2026 年 1 月,Netflix 高级工程师 Tejas Chopra 在做一件全世界开发者每天都在做的事情——用 AI 编程助手调试一个个人项目的代码。他调用了数据库查询的 MCP 工具,做了一些代码重构,跑了几轮迭代。然后账单来了:Claude Sonnet 的一次会话花了他 287 美元。
这个数字对于一次"典型的家庭项目"来说过于刺眼。Chopra 翻查了 Token 消耗明细,发现了一个他称之为"丑陋真相"的事实:他手写的提示词只占了一小部分,绝大多数 Token 消耗来自机器生成的膨胀数据,其中包括冗余的 JSON 结构、嵌套的 API 响应模板、重复出现的数据库字段名。用他的话说:"这不是散文或创意写作,而是伪装成文本的可压缩数据。"他援引的一项 2025 年研究发现,约 76% 的 AI Token 消耗仅用于读取用户输入,而这些输入中,大量内容本质上是可以被高度压缩的结构化机器数据。
这个发现催生了 Headroom,一个在本地运行的开源上下文压缩 Agent。它的设计哲学简单直接:在请求到达大语言模型之前,对 Agent 读到的所有内容(工具输出、日志、RAG 检索片段、文件内容、对话历史)进行智能压缩,让模型用更少的 Token 得到相同的答案。上线五个多月后,Headroom 在 GitHub 上积累了超过 44000 颗 star,发布了 26 个版本,据估算已累计为用户节省约 70 万美元的 API 费用,释放了超过 2000 亿个 Token。

Headroom 的技术架构围绕一条四阶段管线构建。第一阶段是 CacheAligner,它的任务不是压缩内容,而是压缩成本。大模型提供商的 KV 缓存机制会给重复出现的前缀提供大幅折扣,但一个微小的变化——比如系统提示词中自动生成的日期字段或会话 UUID——就足以导致每次调用全部命中缓存未命中。CacheAligner 识别并稳定这些动态前缀,只向模型发送变化的部分。Chopra 在 InfoQ 的采访中指出,Anthropic 默认的 Prompt 缓存 TTL 仅 5 分钟,如果扩展到一小时意味着"写入成本翻倍以换取读取时 90% 的节省",这本质上是一道需要精心权衡的算术题,而大多数开发者从未意识到自己的系统提示词正在持续触发全价计费。
第二阶段是 ContentRouter,一个内容类型检测与路由层,判断输入是 JSON、代码、自然语言还是 DOM 模板,然后分发给对应的专门压缩器。第三阶段的三款核心压缩引擎各有专攻:SmartCrusher 处理 JSON 数据,保留错误信息、统计异常值和 BM25 匹配项,剔除约 70% 的结构冗余;CodeCompressor 基于 tree-sitter 做 AST 感知的代码压缩,保留导入声明、函数签名和类型信息,削去函数体的细节;Kompress-base 是一个部署在 HuggingFace 上的自训练模型,基于"Agent 运行轨迹"数据微调而来,负责通用自然语言文本的压缩。此外还有针对图片的 ML 路由压缩器和基于重要性评分的 IntelligentContext 上下文适配器。
第四阶段是 Headroom 最核心的差异化设计:CCR(Compress-Cache-Retrieve,压缩-缓存-检索)可逆压缩机制。传统的上下文压缩工具一旦丢弃了信息就无法找回,这使得激进的压缩策略自带风险——万一模型真的需要那段被删掉的内容怎么办?Headroom 的做法是在压缩点位打标记,原始数据保留在本地的 Redis 或 SQLite 中。当大模型在处理过程中确实需要原文时,它可以通过 Headroom MCP 暴露的 headroom_retrieve 工具主动取回。Chopra 表示,在实际使用中"模型几乎从不调用检索",因为智能压缩已经保留了足够的信息——但这个逃生舱的存在,使得 90% 级别的激进压缩从"冒险"变成了"安全"。这也是 Headroom 与 RTK、LeanCTX 等竞品的关键区别:它覆盖所有内容类型而非单一场景,完全可逆而非有损丢弃,完全本地运行而非依赖第三方云服务。
Headroom 运行过程如下:
Your agent / app
(Claude Code, Cursor, Codex, LangChain, Agno, Strands, your own code…)
│ prompts · tool outputs · logs · RAG results · files
▼
┌────────────────────────────────────────────────────┐
│ Headroom (runs locally — your data stays here) │
│ ──────────────────────────────────────────────── │
│ CacheAligner → ContentRouter → CCR │
│ ├─ SmartCrusher (JSON) │
│ ├─ CodeCompressor (AST) │
│ └─ Kompress-base (text, HF) │
│ │
│ Cross-agent memory · headroom learn · MCP │
└────────────────────────────────────────────────────┘
│ compressed prompt + retrieval tool
▼
LLM provider (Anthropic · OpenAI · Bedrock · …)
Headroom 提供了四种接入方式,覆盖了从零代码到深度集成的全谱系。最简单的"headroom wrap claude"一行命令即可包裹 Claude Code、Codex、Cursor、Aider 等主流编程 Agent。透明代理模式只需将环境变量 ANTHROPIC_BASE_URL 指向 localhost:8787,不改一行代码。Python 和 TypeScript 的 SDK 封装允许在应用中调用 compress(messages) 进行内联压缩。MCP 服务器模式则直接暴露压缩、检索和统计工具,供任何兼容 MCP 的 Agent 调用。这种"渐进式接入"的设计极大降低了使用门槛——初级用户从 wrap 命令起步,高级用户可以通过 SDK 和 MCP 做深度定制。
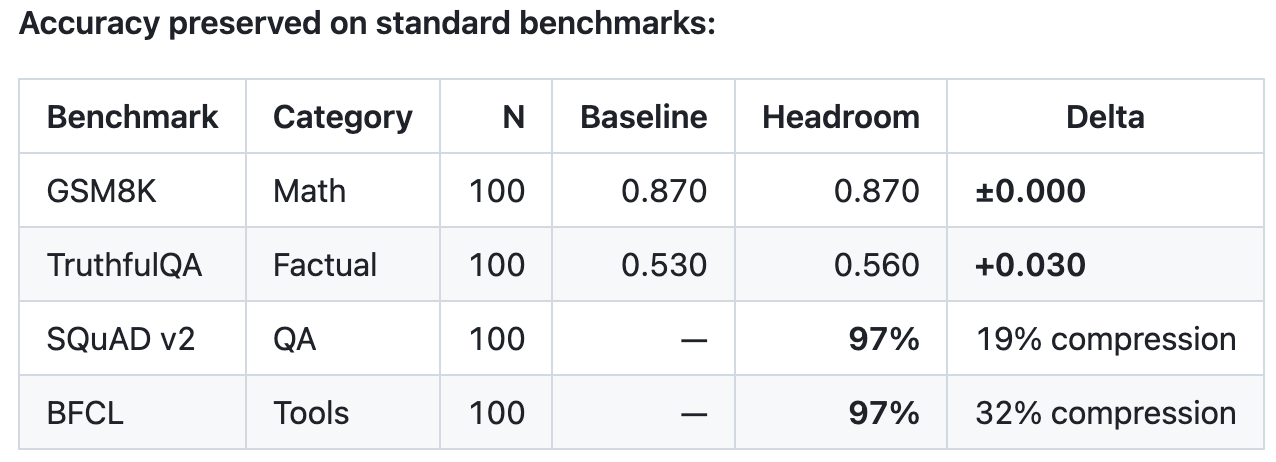
从效果数据来看,Headroom 的压缩率因内容类型差异明显。在代码搜索场景中,100 条搜索结果从 17765 Token 压缩到 1408 Token,节省 92%;SRE 事故调试从 65694 Token 压缩到 5118 Token,同样节省 92%;GitHub Issue 分类从 54174 Token 降至 14761 Token,节省 73%;代码库探索从 78502 Token 降至 41254 Token,节省 47%。在 GSM8K 数学推理、TruthfulQA、SQuAD v2 和 BFCL 函数调用等基准测试中,压缩前后的准确率差异在 ±0.03 以内,基本保持零损失。每条请求的延迟开销仅为 1-5 毫秒。
将这些百分比换算为实际成本,可以对 Headroom 的经济价值有一个更具体的感知。以 Claude Sonnet 当前每百万输入 Token 3 美元的定价计算,一次涉及 65000 Token 的 SRE 事故调试会话如果不做压缩,输入成本约 0.20 美元——看起来微不足道。但一个重度 AI 编程 Agent 用户每天可能发起上百次这样的会话,月账单轻松突破 500 甚至 1000 美元。Reddit 社区的实测反馈显示,有用户在包裹 Codex 之后,"Plus 配额多用了 3 倍,同样的任务,同样的输出"。另一个用户报告日耗从 200 美元降到 30 美元。对于已部署多个 AI Agent 的团队而言,这种量级的成本削减不是锦上添花,而是决定是否扩大 AI 使用的关键变量。
Headroom 的走红折射出 AI 编程 Agent 生态中一个正在快速膨胀的痛点:Token 成本正从"可忽略"变为"需要管理"。随着上下文窗口扩展到 200 万 Token 以上,大模型能够一次性"阅读"的内容量急剧增长,这意味着每次调用的最大可能成本也在同步攀升。斯坦福大学的一项研究发现,大模型对上下文窗口的注意分布极度不均衡,更关注开头和结尾,中间部分的信息提取效率明显下降。Chroma 团队在对 18 个模型的测试中进一步验证了这一现象,称之为"上下文腐烂"(Context Rot)——输入越长,输出稳定性越差。
在这种背景下,Headroom 提供的不仅是成本节省,更是对模型注意力机制的间接优化:更精炼的输入意味着模型更容易关注到真正重要的信息。
对于这个起源于一张 287 美元账单的个人项目而言,它已经走到了一个远超预期的位置,但真正的机会在于,当 AI 编程 Agent 从早期尝鲜者走向大规模企业部署时,每一个百分点的 Token 节省都将转化为真实的运营成本下降。Headroom 的价值主张恰好击中了这一即将全面爆发的需求:不是提供一个更好的压缩算法,而是将压缩变成 AI Agent 基础设施中一个无感知的默认层。正如 Chopra 对 The Register 所说,"我们的用户是那些真正被 Token 成本灼伤过的人"——而随着 Agent 使用量的指数增长,这个群体的规模正在以同样的速度扩张。
参考来源:
