Apache Flink 1.9.0 已经发布,Apache Flink 项目的目标是开发一个流处理系统,以统一和支持多种形式的实时和离线数据处理应用程序以及事件驱动的应用程序。
此版本包括批处理作业的批处理式恢复,以及新的基于闪烁的表 API 和 SQL 查询引擎的预览,还有状态处理器 API 的可用性,它是最常见的请求特性之一,允许用户使用 Flink DataSet 作业读写保存点。最后,包括一个重新设计的 WebUI 和 Flink 新的 Python Table API 的预览以及它与 Apache Hive 生态系统的集成。
TableAPI & SQL
将 Table 模块进行拆分(FLIP-32,FLIP 即 Flink Improvement Proposals,专门记录一些对Flink 做较大修改的提议),对 Java 和 Scala 的 API 进行依赖梳理,并且提出了 Planner 接口以支持多种不同的 Planner 实现。Planner 将负责具体的优化和将 Table 作业翻译成执行图的工作,我们可以将原来的实现全部挪至 Flink Planner 中,然后把对接新架构的代码放在 Blink Planner 里。
![]()
不仅让 Table 模块在经过拆分后更加清晰,更重要的是不影响老版本用户的体验。在 1.9 版本中,已经 merge 了大部分当初从 Blink 开源出来的 SQL 功能。
![]()
除了架构升级之外,Table 模块在 1.9 版本还做了几个相对比较大的重构和新功能,包括:
-
FLIP-37:重构 Table API 类型系统
-
FLIP-29:Table 增加面向多行多列操作的 API
-
FLINK-10232:初步的 SQL DDL 支持
-
FLIP-30:全新的统一的 Catalog API
-
FLIP-38:Table API 增加 Python 版本
批处理改进
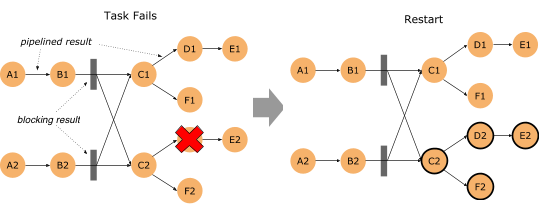
Flink的批处理功能在 1.9 版本有了重大进步,首当其冲的是优化批处理的错误恢复代价:FLIP-1(Fine Grained Recovery from Task Failures),从这个 FLIP 的编号就可以看出,该优化其实很早就已经提出,1.9 版本终于有机会将 FLIP-1 中未完成的功能进行了收尾。
在新版本中,如果批处理作业有错误发生,那么 Flink 首先会去计算这个错误的影响范围,即 Failover Region。因为在批处理作业中,有些节点之间可以通过网络进行Pipeline 的数据传输,但其他一些节点可以通过 Blocking 的方式先把输出数据存下来,然后下游再去读取存储的数据的方式进行数据传输。
如果算子输出的数据已经完整的进行了保存,那么就没有必要把这个算子拉起重跑,这样一来就可以把错误恢复控制在一个相对较小的范围里。
![alt_text]()
如果作业极端一点,在每一个需要Shuffle 的地方都进行数据落盘,那么就和 MapReduce 以及 Spark 的行为类似了。只是 Flink 支持更高级的用法,你可以自行控制每种 Shuffle 是使用网络来直连,还是通过文件落盘来进行。
流处理改进
这个版本增加了一个非常实用的功能,即 FLIP-43(State Processor API)。Flink 的 State 数据的访问,以及由 State 数据组成的 Savepoint 的访问一直是社区用户呼声比较高的一个功能。
这次的 State Processor API 则提供了更加灵活的访问手段,也能够让用户完成一些比较黑科技的功能:
-
用户可以使用这个 API 事先从其他外部系统读取数据,把它们转存为 Flink Savepoint 的格式,然后让 Flink 作业从这个 Savepoint 启动。这样一来,就能避免很多冷启动的问题。
-
使用 Flink 的批处理 API 直接分析State 的数据。State 数据一直以来对用户是个黑盒,这里面存储的数据是对是错,是否有异常,用户都无从而知。有了这个 API 之后,用户就可以像分析其他数据一样,来对 State 数据进行分析。
-
脏数据订正。假如有一条脏数据污染了你的 State,用户还可以使用这个 API 对这样的问题进行修复和订正。
-
状态迁移。当用户修改了作业逻辑,想复用大部分原来作业的 State,但又希望做一些微调。那么就可以使用这个 API 来完成相应的工作。
Hive 集成
在 1.9 版本中,通过 FLIP-30 提出的统一的 Catalog API 的帮助,目前 Flink 已经完整打通了对 Hive Meta Store 的访问。同时,也增加了 Hive 的 Connector,目前已支持 CSV, Sequence File, Orc, Parquet 等格式。用户只需要配置 HMS 的访问方式,就可以使用 Flink 直接读取 Hive 的表进行操作。在此基础之上,Flink 还增加了对 Hive 自定义函数的兼容,像 UDF, UDTF和 UDAF,都可以直接运行在Flink SQL里。
Flink WebUI 修改
组件使用了最新的稳定版本的 Angular。
![]()
发布说明