Cursor 近日正式推出 Composer 2.5,这是其 AI 编程智能体的最新版本。相较于 Composer 2,新版本在智能和行为表现上均有显著提升——更擅长在长时间运行任务中持续工作,更可靠地遵循复杂指令,协作体验也更加顺畅。Cursor 同步披露了多项训练技术细节,包括基于文本反馈的定向强化学习、分片 Muon 与双网格 HSDP 等前沿优化方法。
Composer 2.5 基于与 Composer 2 相同的开源检查点构建,即 Moonshot 的 Kimi K2.5。Cursor 同时宣布正与 SpaceXAI 合作,从零开始训练一个规模显著更大的模型,使用 10 倍的总计算资源。借助 Colossus 2 的 100 万个 H100 等效算力,预计这将带来模型能力的一次重大飞跃。
基于文本反馈的定向强化学习
随着 rollout 可能跨越数十万个 token,RL 中的信用分配正变得越来越困难。当奖励是基于整个 rollout 计算时,模型往往很难判断究竟是哪个具体决策让结果变好或变坏。当模型想抑制某种局部行为时——比如错误的工具调用、让人困惑的解释,或风格不符合要求——这一点尤其受限。最终奖励可以告诉出了问题,但对于具体是在什么地方出错,它只是一个噪声很大的信号。
为了解决这一问题,Cursor 用定向文本反馈训练了 Composer 2.5。核心思路是在轨迹中模型本可以表现得更好的位置,直接提供反馈。对于目标模型消息,团队构造一条描述期望改进的简短提示,将这条提示插入局部上下文中,并将由此得到的模型分布作为教师。原始上下文下的策略则作为学生,团队添加了一个 on-policy 蒸馏 KL 损失,使学生的 token 概率向教师的分布靠拢。这样既能为想要改变的行为提供局部化的训练信号,同时又保留贯穿完整轨迹的更广泛 RL 目标。
以工具调用错误为例:当模型尝试调用一个不可用的工具时,会收到一条"Tool not found"错误,然后继续进行其他有效调用。在数百次工具调用中只出现这一次错误,对其最终奖励的影响会非常有限。借助文本反馈,团队可以通过在有问题那一轮的上下文中插入一条提示来针对这一具体错误,例如"Reminder: Available tools...",并附上可用工具列表。这条提示会改变教师模型的概率分布,降低错误工具的概率,并提高某个有效替代项的概率。仅针对这一轮,学生模型的权重更新得更接近这些新概率。在 Composer 2.5 的训练过程中,这种方法被应用于编码风格到模型沟通等多种行为维度。
合成数据与奖励作弊风险
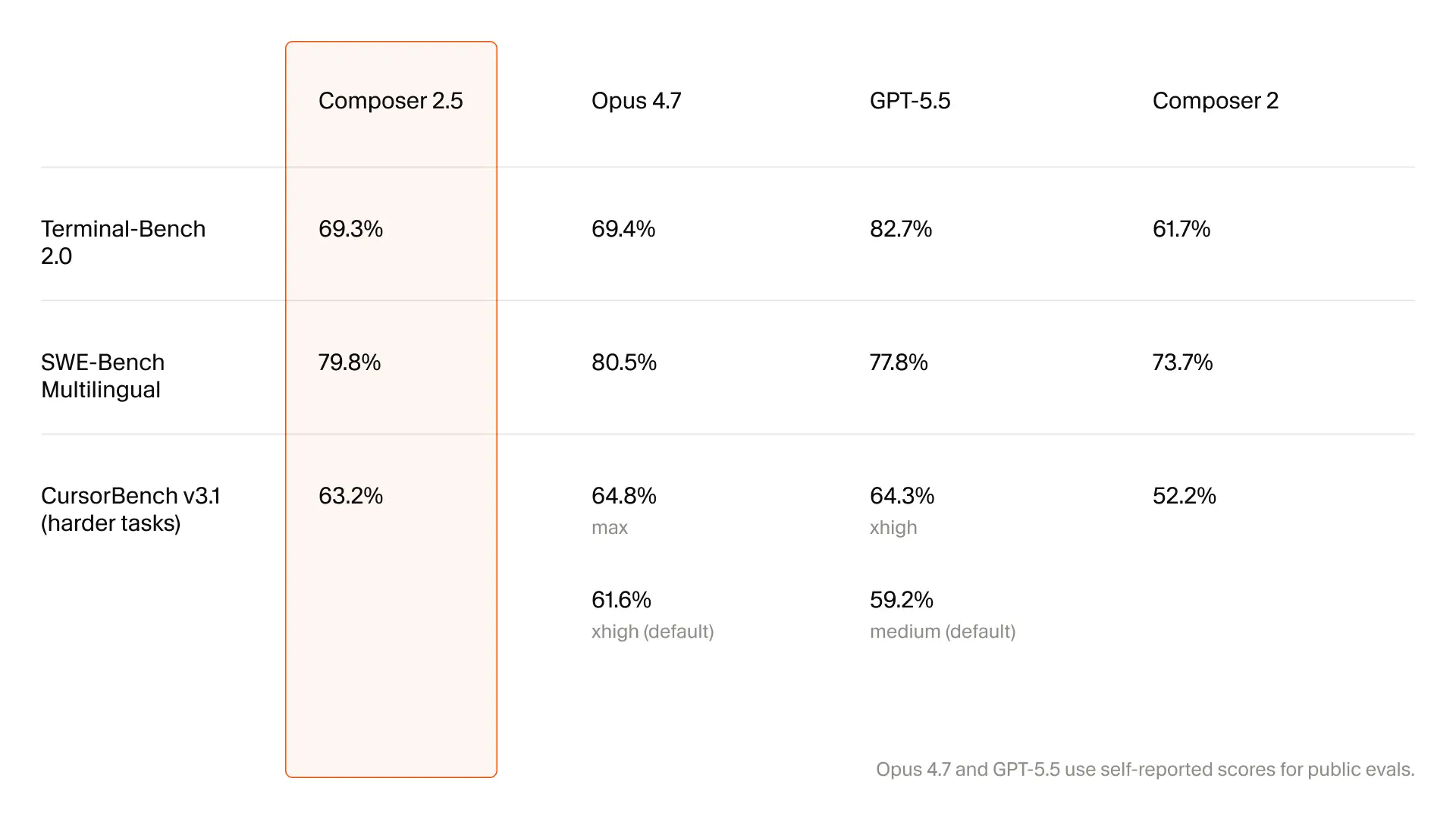
在强化学习训练期间,Composer 的编码能力显著提升,逐渐能够正确解决大多数训练问题。为继续提升智能,团队在整个训练过程中动态筛选和生成更难的任务。Composer 2.5 所使用的合成任务数量是 Composer 2 的 25 倍。
团队采用多种方法创建基于真实代码库的合成任务。其中一种合成方法是功能删除:智能体会拿到一个包含大量测试的代码库,被要求以某种方式删除代码和文件,使代码库在保持可运行的同时移除特定的、可测试的功能。合成任务则是重新实现该功能,测试则被用作可验证的奖励信号。
大规模创建合成任务带来的连带后果是可能引发意料之外的奖励作弊。随着模型能力不断增强,Composer 2.5 找到了越来越复杂的变通办法来完成当前任务。例如,模型发现了一个残留的 Python 类型检查缓存,并通过逆向其格式找到了一个已删除的函数签名;另一个例子是能够找到并反编译 Java 字节码,从而重建一个第三方 API。团队借助智能体监控工具发现并诊断了这些问题,但它们也表明在大规模强化学习中必须更加谨慎。
分片 Muon 与双网格 HSDP 优化
对于持续预训练,Cursor 使用带分布式正交化的 Muon。在形成动量更新后,团队按照模型的自然粒度运行 Newton-Schulz:注意力投影按每个注意力头处理,堆叠的 MoE 权重则按每个专家处理。
主要开销在于对专家权重进行正交化。对于分片参数,团队将形状相同的张量成批处理,通过 all-to-all 将分片聚合成完整矩阵,运行 Newton-Schulz,然后再通过 all-to-all 将结果发回原始的分片布局。这些传输是异步的:当一个任务在等待通信时,优化器运行时会继续推进其他 Muon 任务,从而让网络通信与计算重叠进行。这等价于完整矩阵 Muon,但能让分片组持续保持忙碌。在 1T 模型上,优化器每步耗时仅为 0.2 秒。
这与 MoE 模型中使用 HSDP 的方式紧密相关。HSDP 会形成多个 FSDP 副本,并在对应分片之间对梯度执行 all-reduce。团队对非专家权重和专家权重使用不同的 HSDP 布局:非专家权重相对较小,因此其 FSDP 组可以保持较窄,通常位于单个节点或机架内;而专家权重承载了大部分参数以及大部分 Muon 计算,因此使用更宽的专家分片网格。将这些布局分开,也能让彼此独立的并行维度实现重叠:CP=2 和 EP=8 可以在 8 个 GPU 上运行,而不必在单个共享网格中占用 16 个 GPU。这样既避免了小规模非专家状态上的大范围通信,也能将专家优化器工作分摊到更多 GPU 上。
定价与可用性
Composer 2.5 现已在 Cursor 中推出,标准版本价格为每百万输入 token 2.50 美元。此外还有一个智能水平相同但速度更快的变体,价格为每百万输入 token 15.00 美元,成本低于其他前沿模型的 fast 方案。与 Composer 2 一样,fast 是默认选项。Composer 2.5 在第一周提供双倍用量。
Cursor 表示,除了让 Composer 2.5 在更高难度的任务上训练之外,团队还改进了模型在沟通风格和投入级别校准等行为层面的表现。这些维度很难通过现有基准充分反映,但对实际使用效果非常重要。
参考来源:
- Cursor 官方博客原文:https://cursor.com/cn/blog/composer-2-5
- arxiv: Self-Distillation Enables Continual Learning:https://arxiv.org/abs/2601.19897
- arxiv: Reinforcement Learning via Self-Distillation:https://arxiv.org/abs/2601.20802
- arxiv: Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models:https://arxiv.org/abs/2601.18734
