去年 Meta 把员工的 Token 消耗量写进了绩效考核。结果很行为艺术:员工让两个 Agent 互相对话一整天来刷量。这事被圈子里叫做 tokenmaxxing——用行政手段逼着团队用 AI,哪怕是无意义的消耗。
Amol(化名 theahura)在他的博客里复盘了这个现象。他的判断是:tokenmaxxing 的第一阶段已经结束了。当初公司之所以搞这种粗暴政策,是因为大量资历老的员工抗拒 AI 工具,不用任何办法推不动。现在每个人——哪怕只是侧栏里开个 Cursor——都已经在用 AI。OpenAI 和 Anthropic 准备上市,订阅不值钱、API 在涨价,无限 Token 的福利在缩水。第一代 tokenmaxxing 自然消亡。

但第二阶段开始了,而且逻辑恰恰相反。这次不是因为行政驱动,而是技术本身出现了质变。
他把新的现象叫 compounding correctness。以前让 Agent 长时间跑,结果通常是 compounding error——小幻觉滚成不可逆的大问题,24/7 运行没有实际意义。现在反过来了:模型质量越过了某个临界点,token 烧得越多,输出质量越好。Boris Cherny(Claude Code 的作者)推广的 "loops" 模式——让 Agent 跑完一轮,然后把同一个 prompt 重新丢给它,反复循环——以前很难稳定出结果,现在基本是每多跑一轮就更好一点。
这个变化直接改写了 AI 开发的经济学。如果 token 花的越多结果越好,那成本效率的计算不再是哪个模型单次调用最便宜,而是哪个模型能在等预算下跑更多轮。
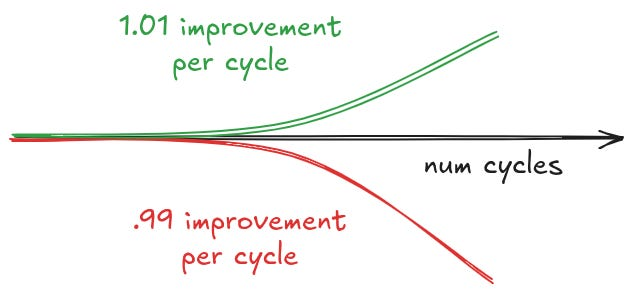
他算了笔账:假设 Claude Opus 每轮迭代带来 1.1× 的提升,GLM 5.2 带来 1.05×,但 GLM 的价格只有 Claude 的 1/5。多跑几轮之后,便宜模型反而在前头。具体的:GLM 5.2 约 $1.40/M 输入、$4/M 输出;Opus 4.X 是 $5/M 输入、$25/M 输出。GLM 5.2 在部分 benchmark 上已经超过 GPT 5.5,Haiku 4.5 更是被碾压。
这篇文章里还有几个值得留意的点:
Anthropic 的 Mythos 模型在 AISI 的网络安全测试里,100M token 预算下没有出现任何边际收益递减的迹象。这意味着安全攻防正在变成经济战——谁能比对手多烧 token 谁就赢。
OpenAI 发布了首款自研推理芯片 Jalapeño,和 Broadcom 合作,专门针对自有推理负载优化,模型参与了芯片设计。
GPT 5.6 系列(Sol / Terra / Luna)通过了美国政府协调的预览,华盛顿邮报的标题直说"美国政府决定谁能用新版 ChatGPT"。这件事本身就是一个信号:AI 能力的分配权力正在从行业转移到政府。
回到 tokenmaxxing:第一阶段是管理层拿 token 消耗当鞭子抽员工用 AI,第二阶段是技术本身让 token 消耗变成了正确策略。两者的区别是,前者烧的是员工耐心,后者烧的是开发者的成本收益计算。
参考来源:Agentics / Tech Things: Tokenmaxxing is dead, long live tokenmaxxing
