一、背景
自然语言处理就是要让计算机理解人类的语言,至于到目前为止,计算机是否真的理解的人类的语言,这是一个未知之数,我的理解是目前为止并没有懂得人类语言,只是查表给出一个最大概率的回应而已。那么自然语言处理(NLP)包括哪些领域的东西呢?文本分类(如:垃圾邮件分类、情感分析)、机器翻译、摘要、文法分析、分词、词性标注、实体识别(NER)、语音识别等等,都是NLP要解的问题。那么这些解了这些问题,计算机是否真的懂得人类语言的含义,现在还未知,本片文章不过多的展开讨论。语言的单位是词,那么计算机是如何来表示词的,用什么技术来表示一个词,就可以让计算机理解词的含义呢?本篇博客将进行详细的讨论,从bool模型,到向量空间模型、到各种word embedding(word2vec、elmo、GPT、BERT)
二、原始时代
在Deeplearning之前,表示一个词,并没有一个约定俗成的办法,如何表示,取决于想解决的任务。
1、Bool模型
下面有两句话,求文本相似度。
我喜欢张国荣
你喜欢刘德华
那么,布尔模型比较简单粗暴,出现了词所在维度为1,没出现的所在维度为0,如下图:
![]()
然后求两个向量的cosine即可。
在bool模型中,由于特征值只有1和0两个取值,不能很好的反应特征项在文本中的重要程度。
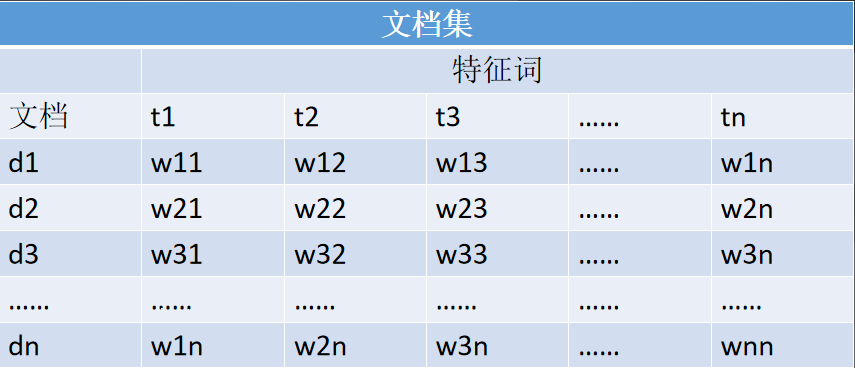
2、VSM(向量空间模型)
Bool模型其实可以看做是VSM的特例,只不过VSM每个维度填进去的值是用了一些特殊的规则处理罢了,VSM如下图:
![]()
t表示特征项,d表示一个Document,那么D可表示为D={t1,t2,t3……tN}的N维向量,w的值怎么填呢?只好的做法是TF*IDF,TF表示词频、IDF表示反词频,公式如下:
TF(t)=特征词在文档中出现次数/文档总词数
IDF(t)=log(N/(n+1)),其中N为文本集文本总数,n为包含特征词t的文档数量
当然TF*IDF也有他的缺陷,忽略了类中分布情况和忽略了类间分布情况,那么也有一些改进,例如:TF*IDF*IG,IG表示信息增益。
这些词/文档的表示方法,非常机械,反映不出词与词之间的上下文之间的关系、相似的关系等等。
三、深度学习时代
首先不得不提语言模型,语言模型在估测一个句子出现的概率,概率越大,越合理。
P(w1,w2,w3,……wn)=P(w1)*P(w2|w1)*P(w3|w1,w2)...P(wn|w1,w2....wn-1)
通常上面的式子没办法估测,于是会做一个马尔科夫假设,假设后面的词只和前面的一个词有关,那么就简化为下面的式子:
P(w1,w2,w3,……wn)=P(w1)*P(w2|w1)*P(w3|w2)...P(wn|wn-1)
当然也可以假设后面的词和前面的N个词有关,这就是常说的N-gram。语言模型在elmo和gpt中有大用处。
1、word2vec
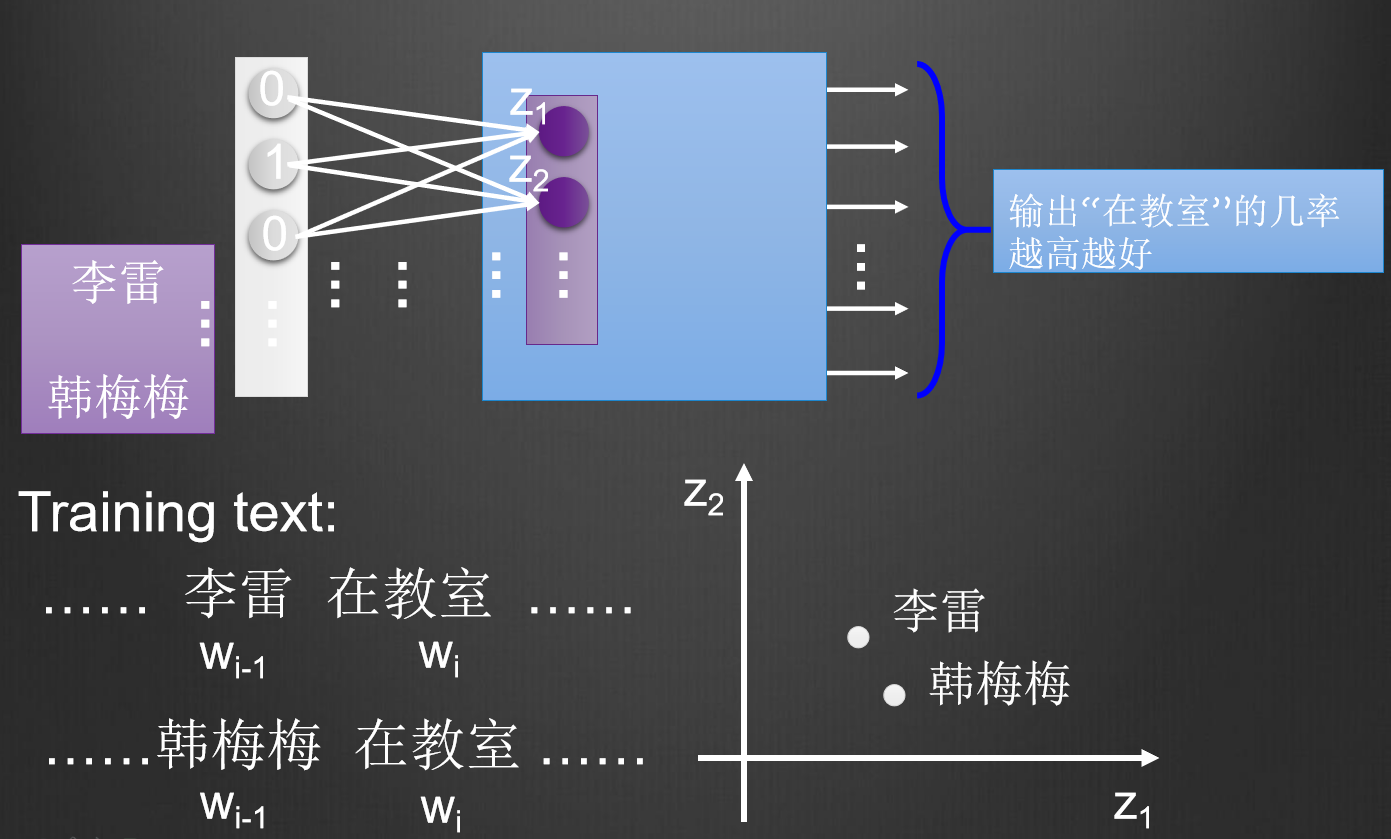
word2vec,其实是一个单隐层的神经网络,的思想很简单,请看下图
![]()
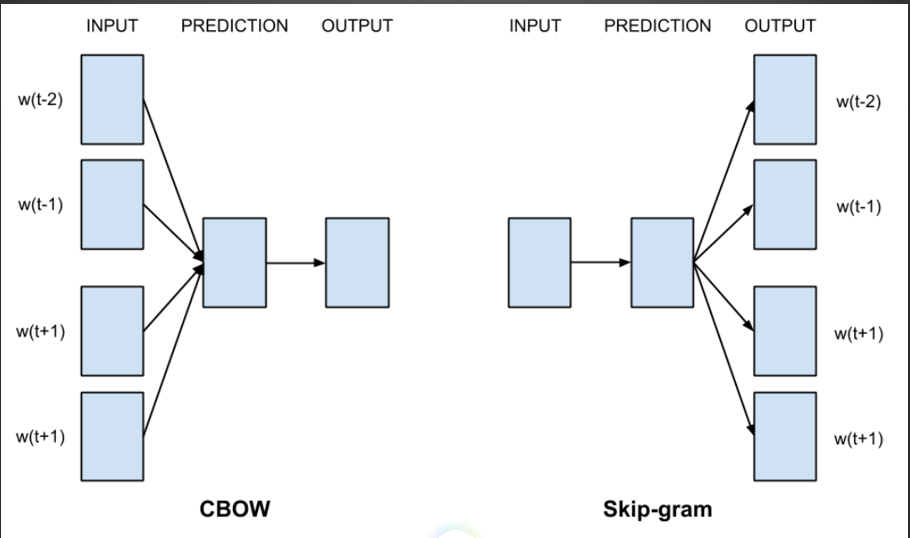
上图中李雷和韩梅梅,都跟着“在教室”这个词,当向神经网络输入李雷或者韩梅梅,希望神经网络output“在教室”这个词的几率越高越好,那么神经网络的权重进行调节,把两个不同的词映射到了相同的空间,那么说明李雷和韩梅梅存在某种联系,这就是word2vec的思想。word2vec有两种,cbow和skip-gram,cbow是由上下文推出一个词,skip-gram是由一个词推出上下文,如下图所示。我实践的结果是cbow效果要更好一点。
![]()
这个代码怎么实现呢?其实自己实现一个单隐层的神经网络就搞定了,output层激活函数为softmax,用cross entropy Loss,梯度下降即可。事实上,我们完全不用这么麻烦,DL4J已经提供了全套解决方案,几行代码就搞定了,代码如下:
Word2Vec vec = new Word2Vec.Builder()
.minWordFrequency(5)
.iterations(1)
.layerSize(100)
.seed(42)
.windowSize(5)
.iterate(iter)
.tokenizerFactory(t)
.build();
vec.fit();
2、ELMO
ELMO取至Embeddings from Language Model的首写字母,论文地址:https://arxiv.org/abs/1802.05365
Embeddings 是从语言模型中得到的。在讲ELMO之前,先来说说word2vec有什么问题,word2vec固然可以表示词与词之间的语义以及相互之间的关系,但是word2vec是一个完全静态的,也就是把所有信息都压缩到一个固定维度的向量里。那么对于一词多意,是表现力是比较有限的。请看下面的例子,
在 “欲信大义于天下”中 ,“信”是动词,“伸张”的意思
在 “信义著于四海"中,“信”是名词,“信用”的意思
如果“信”字压缩成一个100维的向量,将很难区分这两种意思的差别,那么这就需要Contextualized Word Embedding,根据不同的语境,对词进行编码,于是ELMO来了。
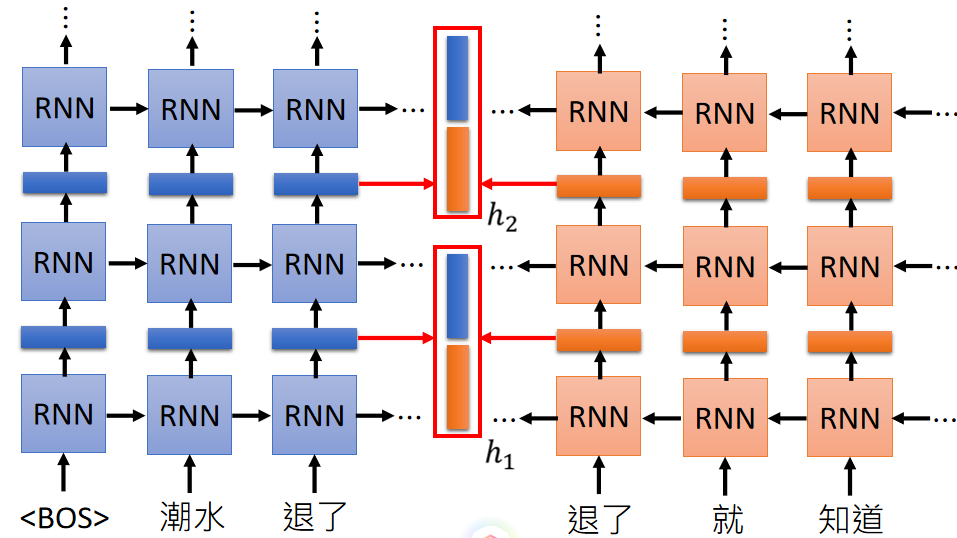
EMLO的结构很简单,用了双向的LSTM来训练一个语言模型。如下图(图片来至于台大李宏毅的ppt)
![]()
模型training的过程很简单,读入一个词,一词下一个词,反向读一个词,预测上一个词,以此训练下去,直到收敛。中间红框处的蓝色和橙色的向量就是Embedding的向量,最后接起来就是我们所要的向量了,当然这个bi-lstm也可以叠很多层。每一层都得到一个Embedding向量。
![]()
那么,使用的时候怎么用这个编码值呢?这取决于下游任务,比方说可以把每一层的Embedding向量求和取平均,或者加权求和等等,这个权重可以跟着任务一起train出来。
3、GPT
ELMO实现了对word进行动态编码,但是他用了LSTM,LSTM并不能记住很长的信息,且不利于并行计算。GPT用self attention改变这一结果,当然这一切得益于google神作《Attention Is All You Need》论文地址:https://arxiv.org/pdf/1706.03762.pdf
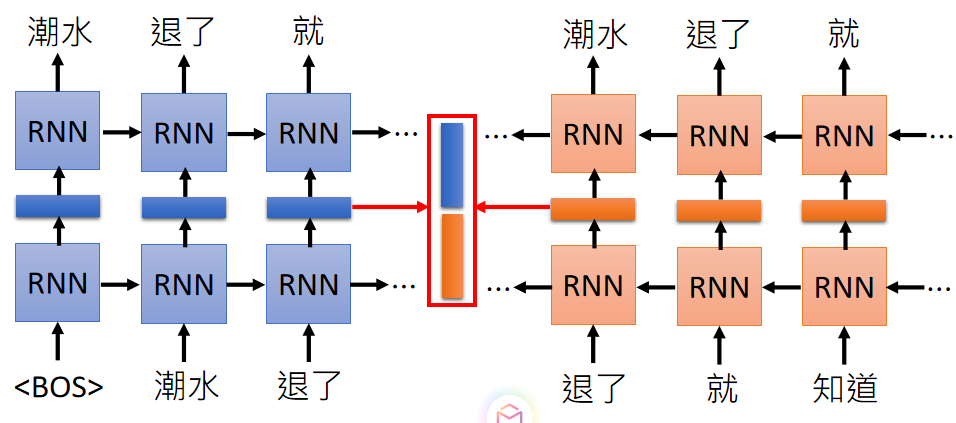
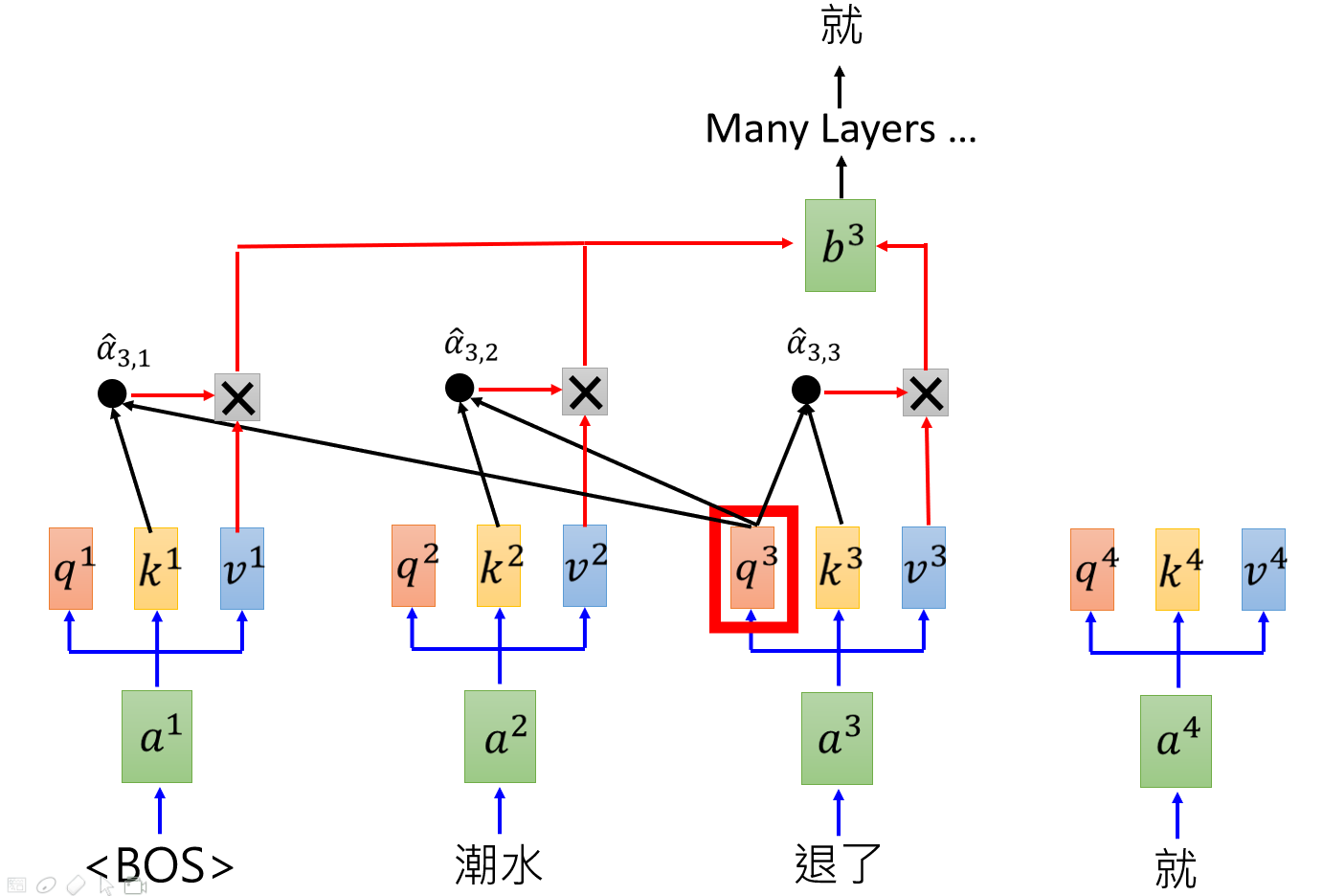
GPT是怎么样的运作流程呢?其实就是用self attention训练一个语言模型,请看下图:
![]()
每个词之和前面的词做attention,预测下一个词,例如读入开始标记BOS,然后自己和自己做attention,预测“潮水”,读入BOS、潮水,然后和BOS、潮水做attention,预测“退了”,类推下去,直到结束。在很多语料上train下去,就得到了一个非常强大的语言模型,可以动态的进行编码。使用的时候可以固定住这些attention层的参数,然后训练其他的下游任务,例如做情感分类问题,可以把这些attention层放在几个全连接层前面,固定参数,只训练后面的全连接层,通过softmax或者sigmoid进行分类。
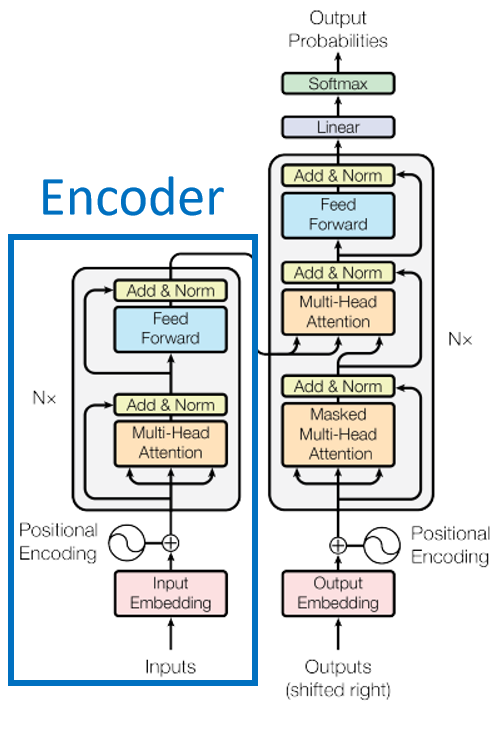
4、Bidirectional Encoder Representations from Transformers (BERT)
GPT有个缺陷,就是编码只依赖上文信息,没有加入下文信息,那么BERT很好的解决了这个问题。BERT其实是transformer的encoder部分,如下图
![]()
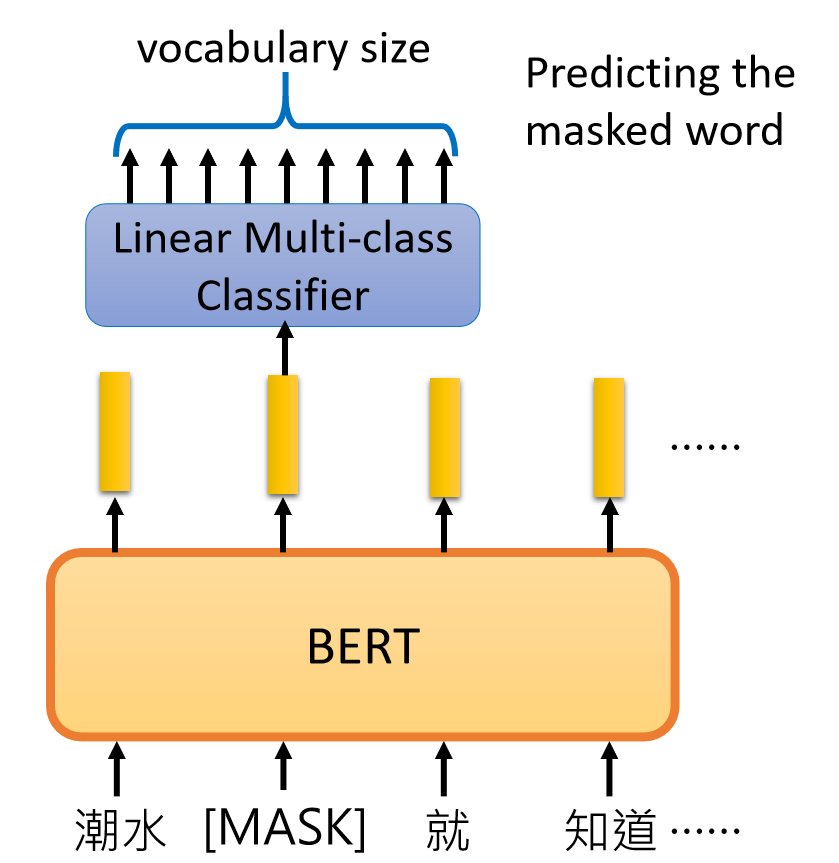
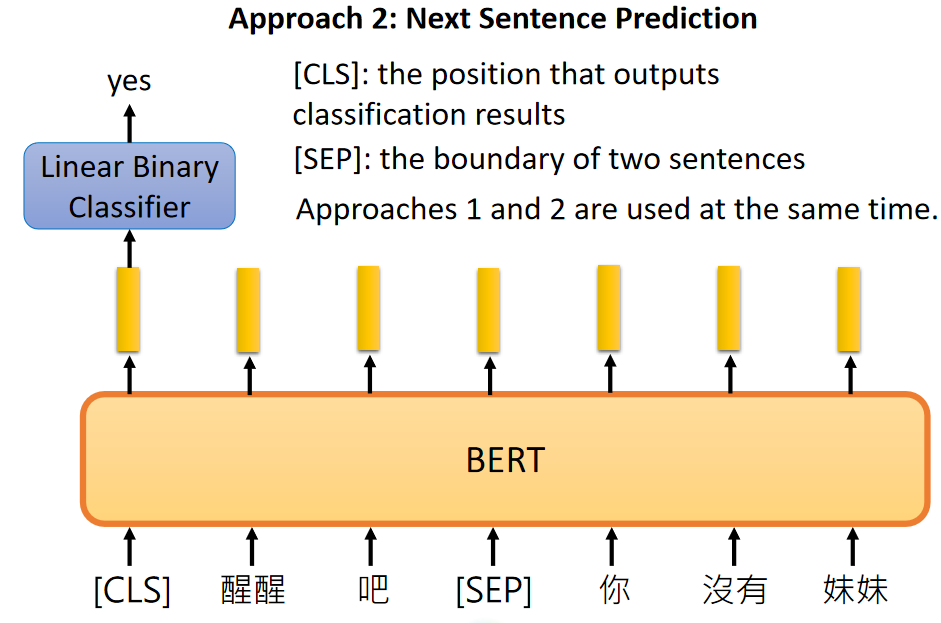
train BERT有两种方法,Masked LM和Next Sentence Prediction,Masked LM是随机掩盖住一些词,让BERT猜测盖住的词什么。Next Sentence Prediction是让BERT推断两个句子是不是有上下文关系。
![]()
![]()
BERT充分考虑了上下文,对word进行编码,于是很好的体现语义和上下文的关系,在很多比赛中遥遥领先。
四、总结
自然语言处理从原始的布尔模型,到向量空间模型,再到word2vec,再到ELMO,再到GPT,再到BERT,一路走来,技术的更替。目前为止,BERT依然是比较领先的word Embedding方法,在大部分自然语言处理任务中,作为预训练任务,是我们首先应该尝试的办法。也许,用不了多久,又会有新的技术出来,刷新成绩,我们拭目以待。但即便是现在为止,机器是否真的理解了人类的语言,这还是一个尚待论证的问题。路漫漫其修远兮,吾将上下而求索。
快乐源于分享。
此博客乃作者原创, 转载请注明出处
P(1 ,每