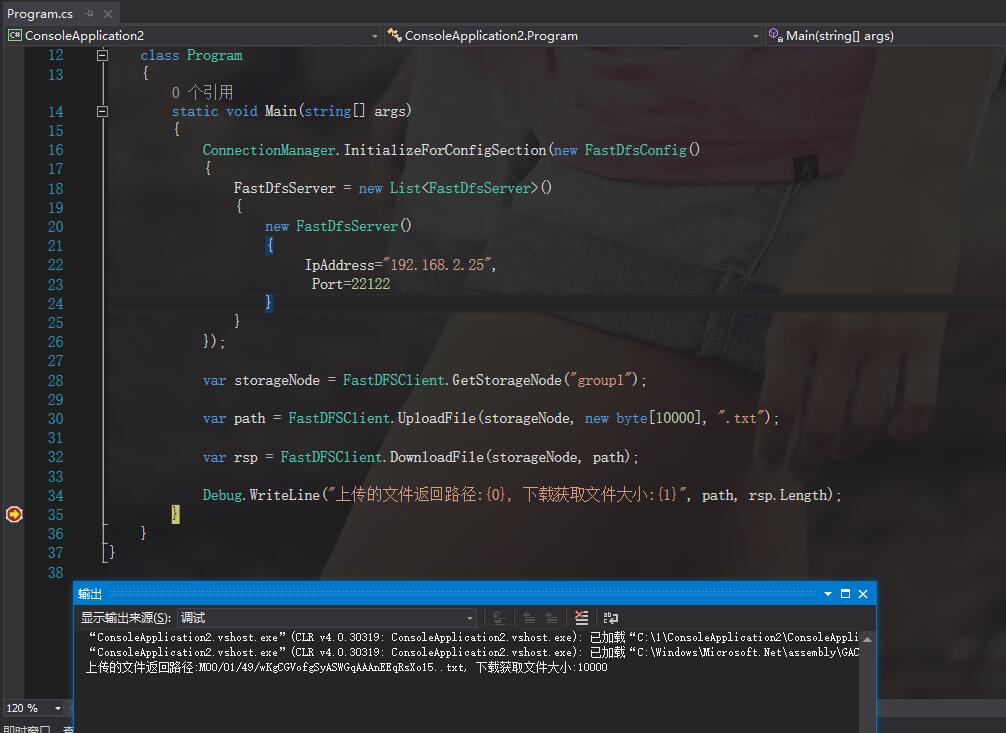
class Program
{
static void Main(string[] args)
{
ConnectionManager.InitializeForConfigSection(new FastDfsConfig()
{
FastDfsServer = new List<FastDfsServer>()
{
new FastDfsServer()
{
IpAddress="192.168.2.25",
Port=22122
}
}
});
var storageNode = FastDFSClient.GetStorageNode("group1");
var path = FastDFSClient.UploadFile(storageNode, new byte[10000], ".txt");
var rsp = FastDFSClient.DownloadFile(storageNode, path);
Debug.WriteLine("上传的文件返回路径:{0}, 下载获取文件大小:{1}", path, rsp.Length);
}
}
![]()
好了,本篇就说这么多了,希望对你有帮助。