小米汽车宣布正式发布 Xiaomi Auto World Model 全新框架。
根据介绍,Xiaomi Auto World Model 提出了一个全新的整合框架,将重建模块(WorldRec)与生成模块(WorldGen)深度耦合,让两者在结构上互相约束:
- 重建侧给生成“打地基”:WorldRec 维护一个随观测增量扩展的 4D Gaussian 全局表示,把这个 3D 几何投影到自车视角后作为渲染先验喂给生成模型。这意味着生成模型在已观测区域不再“自由发挥”,而是被几何约束锁住——车道结构、建筑位置、相机间的一致性都由重建来兜底,生成只负责补全光照、纹理和未观测区域。
- 生成侧给重建“扩边界”:在重建覆盖不到的时空区域(未来帧、未观测视角、遮挡区),WorldGen 用生成能力把内容补出来,让整个世界模型不再受限于“开过的路”。
- 两者共同压制长时序漂移:重建提供的确定性几何先验持续校正生成过程,从根源上抑制曝光偏差带来的累积误差,让一分钟级别的长视频生成依然保持稳定。
重建提供 3D 几何作为结构化锚点,约束生成过程的稳定性;生成则把预测能力延伸到观测之外,弥补重建的边界。两者形成闭环、互相增益,从三个关键维度实现了“1+1>2”的协同增益:
- 高稳定性:WorldRec 的确定性几何约束,有效抑制长时序自回归中的误差累积与内容漂移。
- 高一致性:4D 场景表征作为跨帧共享记忆,确保不同时刻、不同视角下场景内容全局一致。
- 高真实性:WorldGen 以 WorldRec 渲染的 RGB 图像为几何骨架,使合成内容既符合物理布局,又贴近真实传感器观测,显著缩小了“仿真-现实”的领域鸿沟。
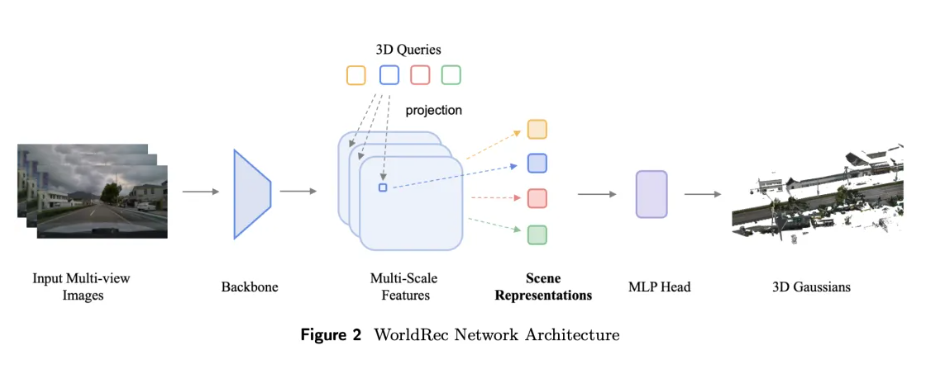
WorldRec 模块的核心思路是把场景表示从“稠密像素”换成稀疏的三维查询点,实现了重建10秒视频仅需10秒的高效率:
- 稀疏三维锚点表征:用稀疏查询点替代上亿稠密高斯,每个锚点对应一个唯一的三维位置,从源头消除多视角冲突。
- 多视角多时刻特征聚合:每个锚点主动到多个相机、多个时刻的图像里采集特征证据,形成跨视角一致的场景表示。
- 可见性加权融合:遮挡、反光的视角自动降权,干净视角自动加权,让模型聚焦在最可靠的观测上。
WorldGen 能够“自由绘画”的生成引擎。仅需4步去噪,0.19秒就可以生成一帧,支持最长1分钟视频。
- 第一阶段用全双向时序注意力进行预训练,让模型同时看到全部帧,建立对驾驶场景时空分布的全局理解;
- 第二阶段进入因果微调,用教师强制(Teacher Forcing)切换因果注意力,再用 ODE 蒸馏把去噪步数从50步压到4步提速12倍,最后用分布匹配蒸馏解决暴露偏差,从根源上抑制长序列漂移。
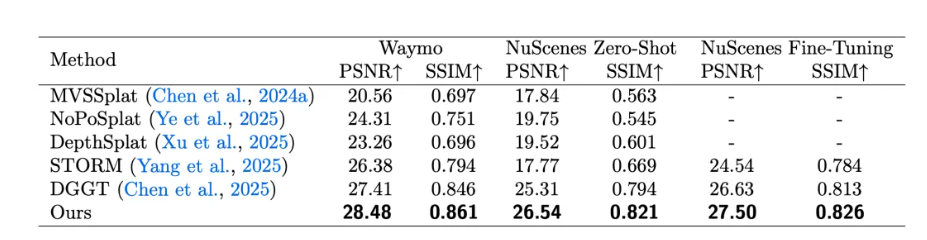
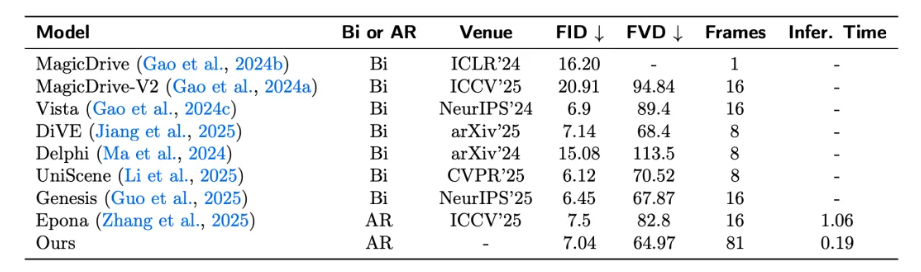
一些测试结果如下: