近期,MoonBit 社区开发者、清华大学计算机科学与技术博士Kaiwei Li开发了开源项目:深度学习训练框架MoonXi-net。这是一个基于 MoonBit 构建、采用 Tagless Final 架构设计、支持 CPU/GPU 多后端扩展的训练框架项目。
在不到一个月的业余开发时间里,开发者借助国产大模型与开源 Agent 工具链完成了框架原型设计、训练系统搭建、GPU 支持与性能优化。项目不仅验证了 MoonBit 构建复杂系统软件的能力,也展示了 AI 辅助开发在系统级项目中的实践潜力。
个人主页:
https://github.com/chnlkw
GitHub项目主页:
https://github.com/moonxi-net/moonxi-net
mooncakes项目主页:
https://mooncakes.io/docs/chnlkw/moonxi-net
为什么用 MoonBit 构建训练框架?
深度学习框架是典型的复杂系统工程。
它既需要高性能计算能力,又需要良好的工程可维护性;既需要支持多种硬件后端,又需要保持统一的开发体验。
MoonXi-net 希望探索一个问题:
MoonBit 是否能够胜任深度学习训练框架这样的复杂基础软件开发?
项目最终给出的答案是肯定的。
通过 MoonBit 的类型系统、Trait 抽象能力以及高性能运行,MoonXi-net 实现了类似 PyTorch 的开发体验,同时保持了静态类型语言带来的安全性与可维护性。
核心设计:模型与后端解耦
MoonXi-net 的核心架构采用了 Tagless Final 思想。
开发者首先定义统一的 Tensor 抽象接口:
-
Tensor
-
ImageTensor
-
Grad(自动微分)
模型只依赖接口约束进行编写:
fn[T : Tensor] Linear::forward(...)
因此同一份模型代码可以运行在不同的计算后端之上。
例如:
-
CPU Tensor
-
GPU Tensor
-
未来更多硬件加速后端
对于框架开发而言,这意味着模型逻辑与底层实现彻底解耦。新增算子、新设备支持或新的 Tensor 实现时,无需修改已有模型代码即可完成扩展。这种设计也为大型 AI 系统的长期演进提供了更好的可维护性。
自动微分系统:让训练像 PyTorch 一样简单
自动微分(Automatic Differentiation)是训练框架的核心能力之一。
MoonXi-net 实现了一套基于 Tape 的自动微分系统。框架在前向计算过程中记录计算图,在反向传播阶段统一回放,实现梯度自动求解。
开发者只需:
loss.backward()
即可完成梯度计算。
与此同时,Grad 本身也是一个泛型封装:
Grad[T]
其中 T 可以是:
-
CPU Tensor
-
GPU Tensor
-
更高阶梯度类型
这种设计不仅保证了框架扩展能力,也为未来支持更复杂的自动微分场景提供了基础。
GPU 支持:借助 FFI 接入 CUDA 生态
为了实现 GPU 加速训练,MoonXi-net 利用了 MoonBit 的 FFI 能力接入 CUDA 生态。
通过封装 CUDA Kernel、cuBLAS、cuDNN 等底层能力,统一的 Tensor 抽象能够无缝映射到 GPU 计算后端。
这一实践也展示了 MoonBit 在高性能计算领域的潜力:开发者既能够享受现代语言带来的类型安全和工程体验,又能够直接调用成熟的高性能计算生态。
AI 辅助开发:从想法到框架原型
MoonXi-net 的另一个亮点在于其开发过程。
项目大量借助国产大模型与开源 Agent 工具完成原型设计、功能开发和性能优化。
在框架开发过程中,AI 参与了:
-
系统架构设计讨论
-
模块实现
-
功能扩展
-
性能优化
-
实验验证
实践表明,当语言具备良好的类型系统和工程结构时,AI 可以更高效地参与复杂系统软件开发。
这也为 AI 时代的软件工程提供了新的探索方向。
实验验证:MoonBit 在 AI 基础设施领域的一次实践
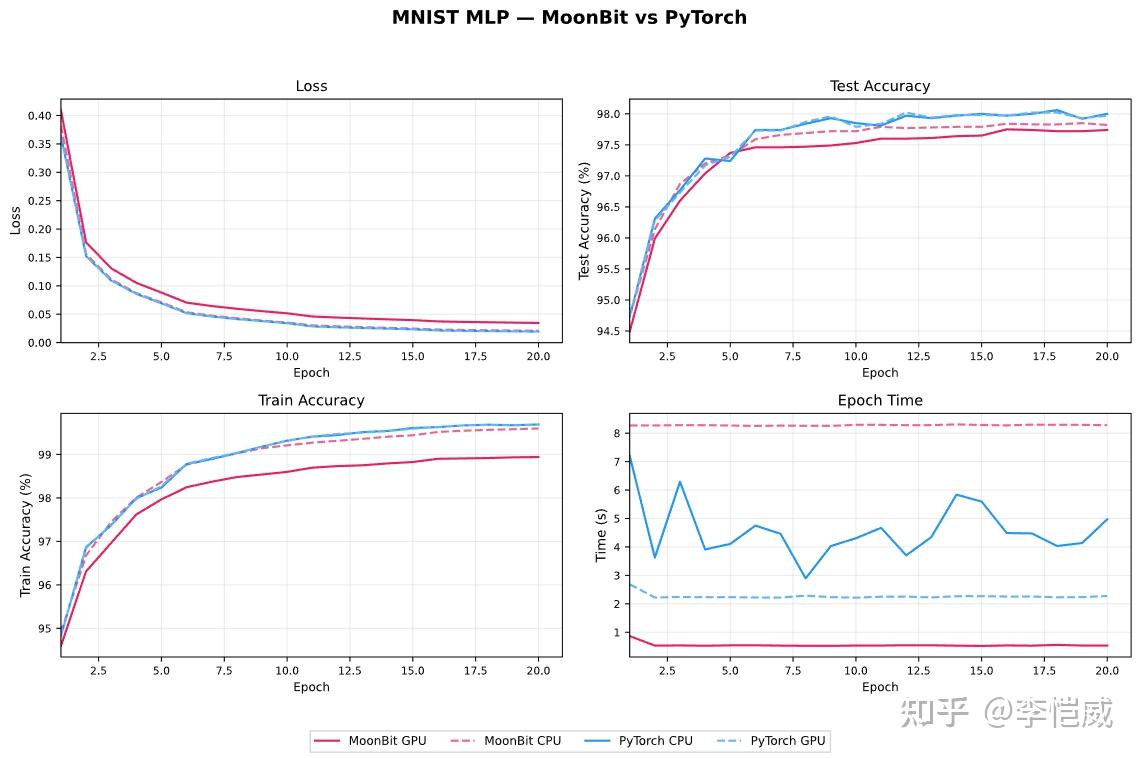
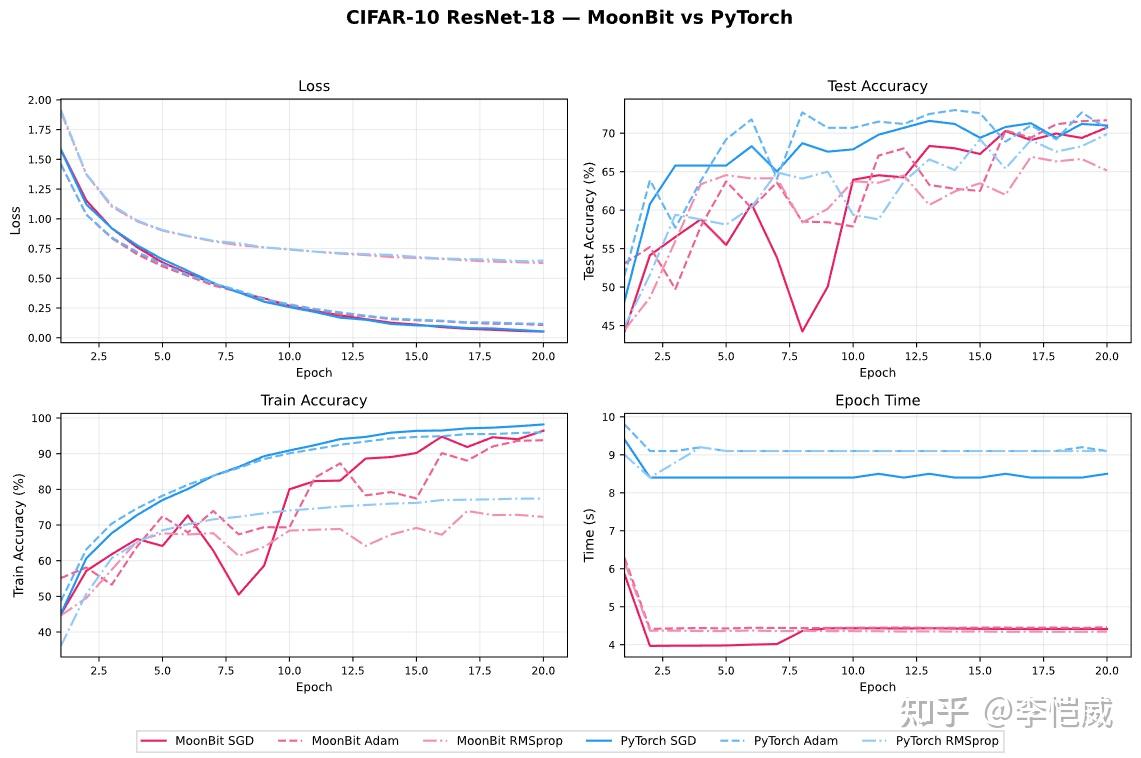
为了验证框架设计的有效性,MoonXi-net 在 MNIST 手写数字识别和 CIFAR-10 图像分类任务上进行了实验测试,测试环境为 NVIDIA RTX 5060 笔记本电脑。
从实验结果来看:
-
MoonXi-net 能够顺利完成模型定义、自动求导和 GPU 训练的完整流程;
-
在 MNIST 任务中,与 PyTorch 取得了接近的收敛效果和测试精度;
-
在 CIFAR-10 ResNet-18 实验中,两者整体训练趋势保持一致;
-
GPU 版本经过算子融合等优化后,单 Epoch 训练时间明显低于对应的 PyTorch 实现。
从实验曲线可以看到,MoonXi-net 在 Loss 收敛、训练准确率和测试准确率等关键指标上与 PyTorch 保持接近水平,同时在训练速度方面展现出良好的优化潜力。
根据当前实验结果,在该测试配置下:
MoonXi-netGPU版本的训练速度约为PyTorch的 2 倍。
开发者moonxi-net表示,精度上的细微差异可能与随机种子、Kernel 实现细节以及训练策略有关,仍有进一步优化空间。对于一个由社区开发者在不到一个月时间内完成的项目而言,这一结果已经充分展示了 MoonBit 在 AI 基础设施方向的技术潜力。
MoonBit 社区创新正在发生
MoonXi-net 并不仅仅是一个训练框架原型。它展示了 MoonBit 在多个方向上的能力验证:
-
构建复杂系统软件
-
实现自动微分系统
-
支持 GPU 高性能计算
-
实践 Tagless Final 架构
-
探索 AI 辅助开发模式
当然,作为一个仍在持续演进中的社区项目,MoonXi-net 也存在一些有待完善的地方。例如:
-
当前全局 Tape 需要手动重置,暂不支持二阶梯度;
-
Tensor 泛型暂不支持编译期维度与形状检查,需要借助运行时 Shape 推导机制;
-
为提升 GPU 训练性能,内存分配采用 Pool 化管理,因此优化器状态与模型参数需要原地更新(in-place update)。
这些挑战也恰恰体现了构建训练框架这类复杂系统工程的价值所在。随着项目的持续迭代,我们期待看到更多优化与创新方案在社区中诞生。感谢社区开发者moonxi-net带来的精彩探索。如果你也在使用 MoonBit 构建有趣的项目,欢迎分享你的成果,一起推动 MoonBit 生态不断成长。