近期将要购买的书籍
1.Hadoop权威指南 http://product.china-pub.com/194011 2.实战hadoop http://product.china-pub.com/198552#ml 3.Cassandra 权威指南 http://product.china-pub.com/198403 4.lucene http://search.china-pub.com/s/?key1=lucene&type=&pz=1&t=2
google云计算原理与应用
google云计算服务包括:google文件系统GFS,分布式计算编程模形MapReduce,分布式锁服务Chubby,分布式结构化数据表Bigtable,分布式存储系统Megastore以及分布式监控系统Dapper等。
GFS提供了海量数据的存储和访问能力。
GFS
系统架构:
分为三类角色,client(客户端),Master(主服务器)和Chunk Server(数据块服务器)
1,使用的是中心服务器模块,可以任意添加chunk server.
2,不实现缓存,这是从必要性和可行性两方面考虑。
必要性:客户端大部分是流式读写,不存在大量的重复读写。
可行性:如何维护缓存与实际数据之间一致性是一个极其复杂的问题。加之网络等不确定因素,一致性问题尤为复杂。而且数据量非常大,以当前的内存容量根本无法缓存。
而对于存储在GFS的Master中的数据实现了缓存。
3,在用户状态下实现,正常的文件系统是操作系统的重要组成部分,在内核态实现文件系统可以更好的和操作系统本身结合。
但GFS却选择在用户态下实现,主要基于以下考虑:
1)在用户态下直接利用操作系统提供的POSIX编程接口就可以扩展存取数据,无需了解内部的实现接口。
2)POSIX接口提供的功能更为丰富不受内核编程的限制
3)在用户态下有多种调试工具
4)用户态下,Master和Chunk Server都以进程的方式运行,单个进程不会影响整个操作系统
5)在用户态下,GFS和操作系统运行在不同的空间,两者的耦合性降低,方便GFS自身的扩展和升级
4,只提供专有的接口
容错机制:
1,Master容错
1)命名空间也就是整个文件系统的目录结构
2)Chunk与文件名的映射表
3)Chunk副本的位置信息,每一个Chunk默认有三个副本
2,Chunk Server容错
GFS采用副本的方式实现Chunk Server的容错,默认每个副本存储3个
GFS划分的每一个Chunk的默认大小是64MB
系统管理技术:
1)大规模的集群安装
2)故障检测
3)节点动态加入
4)节能
分存式数据处理MapReduce
MapReduce就是“映射”和“化简”的概念和主要思想。
比如查询一个大型文本中各个单词出现的次数,经过Map处理后,形成一批中间结果<单词,出现次数>,而Reduce函数处理中间结果,将相同单词出现的次数累加,得到每个单词出现的次数。
分存式锁服务
Chubby是Google设计的提供粗粒度服务的一个文件系统,它是基于松耦合的分布式系统。
通过使用Chubby的锁服务,用户可以确保数据操作过程中的一致性。
1,Paxos算法
paxos是一种基于消息传送的一致性算法,用于解决分布式中的一致性问题
如何解决分布式中的一致性问题呢,最简单的就是设置一个结点,所有操作都经过这个结点,这样就能保证唯一性的问题。
但是这样缺点也是显而易见的,就是如果结点失效就会出现混乱,所以需要在系统中设置多个这样的结点。
Paxos算法分成三个类型:proposers、acceptors和learners,其中Proposers提出决议,acceptors批准决议,learners获取并使用已经通过的决议。
2,Chubby系统设计
Chubby的设计目标主要有以下几个:
1)高可用性和高可靠性
2)高扩展性
3)支持粗粒度的建议性锁服务
4)服务信息的直接存储
5)支持通报机制
6)支持缓存机制
分存式结构化数据表Bigtable
Bigtable是Google基于GFS和Chubby的分布式存储系统。
Bigtable在很多方面跟数据库类似。
数据模型:
Bigtable是一个分布式的多维映射表,表中数据通过一个行关键字,一个列关键字以及一个时间戳进行索引。Bigtable对存储在其中的数据不做任何解析,一律看成是字符串。
1)行
可以是任意的字符串,但是大小不能超过64K,排序是根据行关键字进行排序的,推荐使用的是字典序
2)列
有列族的概念,族名:限定词(family:qualifier),族名必须有意义,限定词可以任意选定,同族被压缩存储在一起
族同时也是Bigtable中访问控制的基本单元,也就是说访问权限是在族这一级别上进行的
3)时间戳
默认是64位整数
目前提供两种设置,一种是保留最近N个不同的版本,另一种就是保留限定时间内的所有不同版本
系统架构:
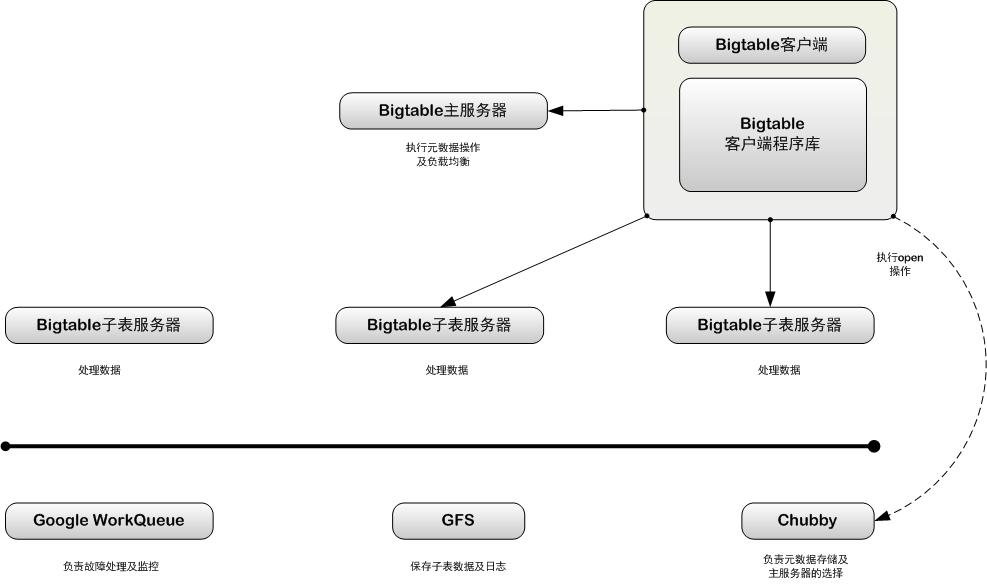
Bigtable主要由三部分组成:客户端程序库(Client Library)、一个主服务器(Master Server)和多个子表服务器(Table Server)
客户端访问Bigtable服务时,首先利用函数库执行open操作打开一个锁,锁打开后客户端就可以跟子表服务器进行通信了。
主服务器的作用:
1)新子表分配
2)子表服务器状态监控
3)子服务器之间的负载均衡
子表服务器:
1)SSTable中的数据被划分成一个个的块(Block),每个块的大小是可以设置的,一般为64KB,在SSTable的结尾有一个索引(Index),在SSTable打开时这个索引会被加载进内存,所以查找的速度会非常快。
每个子表都是由多个SSTable和日志组成
2)子表地址,在Bigtable系统的内部采用的是一种类似B+树的三层查询体系
先查根子表,然后找到元数据子表,最后找到对应的用户表
3)子表的数据存储及读写操作
性能优化
1)局部性群组
2)压缩
3)布隆过滤器
分存式存储系统Megastore
Megastore:关系型数据库和NoSQL的完美结合
设计目标:
1)针对可用性:引入了Paxos算法
2)针对扩展性:采用数据分区将每个分区存放在NoSQL中
megastore的数据模型
通过类似SQL的方式进行查询,有一套对应的查询语言。
Megastore的核心技术-复制
1)复制的日志
2)数据读取 (1)本地查询 (2)发现位置 (3)追赶 (4)验证 (5)查询数据
3)数据写入 (1)接受leader (2)准备 (3)接受 (4)失效 (5)生效
分存式系统的监控基础框架Dapper
分布式监控系统
基本设计目标:
1)低开销
2)对应用层透明
3)可扩展性

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
马里奥是站在游戏界顶峰的超人气多面角色。马里奥靠吃蘑菇成长,特征是大鼻子、头戴帽子、身穿背带裤,还留着胡子。与他的双胞胎兄弟路易基一起,长年担任任天堂的招牌角色。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273