2026 年 6 月 17 日,Canonical 工程总监 Jean-Baptiste Lallement 在 Ubuntu 社区论坛正式公布了 Project Myna,旨在为 Ubuntu 桌面带来系统级的本地 AI 语音转文本功能。
Myna 得名于擅长模仿人类说话的八哥鸟(Myna bird),这个意象本身就暗示了项目的本质:不是理解语言,而是忠实地将语音复制为文字。项目的初始定位非常克制——一个纯粹的桌面听写工具,用户按下键盘快捷键开始说话,松开后转录的文字直接出现在当前应用程序的光标位置。整个过程就像使用系统自带的原生功能一样自然,不需要打开独立应用窗口,不需要手动复制粘贴,也没有语音助手式的对话交互。激活听写时,屏幕上只会出现一个微型状态指示器,告诉用户麦克风正在收音,转录完成的文本则直接注入到活动窗口的光标处。
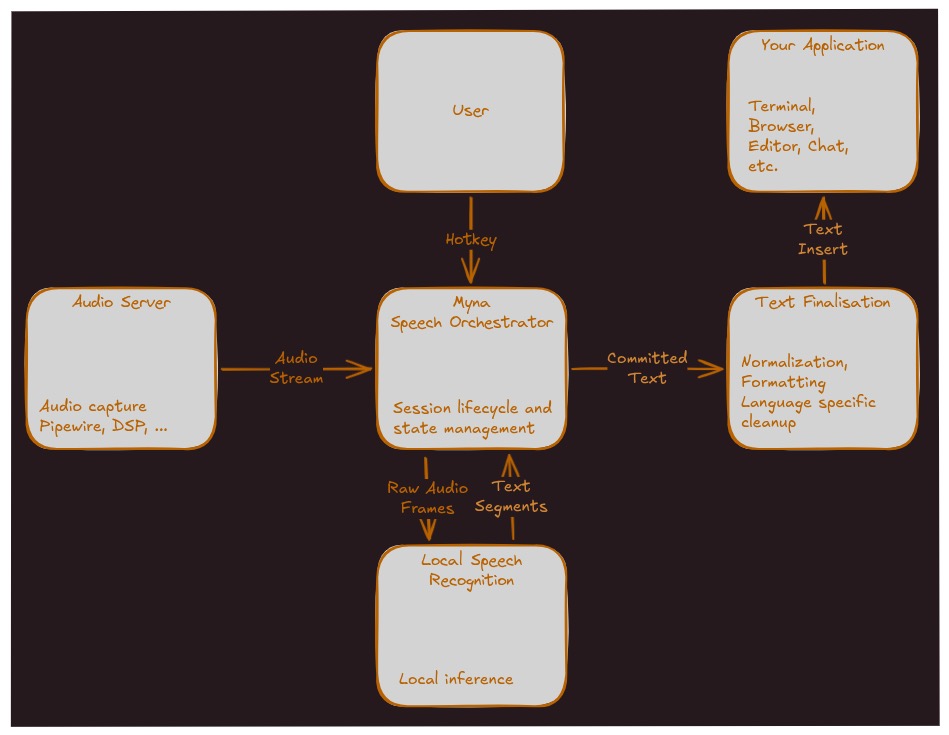
Myna 的模块化架构由三个核心部件组成。最上层是 Audio Adapter,负责捕获麦克风输入,执行降噪处理,并将连续音频流切分为适合识别的数据块。中间层是 Speech Orchestrator——听写会话管理器,协调激活热键、音频输入和文本注入的生命周期。最底层是一个名为 Canonical Inference Snap 的沙盒化推理引擎,承担实际的语音识别工作。这个 snap 包将提供轻量、默认和高质量三种模型尺寸,适配不同的硬件场景:NVIDIA GPU、Intel NPU 或纯 CPU 推理都得到支持。模型选型方面,项目贡献者 charles05 在论坛中透露团队已经考察了 OpenAI Whisper、NVIDIA Nemotron 和阿里通义的 Qwen3-ASR,其中部分模型提供多语言变体,但不同语言间的识别准确率差异较大——这暗示多语言覆盖将是一个渐进过程,而非首发即完美。
隐私策略是 Myna 设计中最鲜明的差异化标签。Canonical 在项目文档中反复强调"隐私从一开始就是设计原则"。所有语音识别完全在本地运行,一旦下载安装好模型,电脑就永远不需要联网。麦克风只在用户明确激活听写的瞬间才打开,音频数据在处理后立即从内存中丢弃。Lallement 在公告中明确承诺"不会有任何录音被上传到外部服务"。这套设计思路直接回应了过去几年开发者对语音类工具的普遍疑虑——无论是 Microsoft 365 的云端听写,还是 Google Docs 的语音输入,都将音频发送到远程服务器做处理,这在注重隐私的 Linux 用户群体中几乎天然被抵制。Myna 选择的是另一条路:宁可牺牲云端的超大规模模型和持续更新能力,也要保证数据只留在用户自己的硬盘和内存里。
首版 Myna 计划随 Ubuntu 26.10(Stonking Stingray)在 2026 年 10 月发布,面向 GNOME 桌面环境和 Wayland 显示协议,这是 Ubuntu 桌面当前的标准技术栈。Lallement 在公告中划了一条清晰的边界:首发版本只做桌面听写,严格排除语音助手、语音命令、桌面操控、翻译工具、自动语言检测和唤醒词监听。这个决策透露出 Canonical 对第一个版本的实际判断——语音识别在 Linux 上的基础打得还不够牢,在全速冲刺高级场景之前,先要把"按下按键→说话→出字"这条链路做到稳定可靠。项目的 GitHub 仓库目前只有许可证、README 和架构文档,代码尚未公开,但 Canonical 表示"未来几周"可能出现在 Ubuntu 26.10 的每日构建版本中。
选择 Wayland 作为首发目标协议是一个值得注意的技术决策。Wayland 相比 X11 有更严格的沙盒模型——应用程序之间默认隔离,一个窗口不能随意截获另一窗口的键盘输入或屏幕内容。这对语音听写来说同时意味着机遇和挑战:机遇在于 Wayland 的安全边界与 Myna 的隐私设计天然契合,麦克风权限的管理和音频通道的隔离都比 X11 时代更可靠;挑战则在于文本注入——将转录完成的文字插入到另一个应用程序的光标位置——在 Wayland 的安全模型下需要克服更多的协议限制。Canonical 在 GNOME 桌面上拥有多年维护经验,这或许是 Myna 选择首发 GNOME + Wayland 而非追求更广泛兼容性的深层原因:在一个自己深度参与开发的技术栈上,协议层面的障碍可以更早被识别和解决。
Myna 的发布,让 Linux 桌面语音转文字这件事从一个"社区自发实验"的话题直接升级为"发行商系统集成"的工程问题。但有必要承认的是,Myna 所进入的不是一个空白地带——恰恰相反,2026 年的 Linux STT 生态已经颇有气象。dictee 项目以 Rust 编写的 ONNX Runtime 后端驱动 NVIDIA Parakeet-TDT 0.6B 模型,支持 25 种以上语言,在 8GB 显存 GPU 上仅用约两分钟就能完成一段 54 分钟演讲的完整转写。OpenWhispr 跨 Linux/macOS/Windows 三平台,将本地模型与 AI Agent 模式结合,支持会议录音的实时说话人分离。whisrs 在 Rust 中实现了 Wayland、Hyprland、Sway 等多种合成器的原生支持。Vocalinux 和 Quassel 则在 whisper.cpp 引擎上分别打磨了各自的特色体验。这些项目互不隶属,却共同构筑了一个活跃的本地优先、开源优先的 STT 生态。但它们的共性是都依赖用户主动去发现和配置——你需要知道 whisper.cpp 的存在,需要了解你的 GPU 驱动栈是否兼容 ONNX Runtime,需要在几个竞品之间权衡取舍。这对 Linux 老手不算什么,但对从 macOS 或 Windows 切换过来的普通用户而言,这些前置知识本身就是一道不低的墙。
Myna 项目目前处于规范定义阶段,Canonical 特别呼吁依赖听写技术或辅助技术的用户参与反馈。对于一个在 2026 年才刚刚拿到系统级语音输入方案的桌面操作系统来说,晚出发也许不是劣势——后来者可以站在五年 Whisper 生态和两年 NVIDIA Parakeet 进化史的肩上,省略大量的探索性错误。Linux 桌面的语音听写故事,从这里才真正开始由一家主流发行商来书写。
参考来源:
