NVIDIA 近日以 Apache 2.0 协议开源了完整的 NVCF(NVIDIA Cloud Functions)平台。注意,这不是某个薄 SDK,也不是轻量级客户端库,而是真正的控制平面、调用平面、计算平面、CLI 工具、Helm charts 以及数据库迁移——所有代码都在 GitHub 单体仓库 github.com/nvidia/nvcf 中。NVCF 正是 build.nvidia.com 和 NVIDIA 托管推理工作流背后的基础设施。现在,任何人都可以自行运行完整平台,并阅读每一行代码。

NVCF 是什么
NVCF 的托管服务允许用户注册一个 Docker 容器或 Helm chart,指定 GPU 类型,NVIDIA 自动处理路由、队列、自动扩缩容和多租户隔离。CoreWeave 等 GPU 云合作商在 Kubernetes 集群上运行 NVIDIA Cluster Agent,让其 GPU 能够服务于函数,同时 NVIDIA 保留控制平面。2026 年 4 月的 Apache 2.0 发布将这个控制平面彻底公开,此前的两个仓库(NVIDIA/nvidia-cloud-functions、NVIDIA/nvcf-go)已被归档。
一个诚实的警告:目前控制平面镜像通过 NVIDIA NGC registry 的 nvcf-onprem 组织分发,部署完整堆栈需要 NGC 访问权限。源码是 Apache 2.0 可审查的,但可部署包仍然需要通过 NGC。issue #12(完整 OSS 构建)已经开放,作者还专门开了 issue #14 呼吁社区贡献路径。
三平面架构
整个平台围绕三个独立可扩缩的平面构建,通过 NATS JetStream 连接。
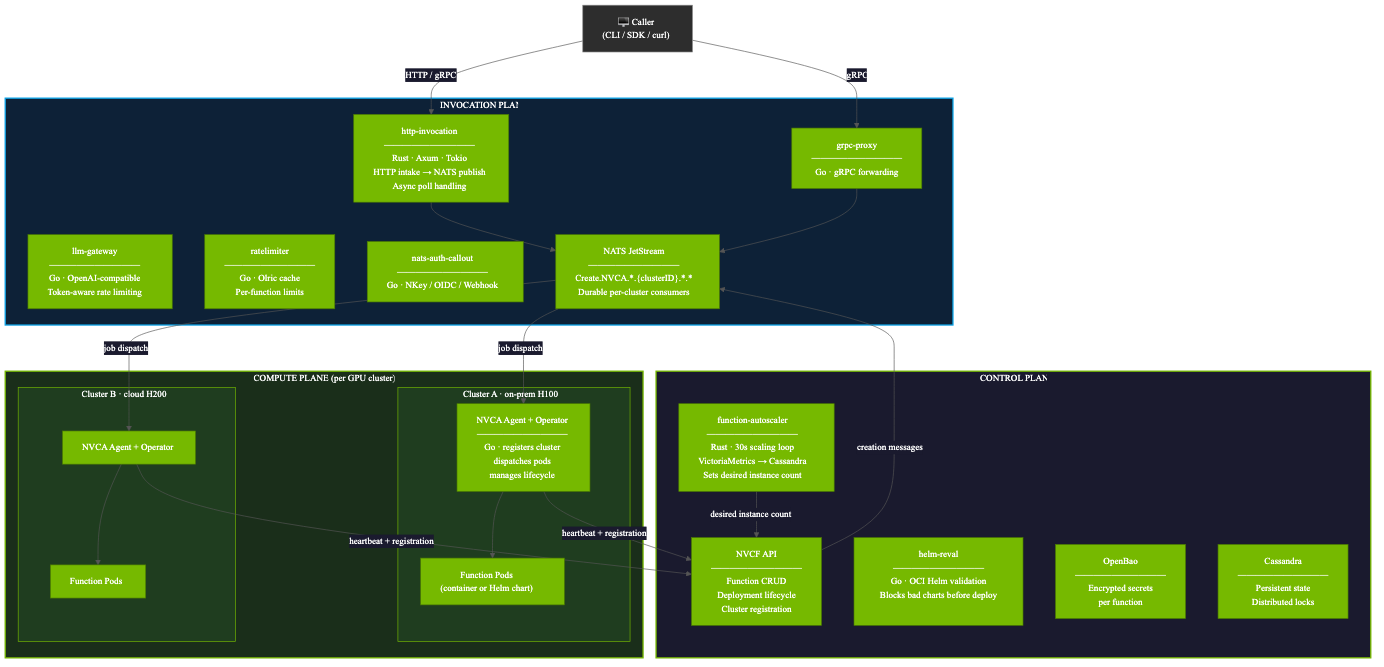
控制平面运行在专用 Kubernetes 集群上,负责函数的生命周期管理、自动扩缩决策和密钥管理。关键组件包括:function-autoscaler(Rust,每 30 秒运行一次扩缩循环,从 VictoriaMetrics 读取利用率,向 Cassandra 写入决策,调用 NVCF API 设置目标实例数)、helm-reval(Go,在计算平面部署前验证 OCI 引用的 Helm charts)、OpenBao(Apache 2.0 的 Vault 分叉,所有函数密钥静态加密,运行时通过 ess-agent sidecar 注入)以及 Cassandra(为 autoscaler 提供持久状态和分布式锁)。
调用平面位于每个调用方和每个 GPU worker 之间,所有请求都必须经过它:http-invocation(Rust/Axum)接收 HTTP/gRPC 请求并发布到 NATS JetStream;llm-gateway(Go)提供 OpenAI 兼容 API,通过嵌入式 Olric cache 实现基于 token 的速率限制;grpc-proxy(Go)转发 gRPC 调用到函数实例;ratelimiter(Go)使用 Olric 分布式缓存实现按函数的速率限制;nats-auth-callout(Go)支持 NKey、OIDC 和 webhook 三种 NATS 认证策略。
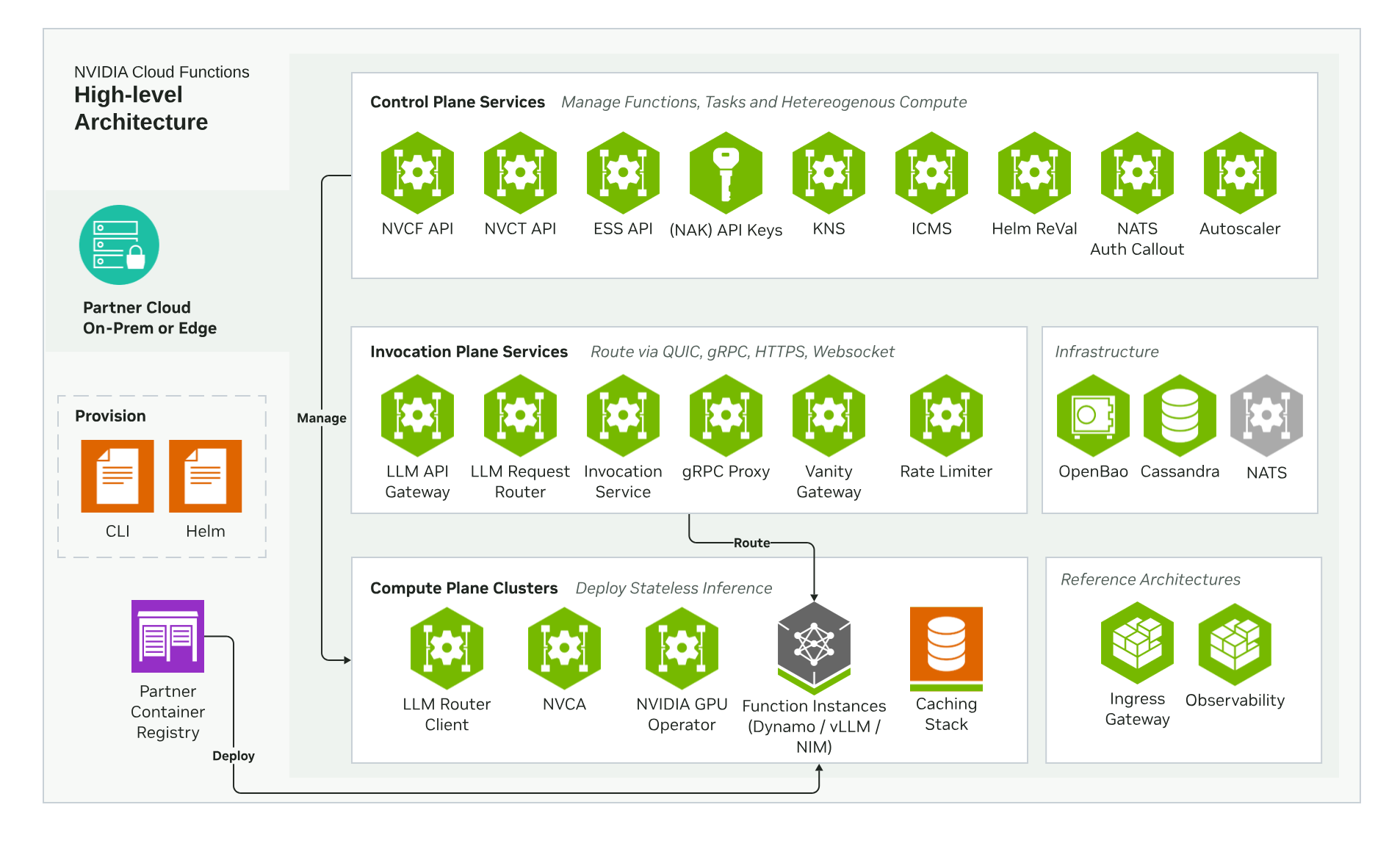
计算平面每个 GPU 集群运行一个 NVCA(NVIDIA Cluster Agent)operator。NVCA 向控制平面注册集群,消费 NATS 消息并管理 Pod 生命周期。
一次请求的完整流程
调用方向 POST /v2/nvcf/pexec/functions/{id} 发送请求,http-invocation 通过 ratelimiter gRPC 检查速率,请求发布到 NATS 流 Create.NVCA..{clusterID}..*,NVCA 队列管理器消费消息并创建 Kubernetes CR(通过 NATS sequence 去重),MiniService controller 调和并创建 Pod 或应用 Helm chart,函数 Pod 通过 WorkerService gRPC 回连,最后通过 Terminate.NVCA.{clusterID} 触发 Pod 删除和垃圾回收。
零扩缩容:NATS 缓冲方案
这是整个代码库中最重要的架构决策,与 Knative 处理零扩缩的方式有根本性差异。Knative 在长时间冷启动期间请求可能面临超时或重试压力,这对于需要将大模型加载到 VRAM(可能需要数十秒甚至数分钟)的 GPU 推理工作负载来说是致命的。NVCF 使用 NATS JetStream 作为持久请求缓冲:autoscaler 将目标实例数降为 0,没有 Pod 运行;新请求到达后发布到 NATS JetStream 并持久化;autoscaler 检测到队列深度大于 0,将目标实例数设为 1+;NVCA 接收创建消息并启动 Pod;Pod 通过 WorkerService gRPC 连接并拉取缓冲的消息;响应通过仍开放的 http-invocation 连接返回。请求永远不会被丢弃,调用方只是在冷启动时等待更长时间。
这个设计对比 Knative 的优势是:NVCF 在扩容期间请求被缓冲、零丢弃,而 Knative 会失败或超时;NVCF 通过每集群的持久消费者实现多集群路由,而 Knative 仅支持单集群。
本地搭建:无需 NGC 访问也能玩
你可以引导集群并使用假 GPU 层,无需 NGC 凭证。只有 NVCF 服务部署才需要 nvcf-onprem 组织访问。fake-gpu-operator 来自 run-ai/fake-gpu-operator,它向真实 Kubernetes 节点添加 nvidia.com/gpu 扩展资源,Pod 可以调度和运行,CUDA 调用会失败(因为没有真实 GPU),但所有 NVCF 编排、NATS 分发和零扩缩逻辑都与生产环境完全一致。
开源意味着什么
最大的改变是透明性。企业现在可以直接从源码验证 NVIDIA 的架构决策,而不是将平台视为黑盒。定制化方面,你可以修改 autoscaler Rust 循环、添加 NATS 认证策略、扩展 MiniService controller 或构建新的 CLI 命令。在此之前,这些内部机制在 NVIDIA 管理环境之外基本上是无法访问的。
参考来源
https://blog.kubesimplify.com/nvcf-is-now-open-source-inside-nvidia-s-gpu-function-platform
https://github.com/nvidia/nvcf
