Hadoop生态系统常用组件导图
Hadoop生态系统主要组件导图: 看大图
之前阅读也有总结过Block的RPC服务是通过NettyBlockRpcServer提供打开,即下载Block文件的功能。然后在启动jbo的时候由Driver上的BlockManagerMaster对存在于Executor上的BlockManager统一管理,注册Executor的BlockManager、更新Executor上Block的最新信息、询问所需要Block目前所在的位置以及当Executor运行结束时,将Executor移除等等。那么Driver与Executor之间是怎么交互的呢?
在Spark1.6时,Drvier的BlockManagerMaster与BlockManager之间的通信,不再是通过AkkaUtil,而是用了RpcEndpoint,也就木有了BlockManagerMasterActor,而是BlockManagerMasterEndpoint:
BlockManagerMaster与BlockManager之间的通信已经使用RPC远程过程调用来实现,RPC相关配置参数如下:
spark.rpc.retry.wait 3s(默认)等待时长 、 spark.rpc.numRetries 3(默认)重试次数、spark.rpc.askTimeout 120s(默认)请求时长、spark.rpc.lookupTimeout与spark.network.timeout 120s(默认)查找时长,是要一起配置。
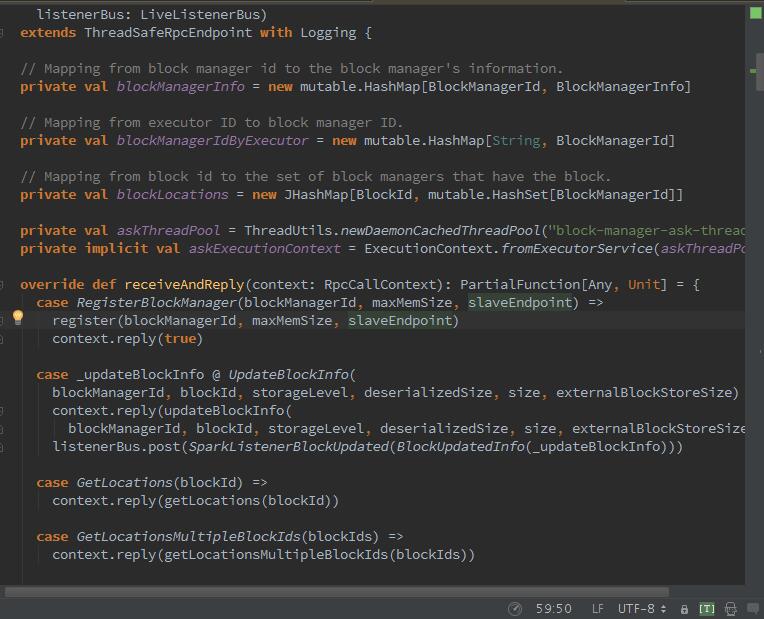
好的,我们继续,每个executor中的BlockManager的创建,都要经过BlockManagerMaster注册BlockManagerId.
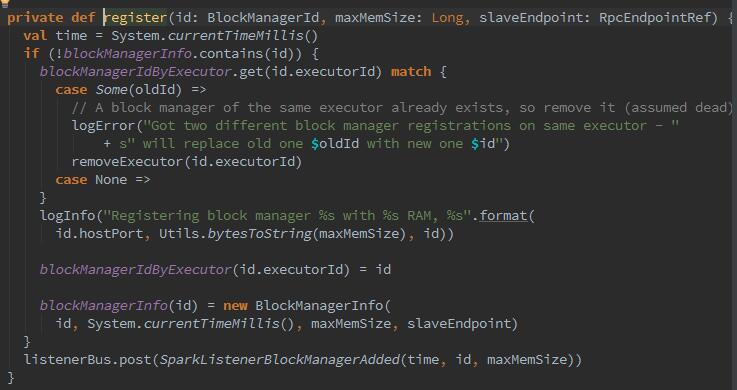
Executor或Driver自身的BlockMnager在初始化时,需要向Driver的BlockManager注册BlockMnager信息,注册的消息内容包括BlockMnagerI的d、时间戳、最大内存、以及slaveEndpoint。带有slaveEndpoint的目的是为了便于接收BlockManagerMaster回复的消息,在register方法执行结束后向发送者BlockManageMaster发送一个简单的消息true.

register方法确保blockManagerInfo持有消息中的blockManagerId及对应消息,并且确保每个Executor最多只能有一个blockManagerId,旧的blockManagerId会被移除。最后向listenerBus中post(推送)一个sparkListenerBlockManagerAdded事件。
那么下来,开始磁盘管理器DiskBlockManager的构造:
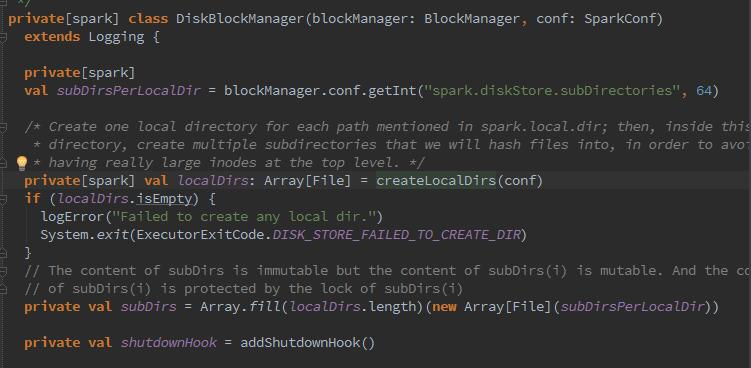
我们可以看到BlcokManager初始化时,创建DiskBlockManager,在创建时,调用了createLocalDirs方法创建本地文件目录,然后创建了二维数组subDirs,用来缓存一级目录localDirs及二级目录,其中二级目录的数量根据配置spark.diskStore.subDirectories获取,默认为64.那么为什么DisBlockManager要创建二级目录?因为二级目录用于对文件进行散列存储,散列存储可以使所有文件都随机存放,写入或删除文件更方便,存取速度快,节省空间。那么我们再细化看下这个磁盘路径是怎么配置的,从哪里来的?
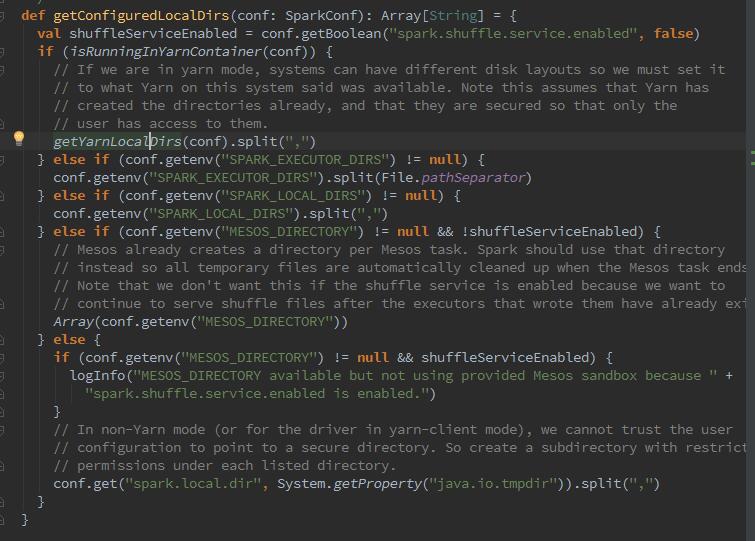
从图中可以看到,这个路径来源于spark.local.dir,但是呢,如果是spark on yarn模式,那么真正的路径是由yarn的配置参数决定的,参数为YARN_LOCAL_DIRS。
接下来查阅源码还会发现有个addShutdownHock()方法,它是干什么的呢,它是用来添加运行时环境结束时,在进程关闭的时候创建线程,通过调用Disk-BlockMnager的stop方法,清除一些临时目录:
下来我们来探索下,是如何获取磁盘文件的?
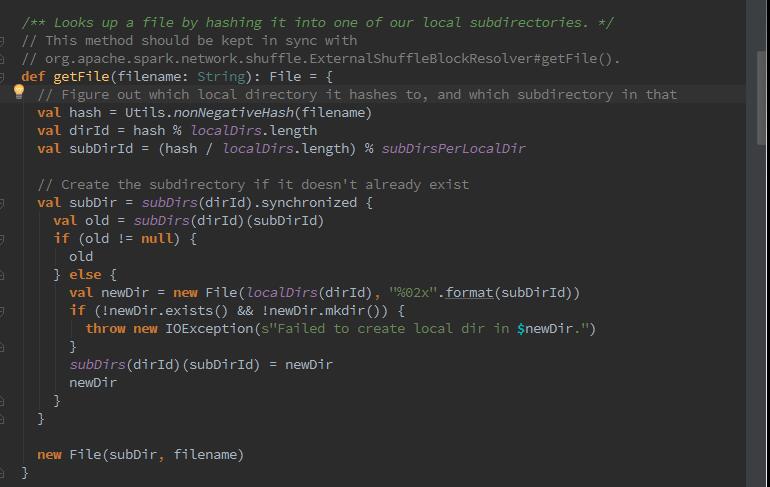
首先我们可以看到,nonNegativeHash方法,该方法用来根据文件名计算哈希值。然后根据哈希值与本地文件以及目录的总数求余数,记为dirId。随后又根据哈希值与本地文件一级目录的总数求商数,此商数与二级目录的数目再求余数,记为subDirId.那么如果dirId/subDirId目录存在,则获取dirId/subDirId目录下的文件,否则创建dirId/subDirId目录。
好的下来我们来创建本地临时文件与shuffle过程的临时文件:
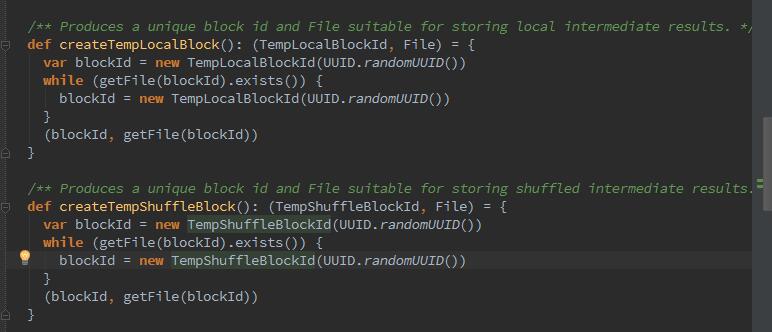
我们可以看到,当MemoryStore没有足够空间时,就会使用DiskStore将块存入磁盘。当ShuffleMapTask运行结束需要把中间结果临时保存,此时就调用了createTempShuffleBlock方法创建临时Block,并返回TempShuffleBlockId与其文件的对偶,同时拼上随机字符串标识。
那么下来,我们再深入了解下MemoryStore,我们在配置spark的时候,会配置计算内存与缓存内存的比例,实质是通过MemoryStore将没有序列化的Java对象数组或者序列化的ByteBuffer存储到内存中,那么MemoryStore是如何构造的呢?
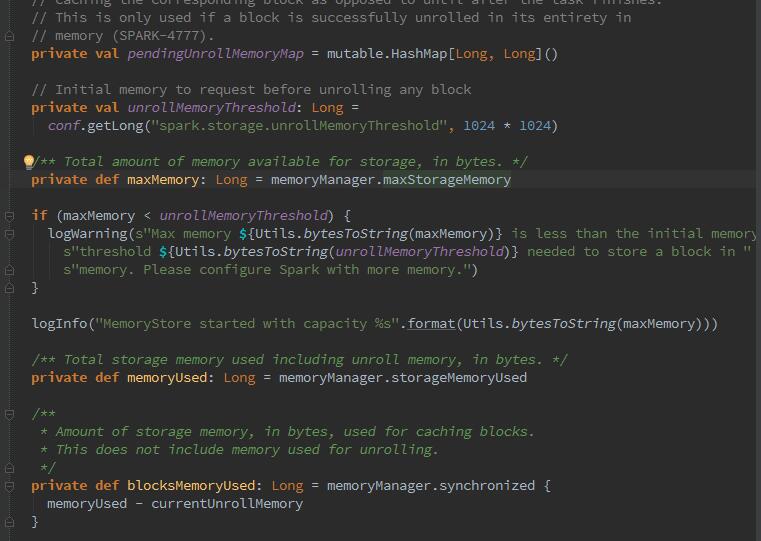
整个MemoryStore的存储分为两块:一块是被很多MemeoryEntry占据的内存currentMemory,这些currentMemory实际上是通过entryes持有的;另一块儿是通过unrollMemoryMap通过占座方式占用的内存currentUnrollMemory.其实意思就是预留空间,可以防止在向内存真正写入数据时,内存不足发生溢出。查阅数据,记录些概念:
-maxUnrollMemory:当前Driver或者Executor最多展开的Block所占用的内存,可以修改spark.storage.unrollFraction的大小。
-maxMemory:当前Driver或者Executor的最大内存。
-currentMemory:当前Driver或者Executor已经使用的内存。
-freeMemory:当前Driver或Executor未使用内存。freeMemoy = maxMemory - currentMemory。
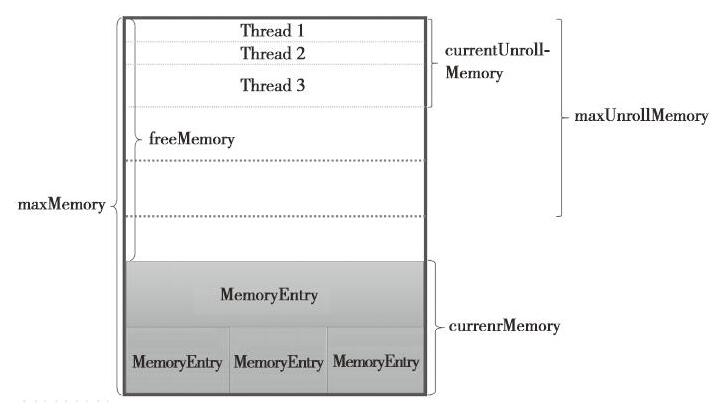
这里有个重要的点,叫做unrollSafely,为了防止写入内存的数据过大,导致内存溢出,Spark采用了一种优化方案,在正式写入内存之前,先用逻辑方式申请内存,如果申请成功,再写入内存,这个过程就跟名字一样了,称为安全展开。
就到这里好了,去吃饭~
参考文献:《深入理解Spark:核心思想与源码分析》

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
马里奥是站在游戏界顶峰的超人气多面角色。马里奥靠吃蘑菇成长,特征是大鼻子、头戴帽子、身穿背带裤,还留着胡子。与他的双胞胎兄弟路易基一起,长年担任任天堂的招牌角色。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Spring框架(Spring Framework)是由Rod Johnson于2002年提出的开源Java企业级应用框架,旨在通过使用JavaBean替代传统EJB实现方式降低企业级编程开发的复杂性。该框架基于简单性、可测试性和松耦合性设计理念,提供核心容器、应用上下文、数据访问集成等模块,支持整合Hibernate、Struts等第三方框架,其适用范围不仅限于服务器端开发,绝大多数Java应用均可从中受益。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273