

Flink单机版安装与wordCount
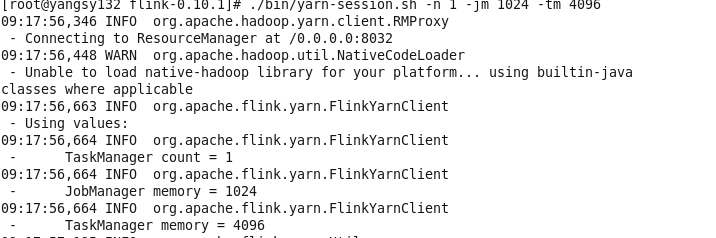
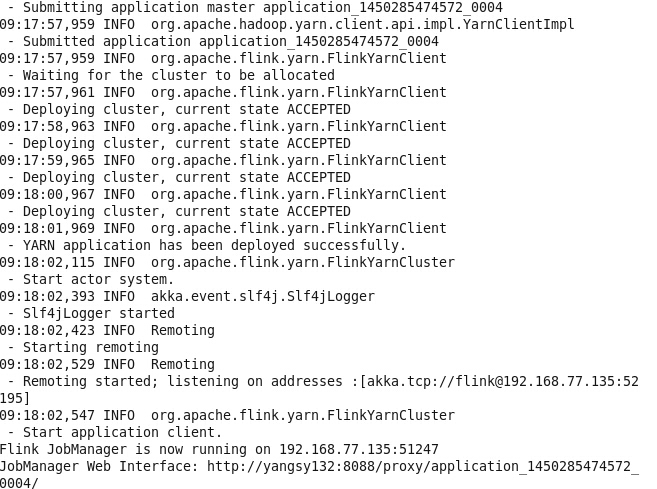
Flink为大数据处理工具,类似hadoop,spark.但它能够在大规模分布式系统中快速处理,与spark相似也是基于内存运算,并以低延迟性和高容错性主城,其核心特性是实时的处理流数据。从此大数据生态圈又再填一员。。。具体详解,还要等之后再分享,这里就先简要带过~ Flink的机制: 当Flink启动时,会拉起一个jobmanager和一个或多个taskManager,jobmanager作用就好比spark中的driver,taskManager的作用就好比spark中的worker. flink源码:http://www.apache.org/dyn/closer.lua/flink/flink-0.10.1/flink-0.10.1-src.tgz 下载与hadoop2.6兼容版本:http://apache.dataguru.cn/flink/flink-0.10.1/flink-0.10.1-bin-hadoop26-scala_2.10.tgz 下载完毕后确定确定配置了jdk java -version 执行bin/start-local.sh 启动local模式 ...