独立开发者 William Angel 近日发布了关于在 Apple Silicon M5 MacBook Pro 上进行本地 LLM 推理的成本分析文章。这篇文章以具体数字回答了一个许多人关心的问题:用自己的 MacBook 跑本地模型,到底比调用云端 API 贵多少?
先看电费。在北弗吉尼亚地区,电价约为每千瓦时 0.18 美元。M5 MacBook Pro 在满载推理时功耗约为 50-100 瓦。以 100 瓦、0.18 美元/千瓦时计算,每小时电费约为 0.018 美元,一天约 0.48 美元。电费本身并不贵——每千瓦时不到 2 美分。
然后是硬件折旧。一台 14 英寸 M5 Max MacBook Pro,配备 64GB 内存,目前售价 4299 美元。如果这台设备使用 3 年,每年的硬件折旧约为 1433 美元;使用 5 年则每年 860 美元;使用 10 年每年 430 美元。将折旧分摊到每小时(假设每天运行 8 小时):3 年约 0.16 美元/小时,5 年约 0.10 美元/小时,10 年约 0.05 美元/小时。电费在整个成本中只占很小一部分,硬件折旧才是大头。
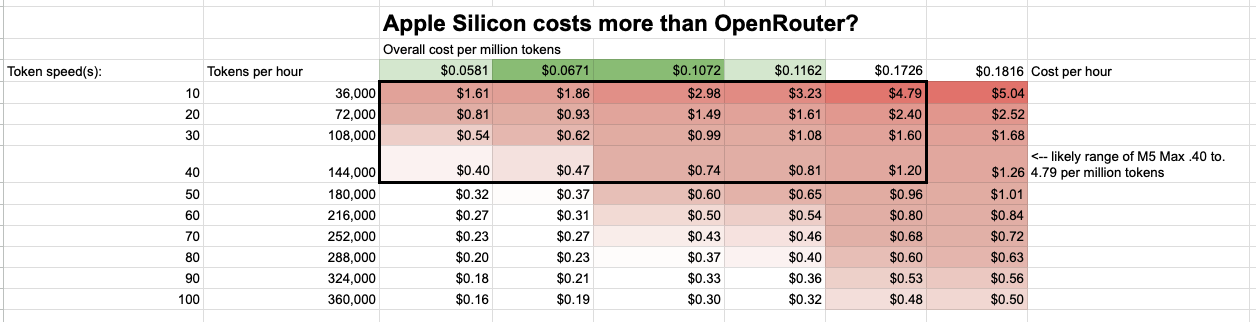
关键变量是 token 吞吐量。William 在 M5 Max 上测试了 Gemma 4 31b 等较大模型,实际推理速度在 10-40 tokens/秒 之间。以 10 tokens/秒计算,每小时可生成 36000 个 tokens;在 40 tokens/秒 时,每小时可生成 144000 个 tokens。将这些数字代入成本计算:以 5 年使用期、40 tokens/秒 的乐观估计,每百万 tokens 的成本约为 0.40-1.20 美元;以悲观估计(3 年使用期、10 tokens/秒),每百万 tokens 成本高达 1.61-4.79 美元。
相比之下,OpenRouter 上的 Gemma 4 31b 价格约为每百万 tokens 0.38-0.50 美元。这意味着在乐观情况下(设备使用 10 年、40 tokens/秒),本地推理和 OpenRouter 成本相当;但在悲观情况下(3 年使用期、10 tokens/秒),本地推理的成本是云端的约 10 倍。作者认为,对于典型使用场景,本地推理的成本大约是云端的 3 倍。
但成本只是一部分。速度差距同样显著。OpenRouter 上的部分 Gemma 4 提供商可以达到 60-70 tokens/秒,是 M5 Max 本地推理速度(10-20 tokens/秒)的 3-7 倍。对于一名有工资收入的员工来说,时间成本远大于 token 成本——花在等待本地推理的时间比省下来的 token 费用值钱得多。
作者最后指出了一个值得注意的事实:一台消费级设备能够运行接近 Anthropic Sonnet 性能水平的模型,这本身已经很不寻常了。即使成本是云端的 3 倍,本地推理提供了数据隐私、离线可用性和无速率限制等优势。对于需要处理敏感数据或在无网络环境工作的场景,这些价值可能超过成本差异。
来源:William Angel (https://www.williamangel.net/blog/2026/05/17/offline-llm-energy-use.html)
