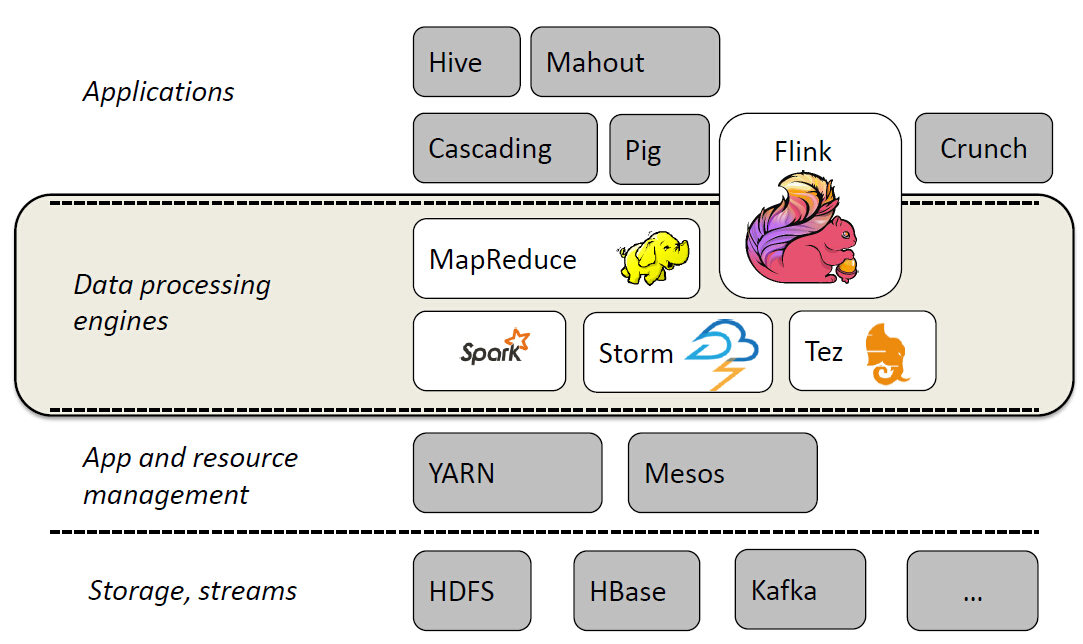
Flink为大数据处理工具,类似hadoop,spark.但它能够在大规模分布式系统中快速处理,与spark相似也是基于内存运算,并以低延迟性和高容错性主城,其核心特性是实时的处理流数据。从此大数据生态圈又再填一员。。。具体详解,还要等之后再分享,这里就先简要带过~
![]()
Flink的机制:
当Flink启动时,会拉起一个jobmanager和一个或多个taskManager,jobmanager作用就好比spark中的driver,taskManager的作用就好比spark中的worker.
![]()
flink源码:http://www.apache.org/dyn/closer.lua/flink/flink-0.10.1/flink-0.10.1-src.tgz
下载与hadoop2.6兼容版本:http://apache.dataguru.cn/flink/flink-0.10.1/flink-0.10.1-bin-hadoop26-scala_2.10.tgz
下载完毕后确定确定配置了jdk
执行 bin/start-local.sh 启动local模式 (conf下默认配置的是localhost 其他参数暂且不必配置)
bin/start-local.sh
tail log/flink-*-jobmanager-*.log
![]()
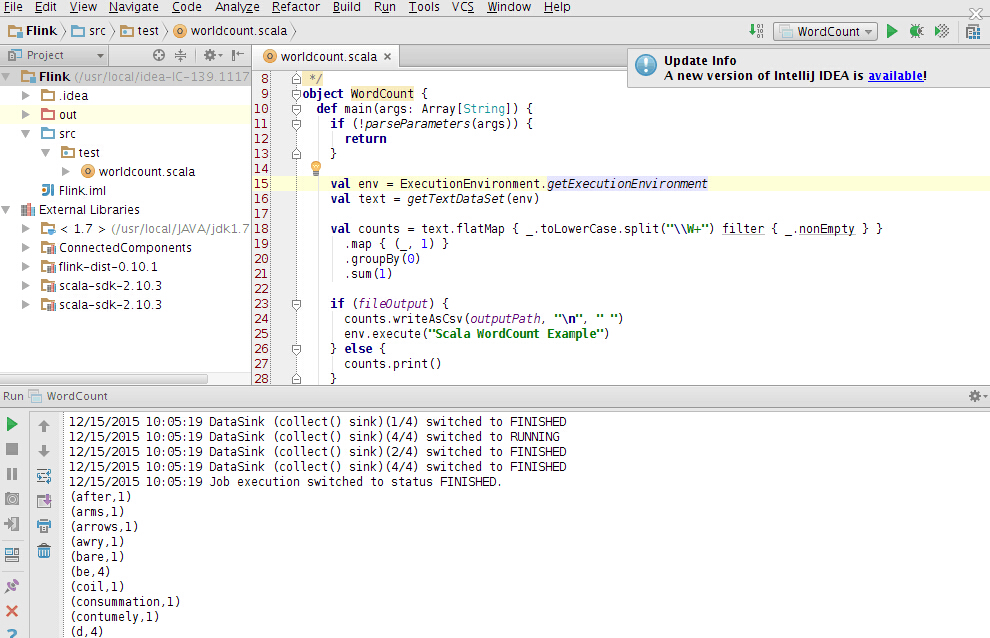
随后可以导入idea 进行wordcount测试 ,这里用官网的example包,记得导入
package test
import org.apache.flink.api.scala._
import org.apache.flink.examples.java.wordcount.util.WordCountData
/**
* Created by root on 12/15/15.
*/
object WordCount {
def main(args: Array[String]) {
if (!parseParameters(args)) {
return
}
val env = ExecutionEnvironment.getExecutionEnvironment
val text = getTextDataSet(env)
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
if (fileOutput) {
counts.writeAsCsv(outputPath, "\n", " ")
env.execute("Scala WordCount Example")
} else {
counts.print()
}
}
private def parseParameters(args: Array[String]): Boolean = {
if (args.length > 0) {
fileOutput = true
if (args.length == 2) {
textPath = args(0)
outputPath = args(1)
true
} else {
System.err.println("Usage: WordCount <text path> <result path>")
false
}
} else {
System.out.println("Executing WordCount example with built-in default data.")
System.out.println(" Provide parameters to read input data from a file.")
System.out.println(" Usage: WordCount <text path> <result path>")
true
}
}
private def getTextDataSet(env: ExecutionEnvironment): DataSet[String] = {
if (fileOutput) {
env.readTextFile(textPath)
}
else {
env.fromCollection(WordCountData.WORDS)
}
运行一下子:
![]()