




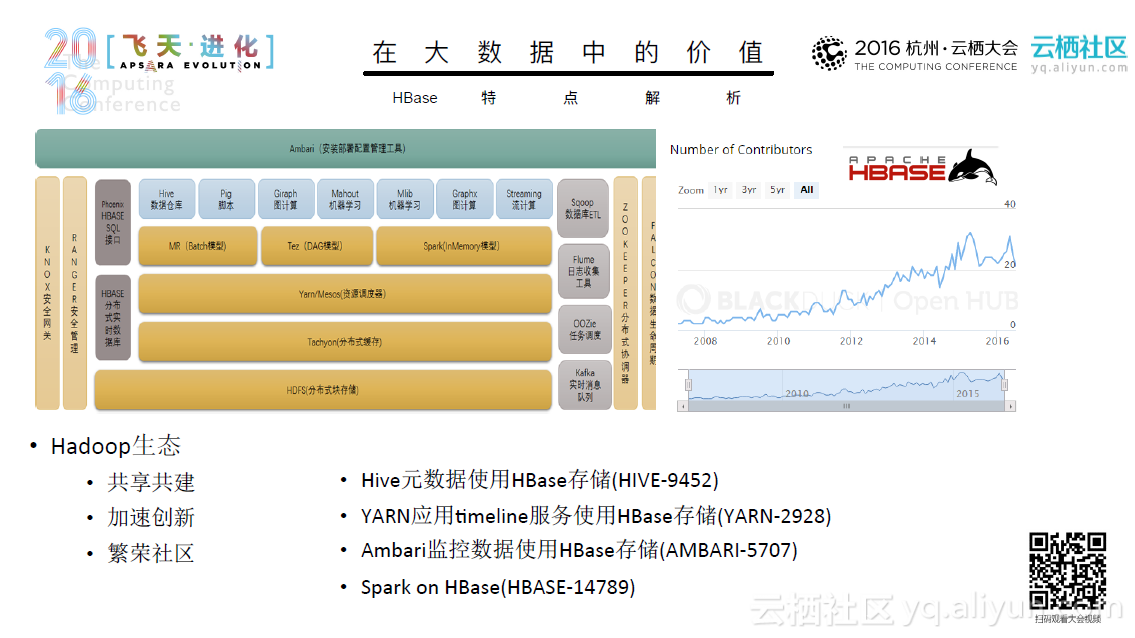
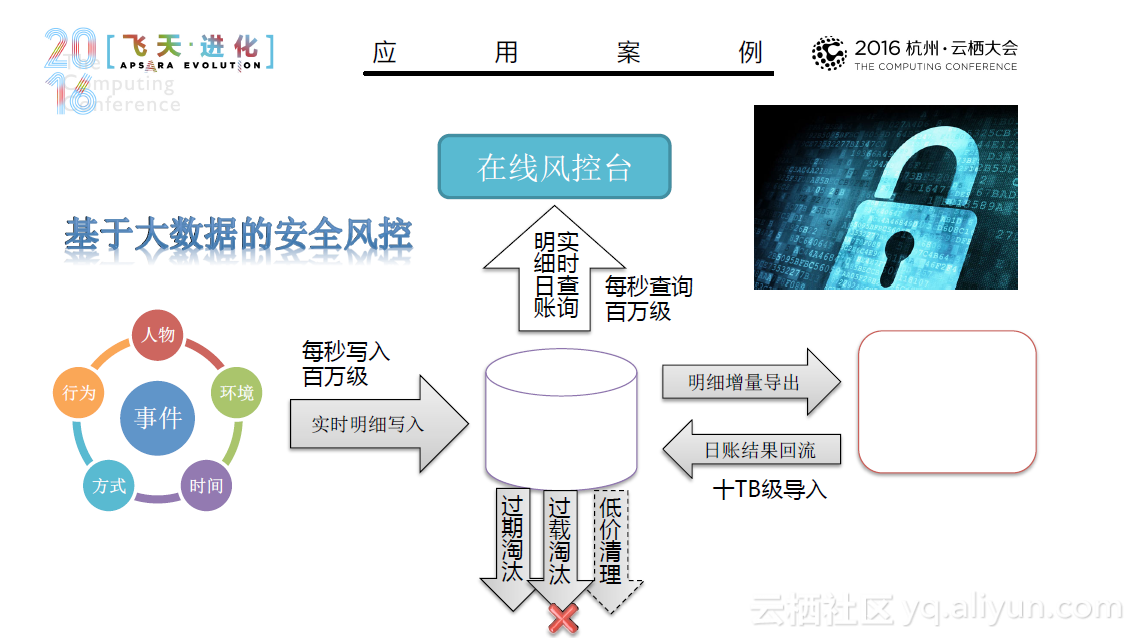
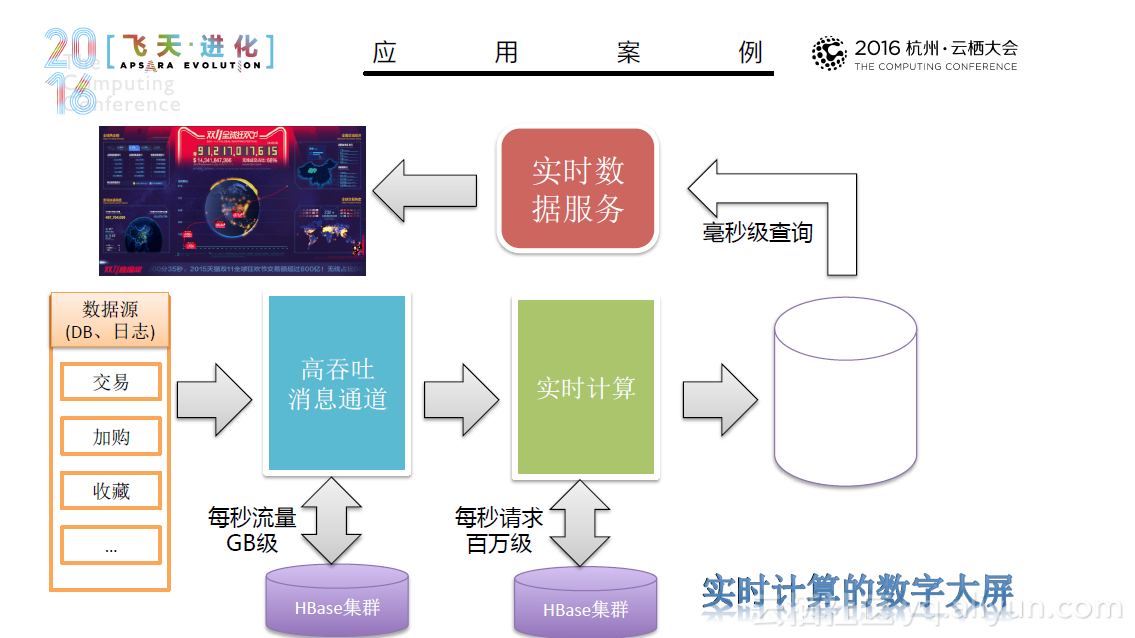
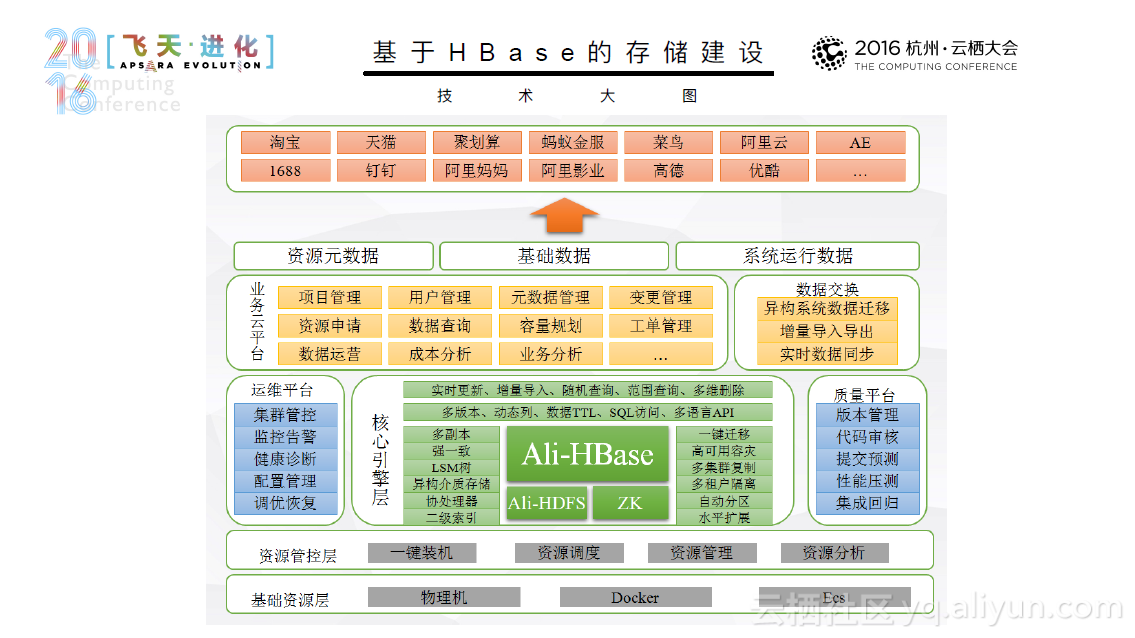
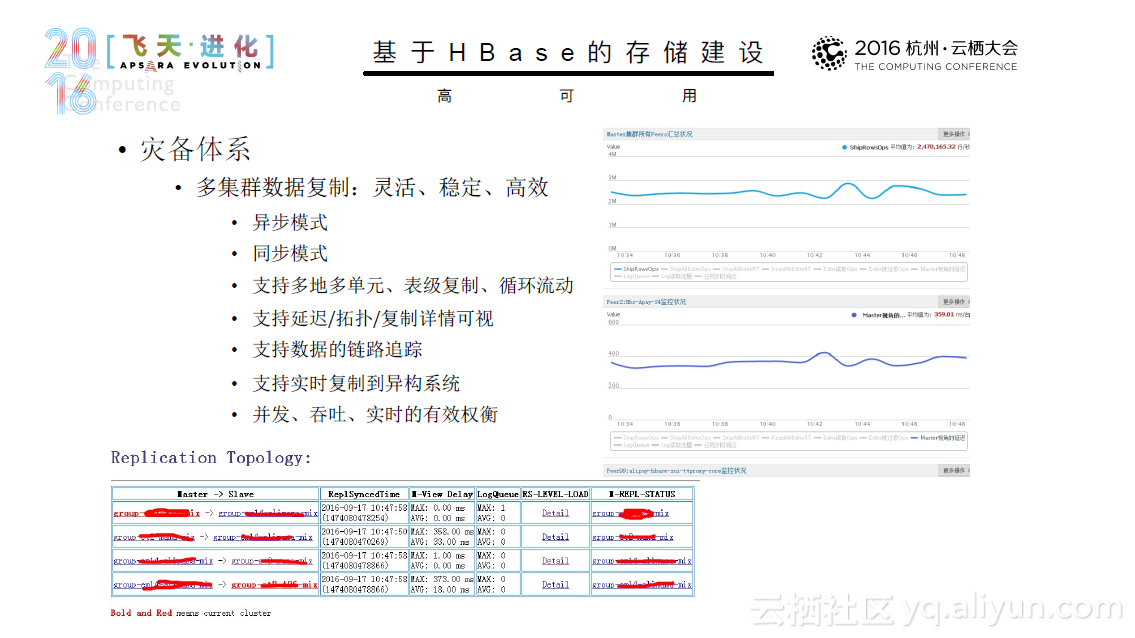

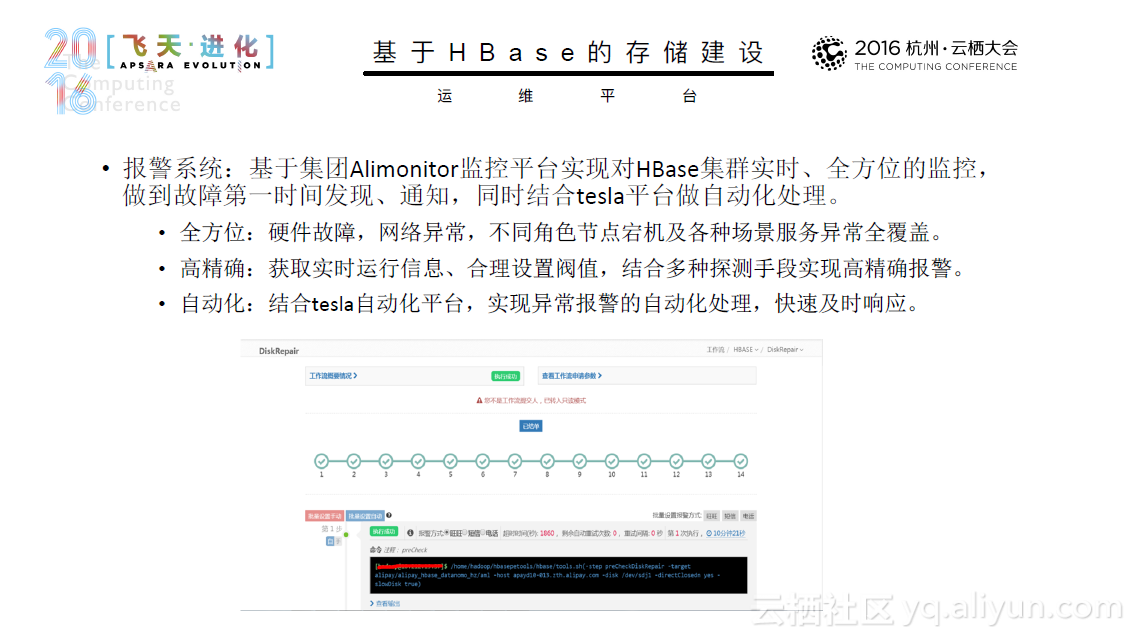


在内存计算时代,看阿里如何用Spark来进行实践与探索
本文PPT来自阿里云技术专家曹龙(花名:封神)于10月16日在2016年杭州云栖大会上发表的《阿里巴巴Spark实践与探索——内存计算时代》。 随着数据爆发式地增长,如何处理大量的数据成为一项挑战。在此背景下,许多数据处理技术应运而生,这其中典型的技术有数据治理、作业管理、分布式计算和分布式储存等等。同时,许多优秀的分布式引擎也被人们开发出来,比如Hadoop、Spark、Flink和 Tez。其中Spark的实力不容小觑。 Spark从1.0到2.0经历了重大的架构变化,其链路和核心得到了不断地完善。同时,Spark在阿里也得到了快速的成长,从10年阿里初步尝试Spark,使用10台机器,利用Spark Mllib进行机器学习,到12年的Spark on Yarn, 规模达到100-400台,使用Spark Streaming、Spark Graphx技术;从14年实现内存计算,到现在发展出了E-MapReduce for Spark,开始对公共云提供服务,这一系列的快速的发展是大家有目共睹的。目前,Spark已经具备了诸多优良的特性,如弹性伸缩、与业务系统无缝结合等等,并且已经被部...