本文已独家授权 鸿洋( hongyangAndroid ) 公众号发布!
前言:
本篇文章主要介绍的是Java(Javaee和Android开发都会涉及)中的线程池。线程池不仅是Java多线程编程的重要基础,而且也是Android面试和Javaee面试中,面试官心血来潮突然向你发难的一道面试题(可能他自己也说不清楚道不明白线程池的概念和应用场景,但他们就是想见你一脸尴尬的表情以此作为压低你工资的筹码)。说到线程池之前,我们首先必须理清楚 线程、并行和并发、多线程的基本概念。
线程池的概念大致理清楚之后,我们在分析OkHttp这一经典网络框架内部的线程池是如何实现的,通过分析源码进一步加深线程池概念。文章一如既往原来的风格,篇幅较长但力争写得详细明白。笔者从开始写到发布花了自己近一周的业余时间。(已对部分内容已进行了删减,初版达到了万字)个人希望看到这篇文章的开发者可以耐心、仔细、慢慢的看完,分段阅读也是较好的选择。
所谓:九层之台、起于垒土 。
另外对本文有任何意见或者觉得文章内容有所不足请在评论区直接提出issue,谢谢。
线程:
说起线程,大家可能都不陌生。线程,是程序执行的最小单元。一个标准的线程由线程ID,当前指令指针,寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。以上概念来自于百度百科。对于开发者来说,线程就是帮我们干实事的伙伴。在Java中,对于线程的基本操作,我们知道在代码中有以下三种写法:
(1)自定义一个类,去继承Thread类,重写run方法
(2)自定义一个类,去实现Runnable接口,重写run方法
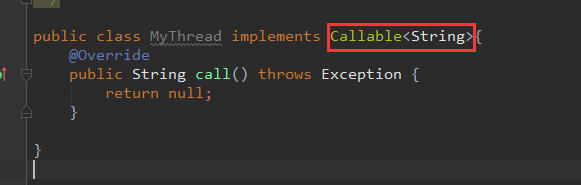
(3)自定义一个类,实现Callable接口,重写call方法。关于这个Callable,要多提一嘴,首先,Callable规定的方法是call(),而Runnable规定的方法是run().;其次,Callable的任务执行后可返回值,而Runnable的任务是不能返回值的;然后,call()方法可抛出异常,而run()方法是不能抛出异常的;最后,运行Callable任务可拿到一个Future对象。
因为线程的基本概念和使用大家基本上都很熟悉,所以这里就点到为止。
关于线程,就不得不提及另外一个经常容易被混淆的概念,那就是并行和并发。
关于并行和并发,我在网上找了一段关于并行和并发的英文资料:
Concurrency is when two tasks can start, run, and complete in overlapping time periods. Parallelism is when tasks literally run at the same time, eg. on a multi-core processor.
Concurrency is the composition of independently executing processes, while parallelism is the simultaneous execution of (possibly related) computations.
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
An application can be concurrent – but not parallel, which means that it processes more than one task at the same time, but no two tasks are executing at same time instant.
An application can be parallel – but not concurrent, which means that it processes multiple sub-tasks of a task in multi-core CPU at same time.
An application can be neither parallel – nor concurrent, which means that it processes all tasks one at a time, sequentially.
An application can be both parallel – and concurrent, which means that it processes multiple tasks concurrently in multi-core CPU at same time.
翻译过来就是:
并发是两个任务可以在重叠的时间段内启动,运行和完成。
并行是任务在同一时间运行,例如,在多核处理器上。
并发是独立执行过程的组合,而并行是同时执行(可能相关的)计算。
并发是一次处理很多事情,并行是同时做很多事情。
应用程序可以是并发的,但不是并行的,这意味着它可以同时处理多个任务,但是没有两个任务在同一时刻执行。
应用程序可以是并行的,但不是并发的,这意味着它同时处理多核CPU中的任务的多个子任务。
一个应用程序可以即不是并行的,也不是并发的,这意味着它一次一个地处理所有任务。
应用程序可以即是并行的也是并发的,这意味着它同时在多核CPU中同时处理多个任务。
看完了这些,可能还是懵懵懂懂。为了彻底理清并行和并发的概念,我找了两幅不错的资料图来帮助我们巩固理解区分并行和并发。
首先是并发:
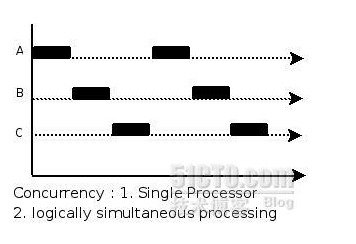
Concurrency,是并发的意思。并发的实质是一个物理CPU(也可以多个物理CPU) 在若干道程序(或线程)之间多路复用,并发性是对有限物理资源强制行使多用户共享以提高效率。
从微观角度来讲:所有的并发处理都有排队等候,唤醒,执行等这样的步骤,在微观上他们都是序列被处理的,如果是同一时刻到达的请求(或线程)也会根据优先级的不同,而先后进入队列排队等候执行。
从宏观角度来讲:多个几乎同时到达的请求(或线程)在宏观上看就像是同时在被处理。
通俗点讲,并发就是只有一个CPU资源,程序(或线程)之间要竞争得到执行机会。图中的第一个阶段,在A执行的过程中B,C不会执行,因为这段时间内这个CPU资源被A竞争到了,同理,第二个阶段只有B在执行,第三个阶段只有C在执行。其实,并发过程中,A,B,C并不是同时在进行的(微观角度)。但又是同时进行的(宏观角度)。
简单说完了并发,我们继续分析并行:
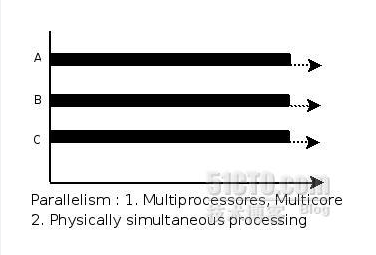
Parallelism,翻译过来即并行,指两个或两个以上事件(或线程)在同一时刻发生,是真正意义上的不同事件或线程在同一时刻,在不同CPU资源上(多核),同时执行。
并行,不存在像并发那样竞争,等待的概念。
图中,A,B,C都在同时运行(微观,宏观)。
关于并行和并发的基本概念大概介绍到这里,如果还觉得不是很好理解,请自行谷歌或者百度查阅资料慢慢消化。
上面简单回顾了下线程、并行和并发的基本概念,下面我们在说说多线程。
首先,什么是多线程?
我们知道,一个任务就是一个线程 ,但实际上,一个应用程序为了同时执行多个任务提供运行效率,一般会涉及到一个线程以上的数量。如果,一个应用程序有一个以上的线程,我们把这种情况就称之为多线程。
本质来说,多线程是为了使得多个线程完成多项任务,以提高系统的效率。目前为止我们使用多线程应用程序的目的是尽可能多地使用计算机处理器资源(本质是为了让效率最大化)。所以,看起来我们仅需要为每个独立的任务分配一个不同的线程,并让处理器确定在任何时间它总会处理其中的某一个任务。但是,这样就会出现一些问题,对小系统来说这样做很好。但是当系统越来越复杂时,线程的数量也会越来越多,操作系统将会花费更多时间去理清线程之间的关系。为了让我们的程序具备可扩展性,我们将不得不对线程进行一些有效的控制。
针对这种情况,开发者通过使用线程池就可以有效规避上述风险。
什么是线程池?
线程池是指在初始化一个多线程应用程序过程中创建一个线程集合,然后在需要执行新的任务时重用这些线程而不是新建一个线程(提高线程复用,减少性能开销)。线程池中线程的数量通常完全取决于可用内存数量和应用程序的需求。然而,增加可用线程数量是可能的。线程池中的每个线程都有被分配一个任务,一旦任务已经完成了,线程回到池子中然后等待下一次分配任务。
为什么要用线程池:
基于以下几个原因在多线程应用程序中使用线程池是必须的:
1. 线程池改进了一个应用程序的响应时间。由于线程池中的线程已经准备好且等待被分配任务,应用程序可以直接拿来使用而不用新建一个线程。
2. 线程池节省了CLR 为每个短生存周期任务创建一个完整的线程的开销并可以在任务完成后回收资源。
3. 线程池根据当前在系统中运行的进程来优化线程时间片。
4. 线程池允许我们开启多个任务而不用为每个线程设置属性。
5. 线程池允许我们为正在执行的任务的程序参数传递一个包含状态信息的对象引用。
6. 线程池可以用来解决处理一个特定请求最大线程数量限制问题。
本质上来讲,我们使用线程池主要就是为了减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务;节约应用内存(线程开的越多,消耗的内存也就越大,最后死机)
线程池的作用:
线程池作用就是限制系统中执行线程的数量。根据系统的环境情况,可以自动或手动设置线程数量,达到运行的最佳效果;少了浪费了系统资源,多了造成系统拥挤效率不高。用线程池控制线程数量,其他线程排队等候。一个任务执行完毕,再从队列的中取最前面的任务开始执行。若队列中没有等待进程,线程池的这一资源处于等待。当一个新任务需要运行时,如果线程池中有等待的工作线程,就可以开始运行了;否则进入等待队列。
说完了线程池的概念和作用,我们再看看代码中的线程池:
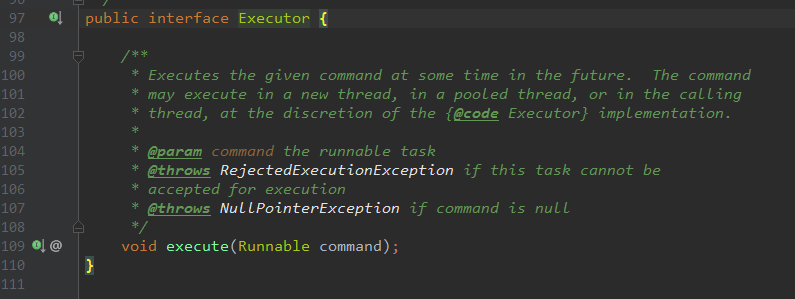
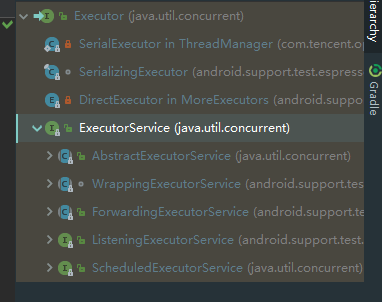
在Java中,线程池的代码起源之Executor(翻译过来就是执行者)注意:这个类是一个接口。
但是严格意义上讲Executor并不是一个线程池(如图其源码就一个 execute 方法),所以Executor仅只是一个执行线程的工具。那么,线程池的真正面纱是什么?利用AS的类继承关系发现,Executor有一个 ExecutorService 子接口。
实际上,一般说线程池接口,基本上说的是这个 ExecutorService。ExecutorService源码里面有各种API(比如说执行 excute ( xxx ),比如关闭 isShutdown ( ))帮助我们去使用。ExecutorService接口的默认实现类为ThreadPoolExecutor(翻译过来就是线程池执行者)。既然是默认实现类我们就可以根据应用场景去私人订制了。
既然找到了突破口,那我们集中火力先去了解下ThreadPoolExecutor
首先从ThreadPoolExecutor 的构造参数开始分析,通过代码截图得知,ThreadPoolExecutor的构造方法有以下4种:
下面就构造方法里面的参数逐一分析说明:
1:int corePoolSize (core:核心的) = > 该线程池中核心线程数最大值
什么是核心线程:线程池新建线程的时候,如果当前线程总数小于 corePoolSize ,则新建的是核心线程;如果超过corePoolSize,则新建的是非核心线程。
核心线程默认情况下会一直存活在线程池中,即使这个核心线程啥也不干(闲置状态)。
如果指定ThreadPoolExecutor的 allowCoreThreadTimeOut 这个属性为true,那么核心线程如果不干活(闲置状态)的话,超过一定时间( keepAliveTime),就会被销毁掉
2:int maximumPoolSize = > 该线程池中线程总数的最大值
线程总数计算公式 = 核心线程数 + 非核心线程数。
3:long keepAliveTime = > 该线程池中非核心线程闲置超时时长
注意:一个非核心线程,如果不干活(闲置状态)的时长,超过这个参数所设定的时长,就会被销毁掉。但是,如果设置了 allowCoreThreadTimeOut = true,则会作用于核心线程。
4:TimeUnit unit = > (时间单位)
首先,TimeUnit是一个枚举类型,翻译过来就是时间单位,我们最常用的时间单位包括:
MILLISECONDS : 1毫秒 、SECONDS : 秒、MINUTES : 分、HOURS : 小时、DAYS : 天
5:BlockingQueue<Runnable> workQueue = >( Blocking:阻塞的,queue:队列)
该线程池中的任务队列:维护着等待执行的Runnable对象。当所有的核心线程都在干活时,新添加的任务会被添加到这个队列中等待处理,如果队列满了,则新建非核心线程执行任务
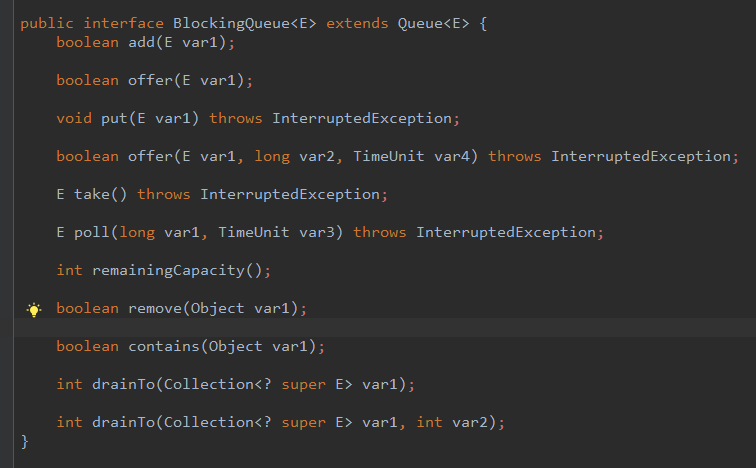
其中,BlockingQueue中具体的API介绍:
offer(E e): 将给定的元素设置到队列中,如果设置成功返回true, 否则返回false. e的值不能为空,否则抛出空指针异常。
offer(E e, long timeout, TimeUnit unit): 将给定元素在给定的时间内设置到队列中,如果设置成功返回true, 否则返回false.
add(E e): 将给定元素设置到队列中,如果设置成功返回true, 否则抛出异常。如果是往限定了长度的队列中设置值,推荐使用offer()方法。
put(E e): 将元素设置到队列中,如果队列中没有多余的空间,该方法会一直阻塞,直到队列中有多余的空间。
take(): 从队列中获取值,如果队列中没有值,线程会一直阻塞,直到队列中有值,并且该方法取得了该值。
poll(long timeout, TimeUnit unit): 在给定的时间里,从队列中获取值,如果没有取到会抛出异常。
remainingCapacity():获取队列中剩余的空间。
remove(Object o): 从队列中移除指定的值。
contains(Object o): 判断队列中是否拥有该值。
drainTo(Collection c): 将队列中值,全部移除,并发设置到给定的集合中。
说完了BlockingQueue常用的API,在说说其常用的workQueue类型:
一般来说,workQueue有以下四种队列类型:
SynchronousQueue:(同步队列)这个队列接收到任务的时候,会直接提交给线程处理,而不保留它(名字定义为 同步队列)。但有一种情况,假设所有线程都在工作怎么办?
这种情况下,SynchronousQueue就会新建一个线程来处理这个任务。所以为了保证不出现(线程数达到了maximumPoolSize而不能新建线程)的错误,使用这个类型队列的时候,maximumPoolSize一般指定成Integer.MAX_VALUE,即无限大,去规避这个使用风险。
LinkedBlockingQueue(链表阻塞队列):这个队列接收到任务的时候,如果当前线程数小于核心线程数,则新建线程(核心线程)处理任务;如果当前线程数等于核心线程数,则进入队列等待。由于这个队列没有最大值限制,即所有超过核心线程数的任务都将被添加到队列中,这也就导致了maximumPoolSize的设定失效,因为总线程数永远不会超过corePoolSize
ArrayBlockingQueue(数组阻塞队列):可以限定队列的长度(既然是数组,那么就限定了大小),接收到任务的时候,如果没有达到corePoolSize的值,则新建线程(核心线程)执行任务,如果达到了,则入队等候,如果队列已满,则新建线程(非核心线程)执行任务,又如果总线程数到了maximumPoolSize,并且队列也满了,则发生错误
DelayQueue(延迟队列):队列内元素必须实现Delayed接口,这就意味着你传进去的任务必须先实现Delayed接口。这个队列接收到任务时,首先先入队,只有达到了指定的延时时间,才会执行任务
说完了BlockingQueue,继续回到ThreadPoolExecutor的构造参数上面
6:ThreadFactory threadFactory = > 创建线程的方式,这是一个接口,new它的时候需要实现他的Thread newThread(Runnable r)方法
7:RejectedExecutionHandler handler = > 这个主要是用来抛异常的
当线程无法执行新任务时(一般是由于线程池中的线程数量已经达到最大数或者线程池关闭导致的),默认情况下,当线程池无法处理新线程时,会抛出一个RejectedExecutionException。
构造参数基本上就介绍完毕了。
(如果看累了就先休息下。。。内容的确较多。。。)
花了这么大篇幅去介绍ThreadPoolExecutor这个类的构造函数,可能你会觉得好累好空虚,好吧,其实我们的付出都是为打通线程池最后的壁垒做的必要准备,因为 千里之行、始于足下 ,我们始终要坚信 倘想达到最高处,就要从低处开始 。
说完了这么多,我们知道了实例化一个线程池,只需要在构造参数里面去添加自己设置的属性值(设置正确即可使用,设置错误即抛异常),这样问题就来了:
一个任务,它是如何进入线程池去执行任务?
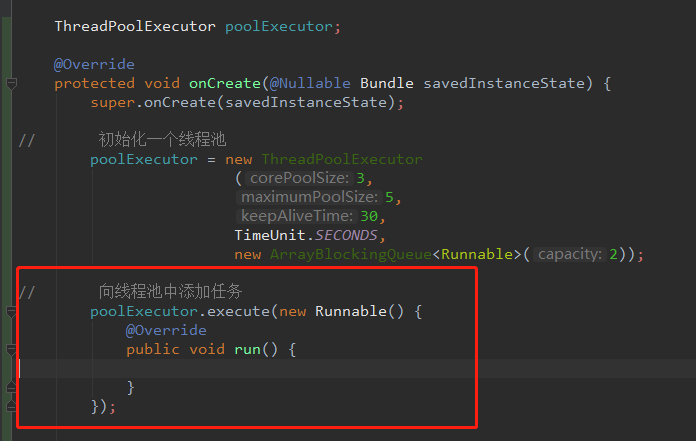
ThreadPoolExecutor这个类,里面有一个API,在上面也随口提到过,有一个执行的方法,先上图
首先我们初始化一个线程池后,即可调用 execute这个方法,里面传入Runnable即可向线程池添加任务。
问题又来了,既然线程池新添加了任务,那么线程池是如何处理这些批量任务?
1:如果线程数量未达到corePoolSize,则新建一个线程(核心线程)执行任务
2:如果线程数量达到了corePools,则将任务移入队列等待
3:如果队列已满,新建线程(非核心线程)执行任务
4:如果队列已满,总线程数又达到了maximumPoolSize,就会由RejectedExecutionHandler抛出异常
但是,实际上,Java已经为我们提供了四种线程池!
好吧,在Java中,Executors这个类已经为我们提供了常用的四种线程池,分别为:
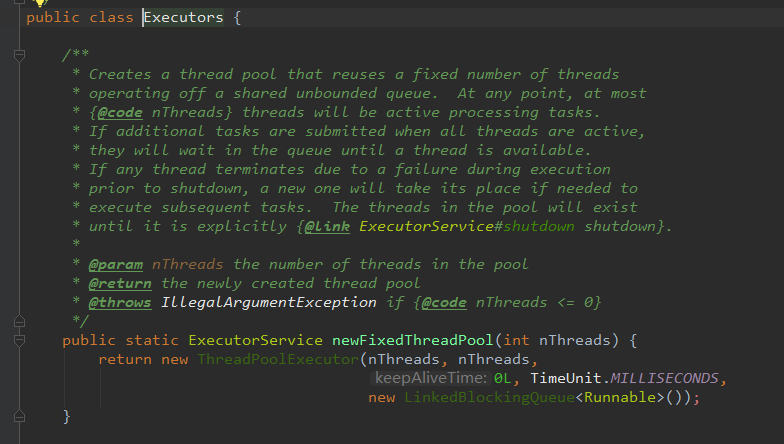
A:newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
源码注释翻译:
创建一个线程池,使用固定数量的线程在共享的无界队列中操作。
在任何时候,有最多 nThreads(就是我们传入参数的数量)的线程将处理任务。
如果所有线程都处于活动状态时,提交额外的任务,他们会在队列中等待,直到有一个线程可用。
如果在执行过程中出现故障,任何线程都会终止。如果需要执行后续任务,新的任务将取代它的位置。线程池中的线程会一直存在,直到它显式为止(调用shutdown)
nThreads 就是传入线程池的数量 ,当nThreads <= 0 就会抛异常IllegalArgumentException
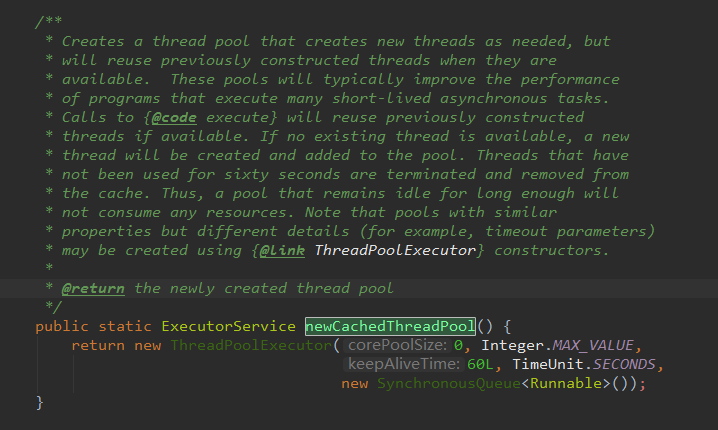
B:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
源码注释翻译:
创建一个线程池,根据需要创建新线程,但是将重写之前线程池的构造。
这个线程池通常会提高性能去执行许多短期异步任务的程序。
如果有可用线程,当线程池调用execute, 将重用之前的构造函数。
如果没有现有的线程可用,那么就创建新的线程并添加到池中。
线程没有使用60秒的时间被终止并从线程池里移除缓存。
因此,一个闲置时间足够长的线程池不消耗任何资源。
注意,线程池有类似的属性,但有一些不同的细节(例如,超时参数)可以使用@link ThreadPoolExecutor构造函数创建。
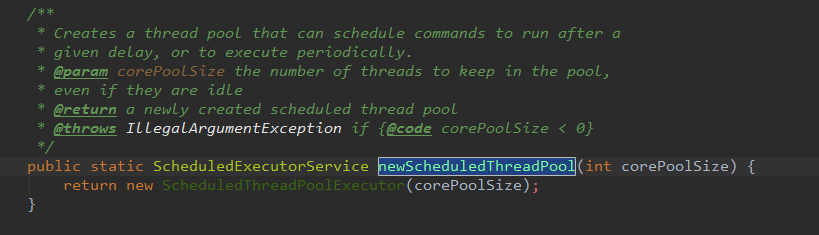
C:newScheduledThreadPool 创建一个定长任务线程池,支持定时及周期性任务执行。
源码注释翻译:
创建一个线程池,它可以安排在 a 之后运行的命令给定延迟,或定期执行。
corePoolSize (这个参数) 是指在池中保留的线程数,即使它们是空闲的。这个函数最终会返回一个新创建的调度线程池
如果 corePoolSize < 0 ,则会抛出 IllegalArgumentException
Ps:这个还支持多传入一个ThreadFactory
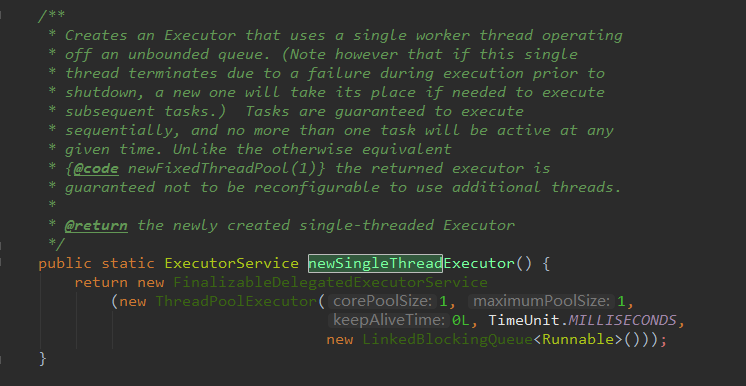
D:newSingleThreadExecutor 创建一个单线程的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
源码注释翻译:
创建一个线程执行器,它使用单个运行中的线程操作在一个无界队列中。
请注意,如果这个单独的线程终止是因为在执行前异常或者终止,若需要执行后续的任务,那么就需要一个新的去替代它。
任务被保证按顺序的执行,并且在任何给定的时间内不超过一个任务将是活动的。
不像其他等价 newFixedThreadPool(1) 这个返回的线程池对象是保证不运行重新配置以使用额外的线程。
最终返回的是一个重新创建的单线程去执行。
总结:
Java为我们提供的四种线程池基本上就介绍完毕了。可以看到,这四种每一个具体的线程池都是 跟 ThreadPoolExecutor 配置有关的。因此,前面花大篇幅介绍ThreadPoolExecutor的构造参数在这里就起到了作用,整体来说,线程池的基本概念就结束了。
下面上一份伪代码加深理解
好了,说完了这么多,我们在回归到Android上面,在Android里面,线程池的应用场景是什么?这个问题面试也经常问(面试常规套路就是,先让你回答Java的某一个知识概念,在让你谈这一知识概念在Android的应用场景)常见的有异步任务栈,(AsyncTask)其内部就是使用到了线程池,关于异步任务栈的线程池这个网上资料就很多了这里就不多说了,我们今天就用上面的概念简单分析讨论下OkHttp这一经典网络框架的内置线程池。
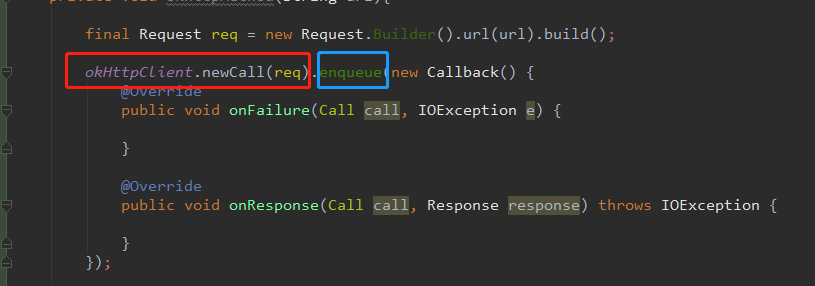
Okhttp的常用写法如下:
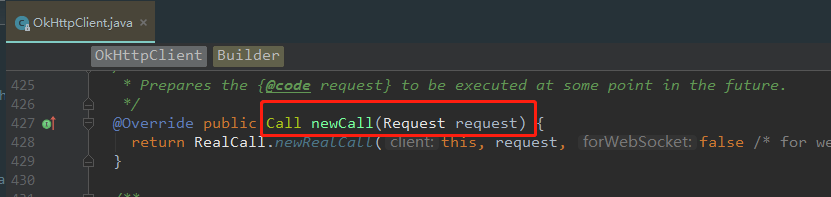
配置好请求体,url之后,我们会使用 OkHttpClient这个对象首先去调用 newCall,也就是上图红色的框框,点进去这个newCall
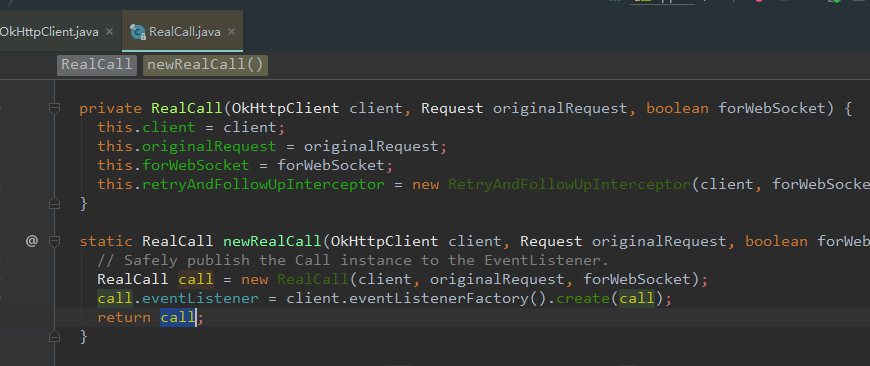
这个方法返回了一个RealCall,翻译过来就是 (真正的请求),点进去看下RealCall
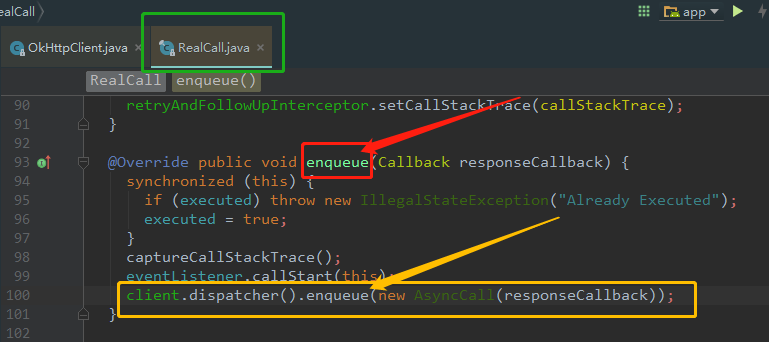
所以,本质上来讲 OkHttpClient.newCall(request).enqueue(), 其实就是调用 RealCall 类里面的 enqueue 方法。如下图
黄色框框里面可以看到,这个方法最终调用的是 client.dispatcher().enqueue,这个方法内部引用了AsyncCall这个对象,那这AsyncCall又是什么?
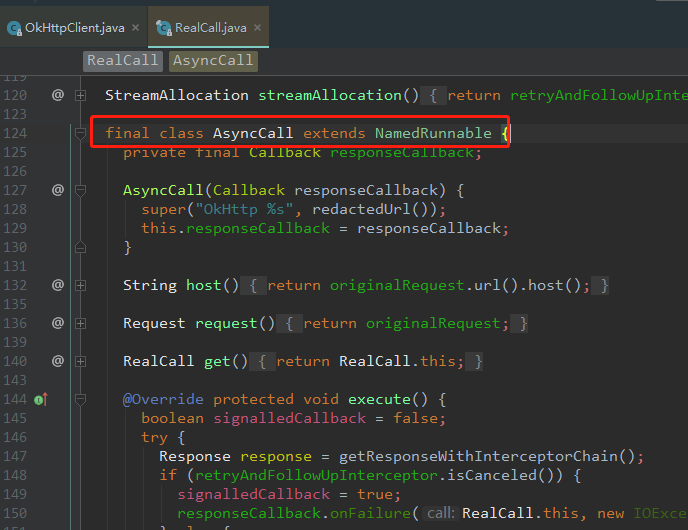
点击AsyncCall后发现,原来,AsyncCall 是 RealCall 的一个内部类(位于:RealCall 源码 124行)
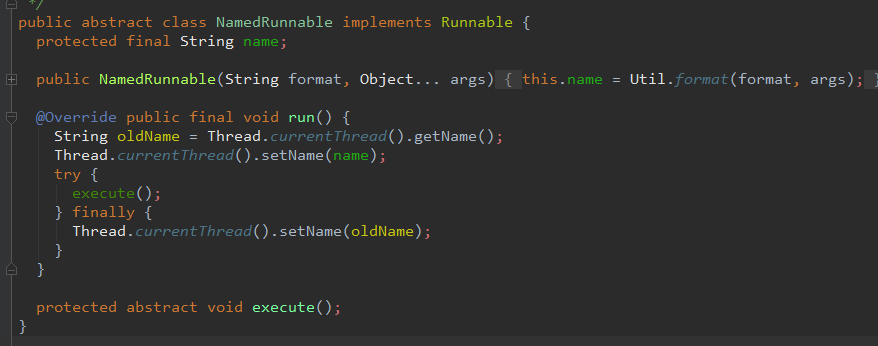
可能你会问, NamedRunnable 这个类又是什么?点进 NamedRunnable后发现,这个类的本质其实就是一个 Runnable
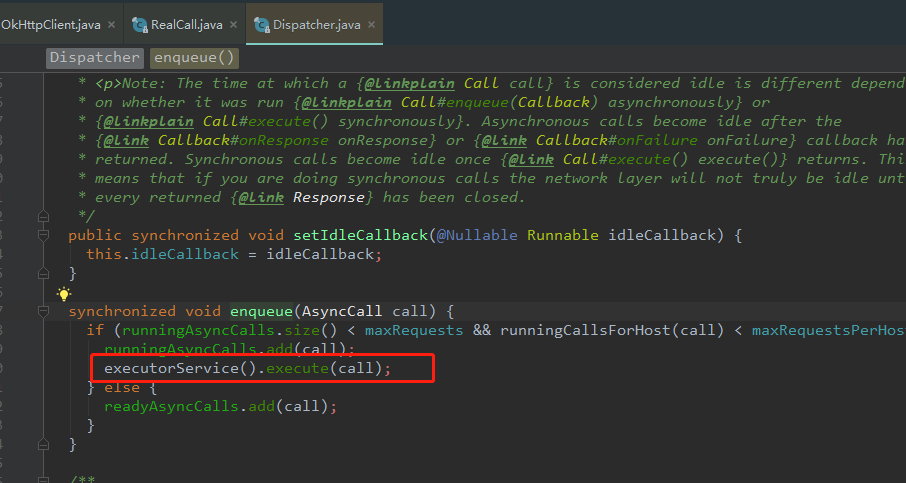
好了,言归正传我们再回到client.dispatcher().enqueue这个方法,点击 enqueue ,进入到了Dispatcher 这个类里面的enqueue方法(Dispatcher 翻译过来就是:调度员、分配器)
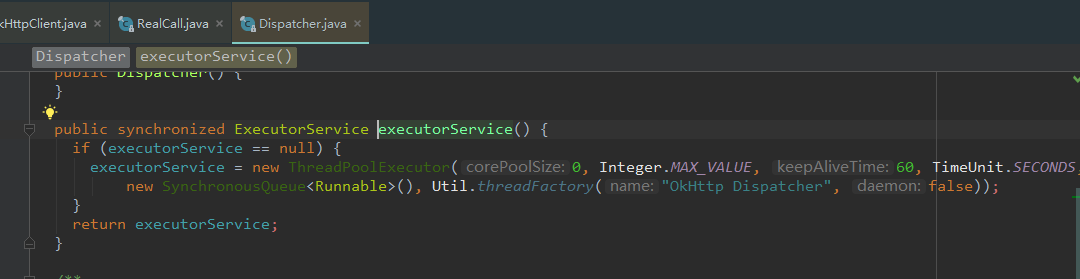
是不是惊奇的看见了executorService().execute(call),是不是感觉有点类似线程池的写法(关于 ExecutorService 这个是文章前面说到的;还有,AsyncCall本质就是一个Runnable对象,线程池里面的execte方法里需要的就是一个Runnable对象),我们继续点击 executorService()这个方法内,看看其庐山真面目
好家伙,是不是看到了熟悉的线程池。如果只是为了应付面试让自己有个概念,看到这里基本上就可以了。因为接下来就开始深挖OkHttp内部线程池细节,内容有点绕,如果愿意深挖的就请继续耐心看完下面的内容。
既然,Okhttp在这里帮我们创建了一个线程池。那么这个线程池是怎么处理的?通过源码得知,构造参数里面有一个SynchronousQueue (同步),这个在上面的构造参数里面也分析过,这个队列接收到任务的时候,会直接提交给线程处理,而且也提到使用这个队列的话,maximumPoolSize一般指定成Integer.MAX_VALUE,即无限大去规避使用风险,在这里,OkHttp的源码也使用到了无限大。
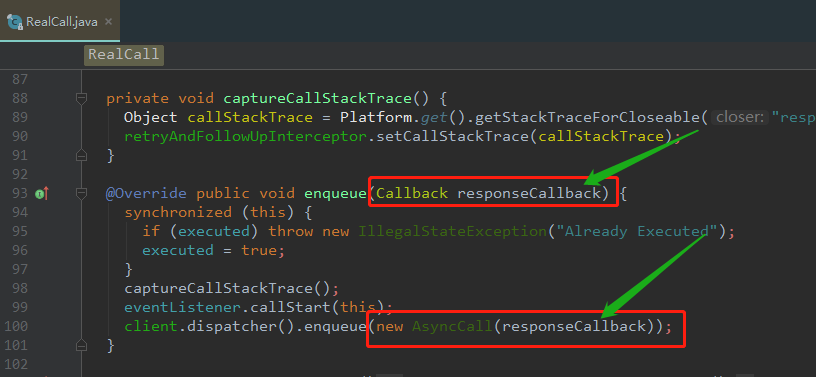
我们知道,okhttp发起请求的步骤真正的执行是在RealCall这个类里面,里面的enqueue方法调用了
client.dispatcher().enqueue(new AsyncCall(responseCallback)) ;(也就是下图第100行)
因此我们在看回去 Dispatcher这个类里面的enqueue方法:
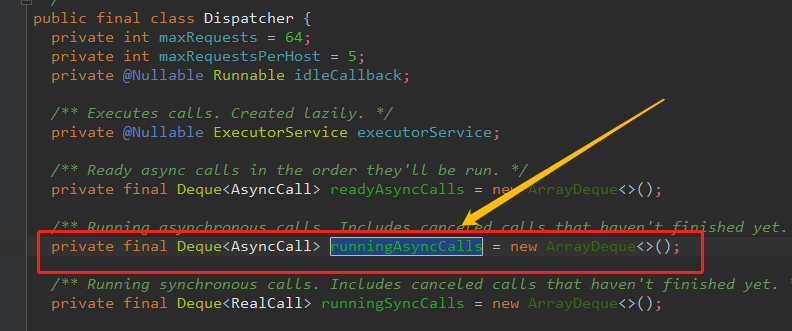
这三个集合简单介绍下:
private final Deque readyAsyncCalls = new ArrayDeque<>() ; // 正在准备中的异步请求队列
private final Deque running AsyncCalls = new ArrayDeque<>(); //运行中的异步请求
private final Deque runningSyncCalls = new ArrayDeque<>(); // 同步请求
拓展:Deque 这个类是什么?简单理解,这个Deque它是Queue的子接口,我们知道Queue是一种队列形式,而Deque则是双向队列,它支持从两个端点方向检索和插入元素(也就是头部和尾部加入元素)
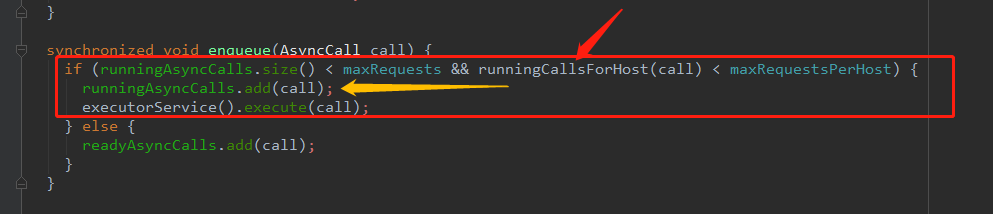
我们继续看下enqueue方法:
在这里有个判断,如果 (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) 如果这个条件不成立的时候,要把任务放在 readyAsyncCalls 里。
问题来了,那么什么时候去取这里的任务来执行呢?
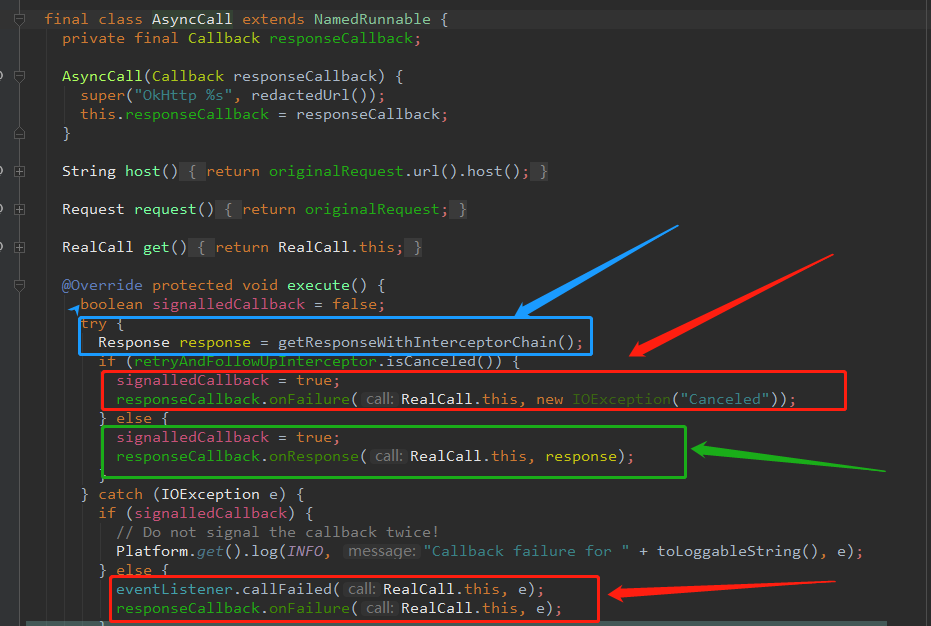
为了解决这个问题,我们需要在回到AsyncCall这个类一探究竟,
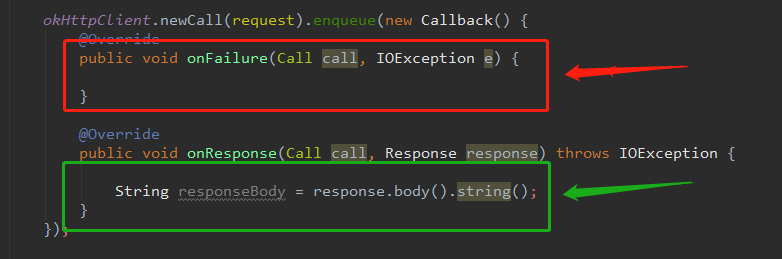
AsyncCall - 1图中,截图了三种不同颜色的矩形,是不是感觉红色和绿色矩形对应的两个方法很熟悉,
responseCallback.onFailure ()实际上就是失败的回调
responseCallback.onResponse ()实际上就是成功的回调,将蓝色矩形的Response对象回调出去。
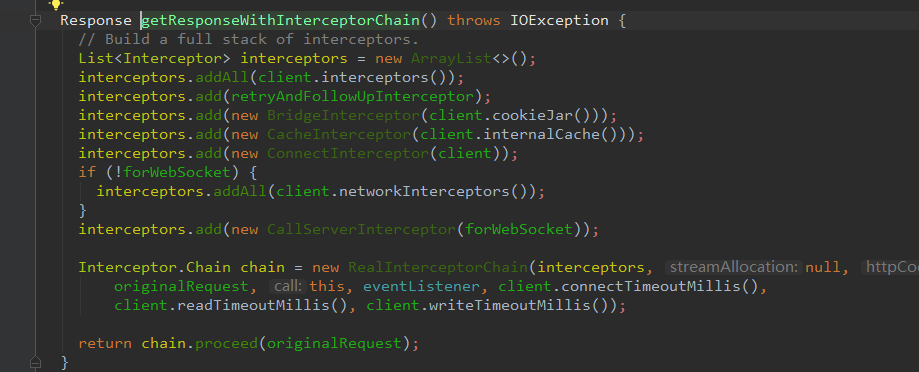
那么蓝色矩形里面的代码是什么意思?getResponseWithInterceptorChain()这个方法具体是做什么的?继续点进源码看看
getResponseWithInterceptorChain
哦,这个方法就是遍历外部定义的拦截器 然后添加OkHttp内部的拦截器去发起真正的请求。拦截器的本质就是拦截请求体,拦截响应体,在拦截的过程中添加信息和修改信息,比如添加请求头等等。由于这个方法涉及到拦截器的源码实在是太多了,想要细看的朋友可以在网上自行查阅资料。所以这里就点到为止。
可以看到,这个方法最终返回了一个Response对象。
回到上面那副AsyncCall - 1图,其中红色和绿色矩形的源码,对应的就是下图OkHttp常规写法,通过接口回调将Response结果,告知调用者,蓝色矩形的response的body,就是我们请求成功之后获取的响应体。
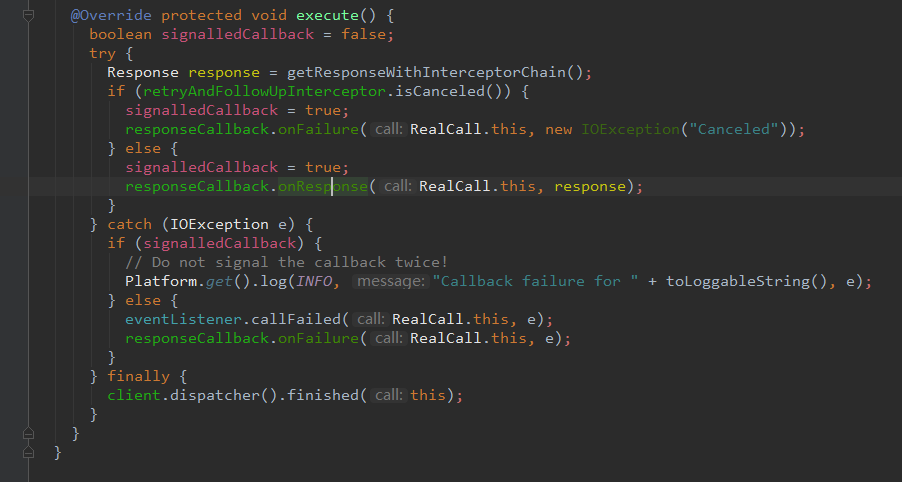
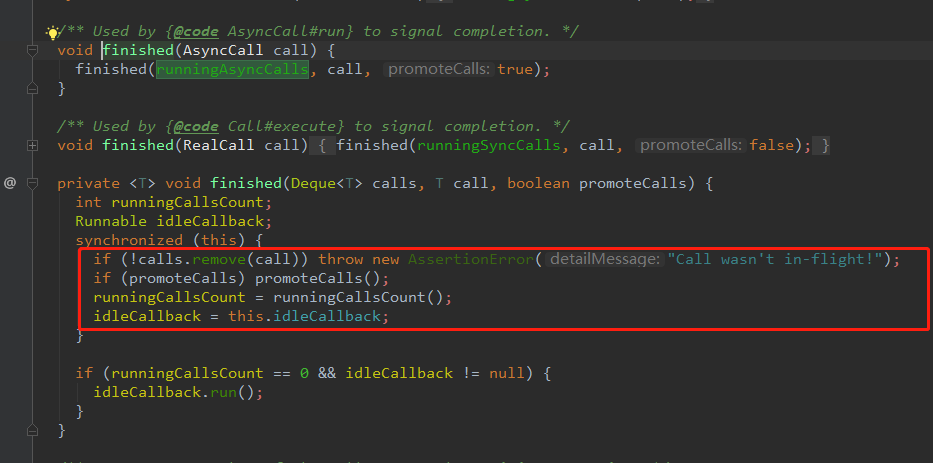
我们看到AsyncCall - 2图中, finally 里面有个结束的处理,也就是 client.dispatcher().finished(this) 这个方法,尝试点进去看
进入到finished方法之后,发现回到了Dispatch这个类里面。这个finished方法 里面貌似能看的,就 promoteCalls 方法和runningCallsCount方法,我们首先看看runningCallsCount方法
发现这个方法其实返回的就是长度(返回值就是int嘛),这不是我们想要的结果。所以继续回到上一步,点击promoteCalls 方法点进去看看
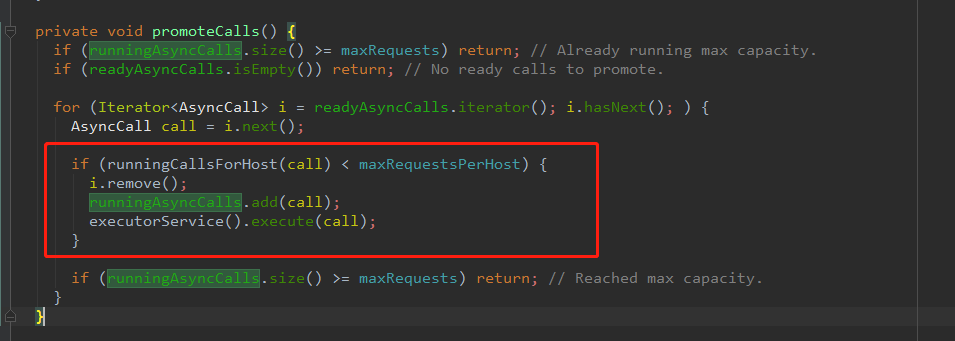
哦,是不是终于看到了 executorService().execute(call) ,将任务添加到线程池里面的具体代码。
这个方法的主要功能是,首先遍历 readyAsyncCalls,把任务取出来;把取出来的任务加入 到runningAsyncCalls;最后, 把任务放入线程池。原来把任务添加到线程池是在Dispatcher这里进行的。(这个类内部不仅创建了线程池,也将任务添加了进来)
总体来说,当请求任务数大于 maxRequests 并且相同 host 最大请求数大于 maxRequestsPerHost,就会把请求任务放在 readyAsyncCalls 队列里;当线程池里执行任务的 runnable 执行完任务在最后会检查 readyAsyncCalls 里有没有任务,如果有任务并且是同一个 host 就放入到线程池中执行。因此通过这个方法不断地从 readyAsyncCalls 队列里取出任务,对线程池里的线程进行复用。
关于Okhttp内置线程池和部分源码的分析就写到这里了,希望对开发者有一点点小帮助吧。如果面试官在问到线程池在Android的实际应用的时候,我们除了说异步任务栈(面试官可能也准备好了异步任务栈让你入坑跟你讨论其内部细节),可以直接跟他谈OkHttp框架内部如何创建线程池、如何将任务添加到线程池等具体的内部实现流程。
如果这篇文章对你有帮助,希望开发者朋友留下一颗宝贵的star,谢谢。
参考资料:https://www.jianshu.com/p/210eab345423
参考资料:https://www.cnblogs.com/miller-zou/p/6978533.html
Ps:著作权归作者所有,转载请注明作者, 商业转载请联系作者获得授权,非商业转载请注明出处(开头或结尾请添加转载出处,添加原文url地址),文章请勿滥用,也希望大家尊重笔者的劳动成果,谢谢。