数据
10046,108100000036-IOS,2.4,appStore,34C11930-796E-4F79-892D-D648052C06BF1457624722526,20160310235139299,20160310,376774,f2aa9902e665afe1feceb9502d7bec0ca5acc6fddfd69d1c7eaf5a51503afd78,iPhone,apple,568*320,unknown,4G,unknown,中国移动,unknown,zh-Hans-CN,iOS,9.1,8
10046,108100000036-IOS,2.4,appStore,34C11930-796E-4F79-892D-D648052C06BF1457624722526,20160310234817965,20160310,175440,f2aa9902e665afe1feceb9502d7bec0ca5acc6fddfd69d1c7eaf5a51503afd78,iPhone,apple,568*320,unknown,4G,unknown,中国移动,unknown,zh-Hans-CN,iOS,9.1,8
show tables;
CREATE TABLE IF NOT EXISTS SESSION_10046(appID STRING, appKey STRING, application_ver STRING, channelID STRING, session_id STRING, local_time_string STRING, local_date_string STRING, duration STRING, terminal_id STRING, device_model STRING, device_manufacture STRING, device_resolution STRING, device_cpu STRING, access STRING, access_type STRING, carrier STRING, country STRING, language STRING, os STRING, os_version STRING, timezone STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile;
desc SESSION_10046;
appid string
appkey string
application_ver string
channelid string
session_id string
local_time_string string
local_date_string string
duration string
terminal_id string
device_model string
device_manufacture string
device_resolution string
device_cpu string
access string
access_type string
carrier string
country string
language string
os string
os_version string
timezone string
LOAD DATA LOCAL INPATH '/home/cloudera/baoyou/data/log/10046.log' OVERWRITE into table SESSION_10046
select * from session_10046;
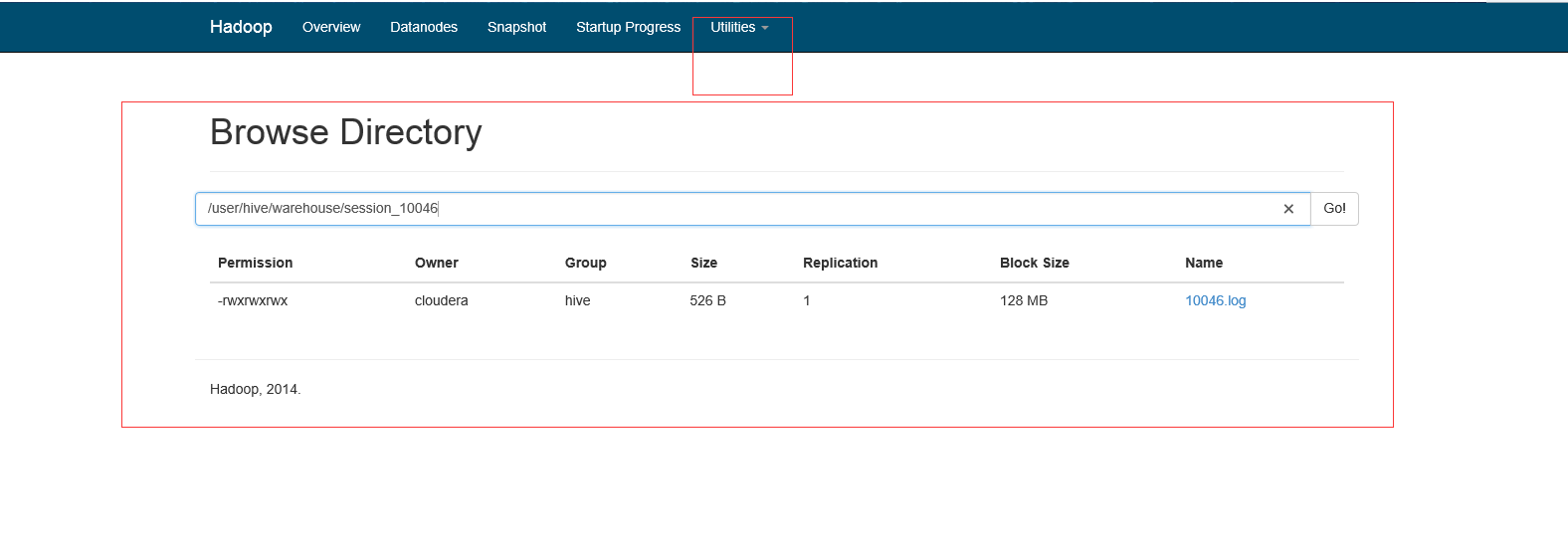
http://quickstart.cloudera:50070/explorer.html#/user/hive/warehouse/session_10046
![]()
hdfs dfs -text /user/hive/warehouse/session_10046/10046.log
10046,108100000036-IOS,2.4,appStore,34C11930-796E-4F79-892D-D648052C06BF1457624722526,20160310235139299,20160310,376774,f2aa9902e665afe1feceb9502d7bec0ca5acc6fddfd69d1c7eaf5a51503afd78,iPhone,apple,568*320,unknown,4G,unknown,中国移动,unknown,zh-Hans-CN,iOS,9.1,8
10046,108100000036-IOS,2.4,appStore,34C11930-796E-4F79-892D-D648052C06BF1457624722526,20160310234817965,20160310,175440,f2aa9902e665afe1feceb9502d7bec0ca5acc6fddfd69d1c7eaf5a51503afd78,iPhone,apple,568*320,unknown,4G,unknown,中国移动,unknown,zh-Hans-CN,iOS,9.1,8
捐助开发者
在兴趣的驱动下,写一个免费的东西,有欣喜,也还有汗水,希望你喜欢我的作品,同时也能支持一下。 当然,有钱捧个钱场(右上角的爱心标志,支持支付宝和PayPal捐助),没钱捧个人场,谢谢各位。
![]()
![]()
![]()
谢谢您的赞助,我会做的更好!