2026 年 6 月中旬,Elon Musk 创立的 AI 公司 xAI 在未做任何正式公告的情况下,通过 API 平台上线了一个名为 Grok Build 0.1 0616 的新模型。这个奇怪的命名——既不是常规的 Grok 4.x 系列编号,也不是标准的语义化版本号——迅速引起了 AI 开发者和评测机构的关注。
独立评测平台 Artificial Analysis 在第一时间对其进行了完整的基准测试,结果揭示了一个值得行业关注的事实:这个带有工程构建版标签的模型,在智能指数上已经超越了 xAI 目前的旗舰产品 Grok 4.3,而它的定价策略同样显示出这家公司对其下一代模型的市场定位正在发生微妙变化。

在深入分析评测数据之前,有必要先理解 xAI 目前在 AI 模型竞争格局中的位置。作为 2023 年才成立的后来者,xAI 在不到三年时间里完成了从零到参与顶级模型竞赛的跨越。它的 Grok 系列以「反政治正确」的态度和与 X 平台(原 Twitter)的深度整合为差异化卖点,在技术路线上则强调多模态理解、长上下文处理和推理能力。2025 年底发布的 Grok 4.3 在多数评测中处于第二梯队上游——实力不俗但与 Anthropic 和 OpenAI 的旗舰产品仍有明显差距。因此,当 Grok Build 0.1 0616 的 Intelligence Index 评分浮出水面时,外界对 xAI 下一代模型的预期也在被重新锚定。
Artificial Analysis 的 Intelligence Index v4.1 是当前行业公认最全面的独立基准之一,它整合了九项评测任务:GDPval-AA v2(经济与政策推理)、τ³-Banking(金融场景)、Terminal-Bench v2.1(命令行与工具使用)、SciCode(科学编程)、Humanity's Last Exam(前沿知识极限测试)、GPQA Diamond(研究生级别物理/化学/生物推理)、CritPt(批判性思维)、AA-Omniscience(跨学科知识广度)和 AA-LCR(长上下文回忆精度)。这套评测的设计哲学是测量模型在真实世界复杂任务中的综合表现,而非简单刷榜式 benchmark。
在这个评测体系下,Grok Build 0.1 0616 得分为 39.80,在 155 个被评测模型中排名第 27 位,获评 4/4 个智能等级单位。把它放在当前顶级模型的坐标中对比:Anthropic 的 Claude Fable 5 以 59.86 分大幅领跑,OpenAI 的 GPT-5.5 xhigh 以 54.84 分居次,智谱的 GLM-5.2 max 得分 51.09 排名第三。紧随其后的是 Google 的 Gemini 3.1 Pro Preview(46.46)、MiniMax-M3(44.44)、DeepSeek V4 Pro Max(44.27)、Muse Spark(43.06)和月之暗面的 Kimi K2.6(42.84)。Grok Build 0.1 的 39.80 分压过了 NVIDIA Nemotron 3 Ultra(37.76)和 xAI 自家的 Grok 4.3 high(37.58)。
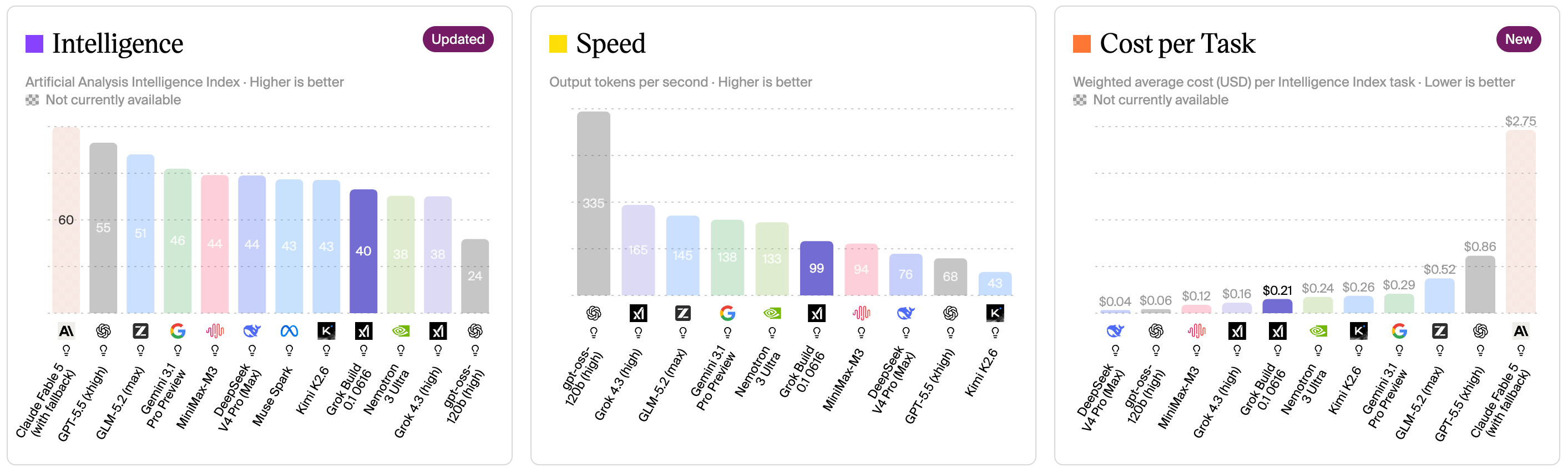
解构这组排名的关键信息不在于绝对值,而在于梯度。Grok 4.3 high 到 Grok Build 0.1 之间约 6% 的提升,对于一次「Build 0.1」的内部工程迭代来说,幅度相当可观。如果这确实是 xAI 新一代基础模型的起点,那么它在正式版本迭代时还有充分的优化空间——预训练数据的清洗、RLHF 的对齐调优、推理链的长度配置,都会带来进一步的分数提升。从历史上看,Claude 3 到 Claude 3.5、GPT-4 到 GPT-4o 的迭代也都经历了类似的「早期构建版先跑通、正式版再精调」路线。
速度是 Grok Build 0.1 的另一项突出指标。它的中位输出速度为 93.3 tokens/秒,在 155 个模型中排名第 53 位,获评 3/4 个速度单位。在推理模型(reasoning models)这一细分类别中,这个速度实属上乘。与主要的同级推理模型对比:GLM-5.2 max 为 139 tokens/秒,Gemini 3.1 Pro Preview 为 138 tokens/秒,Nemotron 3 Ultra 为 136 tokens/秒——这些略快于 Grok Build 0.1。但往上看,GPT-5.5 xhigh 仅 68 tokens/秒,Kimi K2.6 为 69 tokens/秒,DeepSeek V4 Pro Max 为 77 tokens/秒——Grok Build 0.1 比这些模型快了约 20% 到 37%。在 AI 应用的实际体验中,90 tokens/秒以上的输出速度意味着大多数中等长度的回答可以在 5 到 10 秒内完成,这对于对话式 AI 和实时代码辅助场景来说,是一个重要的体验分水岭。
值得单独讨论的是 Grok Build 0.1 的冗长度特征。它在一个完整的 Intelligence Index 评测周期中生成了约 1.3 亿个输出 token,远超同类的 9300 万平均值,在 155 个模型中排名第 25 位。高冗长度在推理模型中是一把双刃剑:一方面,这意味着模型在回答复杂问题时倾向于提供更详尽的思考过程和解释——在科学研究辅助、金融分析、代码审查等场景中,这是受欢迎的;另一方面,超过均值约 40% 的输出量也意味着用户的 token 消耗会相应增加。当你在评估模型性价比时,不能只看每百万 token 的单价,还要考虑模型完成同一任务实际消耗的 token 数量——这个指标在业界被称为「token efficiency」,而 Grok Build 0.1 在这个维度上显然还有优化空间。
再看定价。xAI 为 Grok Build 0.1 0616 设定的 API 价格为输入每百万 token 收费 1.00 美元、输出每百万 token 收费 2.00 美元、缓存命中价 0.20 美元(享受 80% 折扣)。放在行业基准中理解这些数字:同类商业闭源推理模型的输入平均价约为 1.50 美元、输出平均价约为 8.00 美元。Grok Build 0.1 的定价大致是行业均价的 67%(输入端)和 25%(输出端)。每项智能任务的加权平均实际成本为 0.21 美元——在同类 11 个评测模型中排名第 5 低。作为对比,Claude Fable 5 的每任务成本高达 2.75 美元,是 Grok Build 0.1 的 13 倍。当然,考虑到 Claude Fable 5 的智能指数高出约 50%,两者的性价比曲线并不直接可比较,但 Grok Build 0.1 向市场传递的信号清晰:xAI 希望在下一代模型中实现「够用的智能」和「激进的定价」之间的平衡。
技术规格方面,Grok Build 0.1 0616 支持文本和图像两种输入模态,输出为文本,上下文窗口为 256K tokens——约等于 384 页 A4 纸的内容量。256K 窗口在 2026 年属于行业主流水准,与 GPT-5.5、Claude Sonnet 4.6 等产品相当,但与 Claude Fable 5(据报道超过 500K)和 Gemini 3.1 系列(200K-1M)相比,仍有扩展空间。xAI 未公开该模型的参数规模——这也是闭源商业模型的常态——但从其推理速度和定价来推测,它很可能不是单一的超大参数模型,而是采用了 MoE(混合专家)架构或以蒸馏加推理链优化的技术路径。
「Grok Build 0.1 0616」这个命名本身就是一个值得解读的信号。在软件工程中,「Build」意味着内部构建版——不是面向最终用户的 Release,而是在持续集成流程中产出的阶段性产物。日期戳「0616」指向 6 月 16 日的构建时间。将这两个线索与 39.80 的智能评分结合起来看,合理的推断是:这个模型很可能是 xAI 下一代大模型(或许会命名为 Grok 5 或 Grok Next)训练管线中产出的一份早期训练快照。
xAI 选择以付费 API 的形式向开发者公开这个构建版,而不是像多数 AI 公司那样在内部封闭测试直到正式发布才对外,这种做法的逻辑可能是希望借助外部开发者的真实使用反馈来加速模型迭代——对于一家以「move fast」为创业基因的公司来说,这是完全合理的选择。
参考来源:Artificial Analysis: Grok Build 0.1 0616 - Intelligence, Performance & Price Analysis
