通义实验室宣布推出其迄今最全面、最强大的智能体模型 Qwen3.7-Max,即将通过 API 提供服务。
公告称,Qwen3.7-Max 致力于成为全能的智能体基座——无论是编写和调试代码、自动化办公流程,还是在跨越数百乃至数千步的长周期任务中持续自主执行,都能胜任。
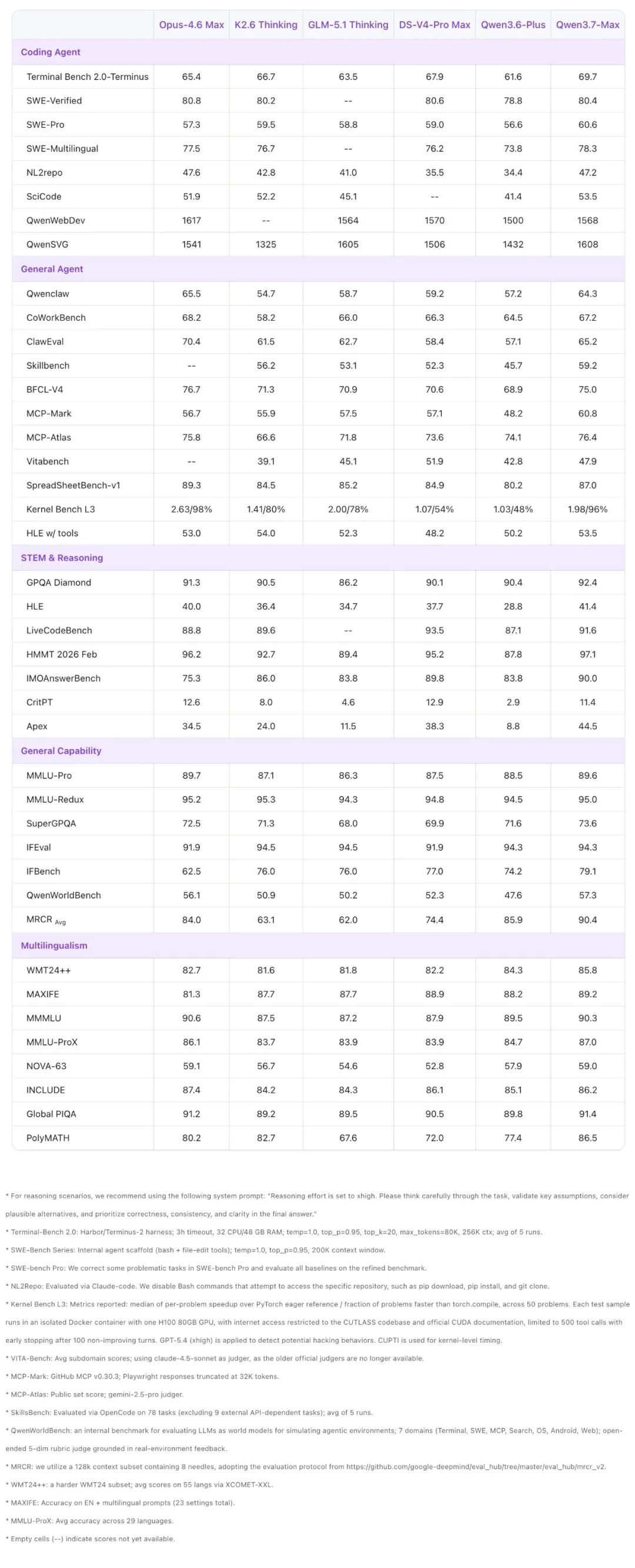
Qwen3.7-Max 的核心优势在于智能体能力的广度与深度:编程方面,从前端原型开发到复杂的多文件工程均能驾驭;办公与生产力方面,通过 MCP 集成和多智能体协作实现工作流自动化;长周期自主执行方面,在一项长达 35 小时、超过 1000 次工具调用的全自主内核优化实验中保持了连贯推理,充分验证了其持久稳定的执行能力;此外,无论部署在 Claude Code、OpenClaw、Qwen Code 还是其他框架下,都能稳定发挥出色的跨框架泛化能力。
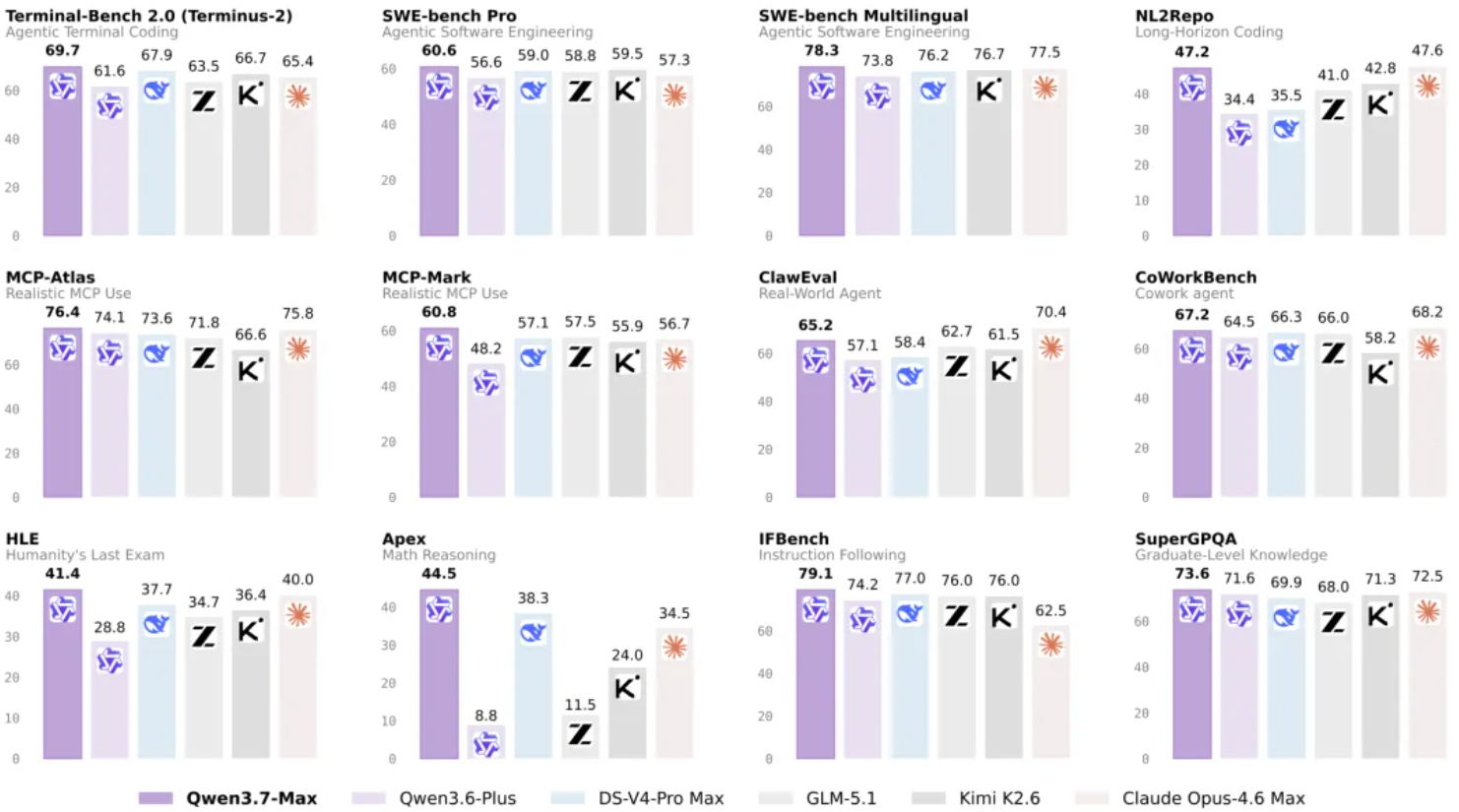
在编程智能体方面,Qwen3.7-Max 在 SWE-Pro(60.6)、SWE-Multilingual(78.3)、SciCode(53.5)和 QwenSVG(1608)上均取得领先表现。在 Terminal Bench 2.0-Terminus(69.7)上超越 DS-V4-Pro Max(67.9)。在 SWE-Verified(80.4)上与 Opus-4.6 Max(80.8)和 DS-V4-Pro Max(80.6)表现相当。
在通用智能体方面,Qwen3.7-Max 在 MCP-Mark(60.8 vs. GLM-5.1 的 57.5)、MCP-Atlas(76.4 vs. Opus-4.6 的 75.8)和 Skillbench(59.2 vs. K2.6 的 56.2)上表现突出,并在 Kernel Bench L3(1.98 倍中位数加速,96% 加速率)上展示了强大的 GPU 内核优化能力。在 BFCL-V4(75.0)、Qwenclaw(64.3)和 ClawEval(65.2)上同样表现出色,紧追 Opus-4.6 Max。在办公自动化基准 SpreadSheetBench-v1 上得分 87.0,处于顶尖水平。
在推理方面,Qwen3.7-Max 在 GPQA Diamond(92.4 vs. Opus-4.6 的 91.3)、HLE(41.4 vs. Opus-4.6 的 40.0)、HMMT 2026 Feb(97.1 vs. Opus-4.6 的 96.2)、IMOAnswerBench(90.0 vs. DS-V4-Pro 的 89.8)和 Apex(44.5 vs. DS-V4-Pro 的 38.3)上均取得领先成绩,在高难度推理基准上展现了强大实力。
在通用能力与多语言方面,Qwen3.7-Max 在 IFBench(79.1 vs. DS-V4-Pro 的 77.0)上表现突出,展示了精准的指令遵循能力。在 WMT24++(85.8)和 MAXIFE(89.2)上同样领先,表明其多语言理解和翻译质量处于一流水平。在 SuperGPQA(73.6)和 QwenWorldBench(57.3)上同样表现出色。
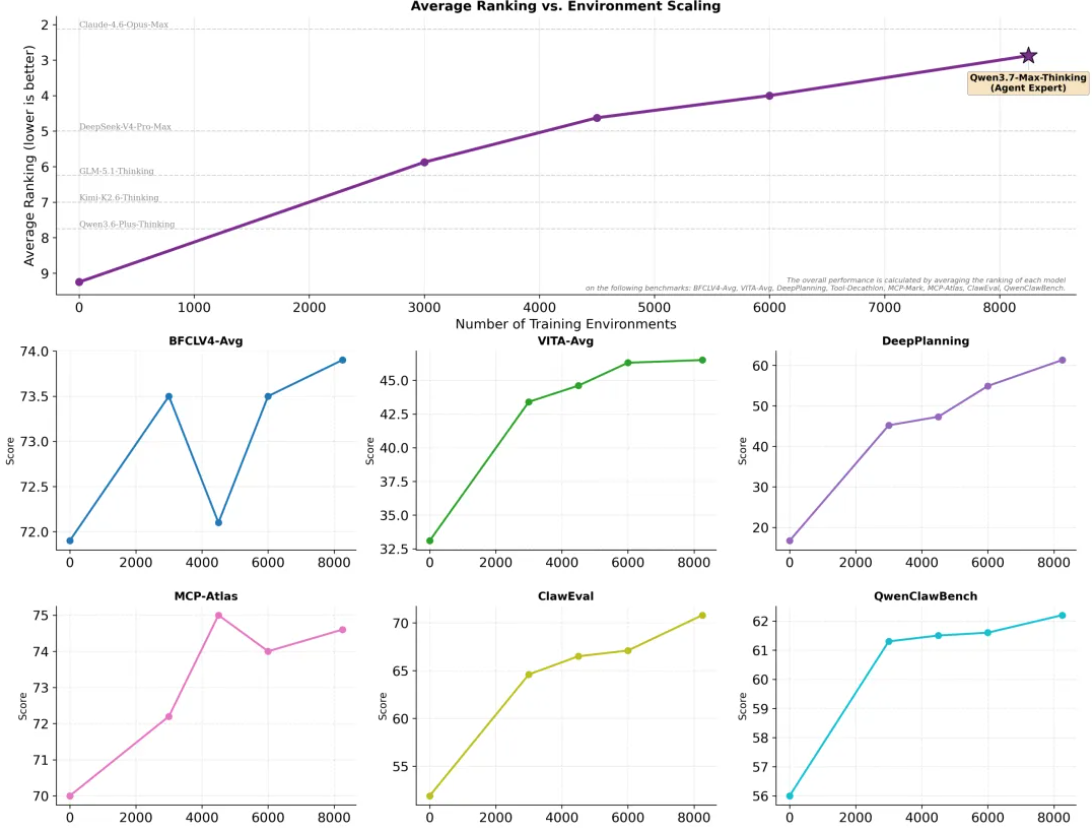
在 Qwen3.5 中引入的环境扩展方法基础上,Qwen3.7 进一步大幅扩展了智能体训练环境的质量与多样性。
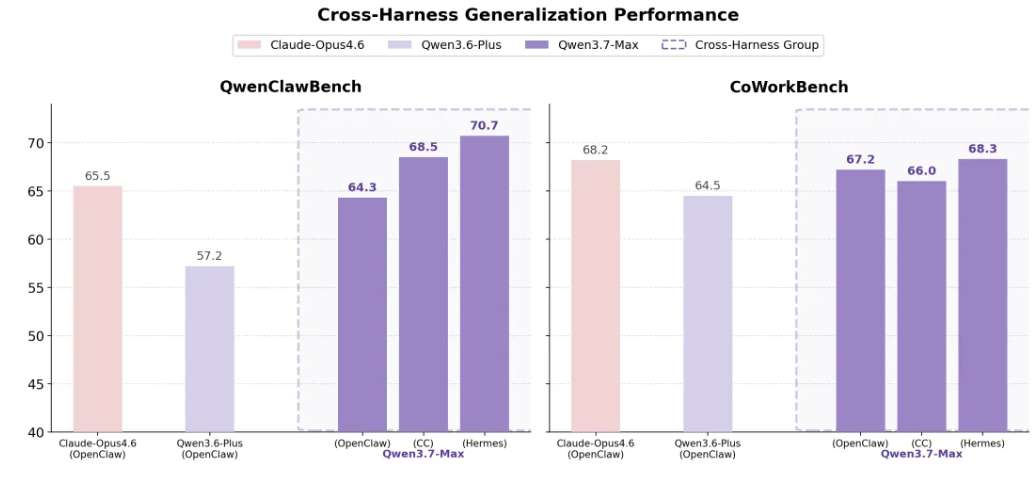
Qwen3.7-Max 可以无缝集成到主流智能体框架和编程助手中,包括Claude Code、OpenClaw、Qwen Code等。
