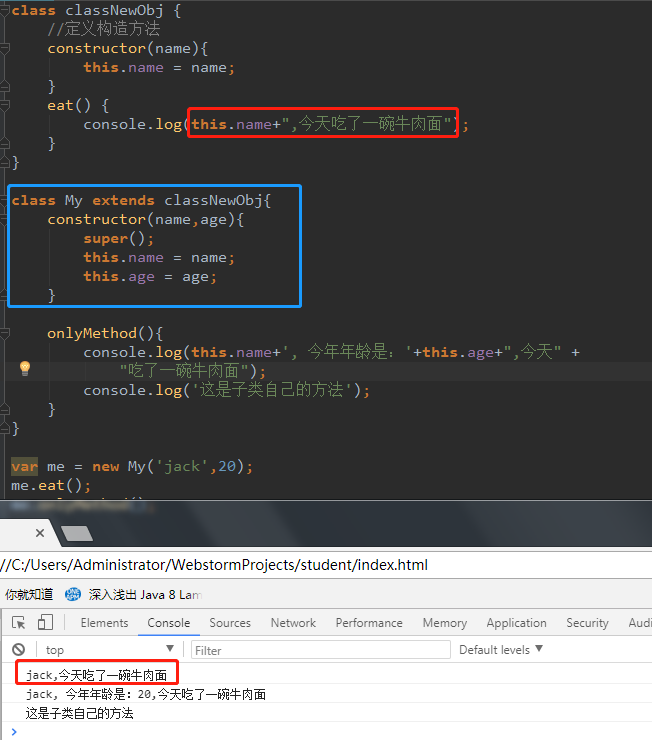

Python——爬虫学习2
BeautifulSoup插件的使用 这个插件需要先使用pip安装(在上一篇中不再赘言),然后再程序中申明引用 from bs4 import BeautifulSoup html=self.requests(url)#调用requests函数把套图地址传入会返回一个response all_a=BeautifulSoup(html.text,'lxml').find('div',class_='all').find('li').find_all('a') 这里find方法只会查找第一个匹配的元素,所以返回的是一个对象,find_all方法会查找所有匹配的元素,所以返回的是list 在使用网页文本的时候用text,在下载多媒体文件的时候用content。 正式编程 这里对程序进行了一些封装,方便函数的复用 ps:不得不感叹,python的io操作真的是很好用,简单方便,敲几下键盘就搞定,比起C#的各种参数真是太简洁!!! import requests from bs4 import BeautifulSoup import os class mzitu(): def __init__...