2026年6月24日,Google DeepMind团队宣布将计算机使用(computer use)能力原生集成到Gemini 3.5 Flash模型中。这意味着开发者现在可以通过单一模型构建能够在浏览器、移动设备和桌面环境中"看见屏幕内容、理解界面逻辑并自主执行操作"的AI Agent——而不再需要为此单独部署一个专门的计算机使用模型。这项能力通过Gemini API和Gemini Enterprise Agent Platform向开发者开放。
在技术架构上,Computer Use被设计为Gemini 3.5 Flash的一项原生工具,与Search搜索接地、Maps地图接地和函数调用(function calling)等已有工具并列存在。此前,这项能力仅作为一个独立的Gemini 2.5计算机使用模型提供,需要在主模型之外额外调用。将computer use集成到3.5 Flash的直接好处是简化了开发者体验:一个 Agent在进行多步骤任务时,比如研究一个话题、在网页上填写表单、然后将结果记录到电子表格中——可以在同一个模型上下文中同时使用搜索、计算机操作和工具调用,而不需要在多个模型之间切换和手动传递上下文。这对代理式任务的可靠性和延迟都有实质性的改善。

这种"多工具合一"的架构选择反映了Google DeepMind对AI Agent发展方向的一个关键判断:Agent的可靠性瓶颈不在于单项工具的能力极限,而在于多工具之间的上下文切换和信息损失。当搜索、计算机操作和函数调用各自运行在不同的模型上时,每个切换点都是错误注入的机会。而将它们统一在一个模型架构中,上下文可以在不同工具之间连续流动,理论上可以大幅降低复杂任务中途失败的概率。这是Google对AI Agent范式的一个建筑学级别的决策——与其建造三个需要不断通信的独立建筑,不如直接建造一个连通的综合体。
Google为Computer Use定义了三个核心应用场景。首先是长时间运行的自动化任务,那些需要AI在数小时甚至数天内持续操作多个应用界面来完成的流程,比如跨系统的数据迁移、多平台的合规审核、或者供应链管理系统中的多节点信息同步。这类任务的共同特征是步骤繁多但结构相对固定,人类操作员容易因疲劳而出错,而AI Agent则可以在无人值守的情况下持续执行。
其次是持续性软件测试。AI Agent可以在每次代码变更后自动打开浏览器、执行预设的用户操作路径、跨多个设备和屏幕尺寸验证UI的一致性,并在发现异常时生成带有截图的详细报告。这比传统的脚本化UI测试更灵活,因为它可以在一定程度上适应UI布局的非结构性变化。第三是跨应用的知识工作。比如让AI同时操作CRM系统、数据分析工具和电子邮件客户端来完成一个销售线索的完整跟进流程,或者在一个法律合规场景中跨多个文档平台收集证据和交叉引用条款。所有这些场景的共性在于它们不只是一次性的"看屏幕点按钮",而是需要在多个上下文之间保持连续性的、有目的的工作流。
在安全设计上,Google采用的是一种多层防御策略。第一层是针对性对抗训练。专门针对computer use场景中可能出现的恶意指令进行了模型级别的安全强化。第二层是可选的"企业安全护栏",要求AI在执行敏感操作(如提交表单、发送消息、修改文件)之前获取用户的显式确认。第三层是间接提示注入检测。当模型检测到外部内容(如网页中的隐藏文字)试图向模型注入恶意指令时,会自动中止当前任务。
这三层机制加上沙箱隔离、人工审核环节和严格的访问控制,构成了一个相对完整的安全边界。虽然Google也坦承,在真实的计算机使用环境中,安全挑战的性质已经从"能不能防住已知攻击"转变为"如何在一个本质上不可控的开放环境中管理风险"。
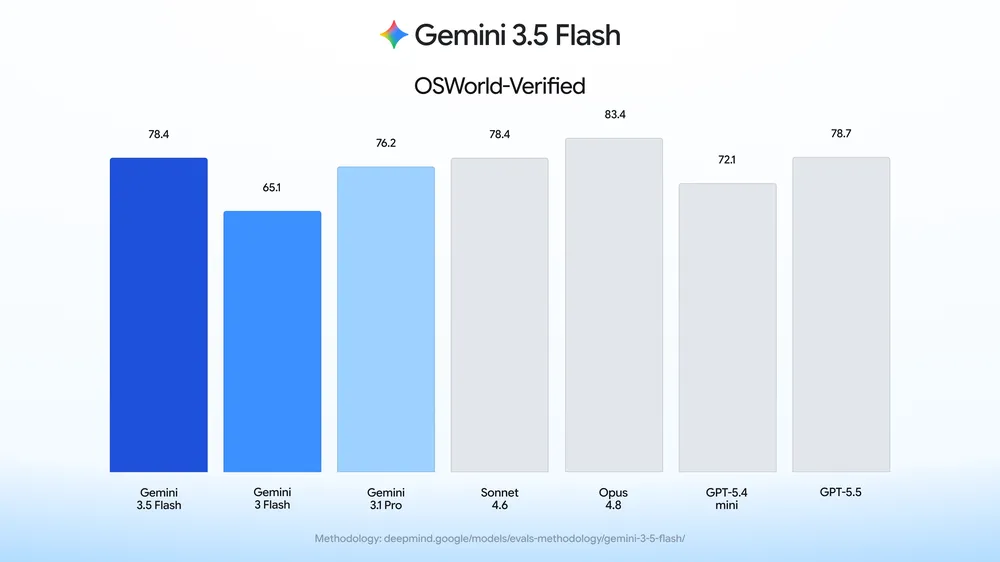
值得留意的是,Google在发布Computer Use时并未像以往那样强调在OSWorld等标准benchmark上的排名。这在Google的发布风格中是一个微妙的变化。很可能的原因是:目前的标准化评测无法充分反映现实世界computer use任务的复杂性——在实验室环境中模拟的桌面操作与真实世界中参差不齐的网页、不一致的UI规范和不可预测的弹窗之间,存在着评测无法捕捉的巨大差距。Google选择用"我们最好的表现"这种定性表述而非具体数字,暗示了对这一点的自觉。
参考来源:
