向量数据库是 AI 应用时代的基础设施之一,但传统方案往往需要完整的向量数据库集群和专门的存储系统,部署和维护成本都不低。OpenData Vector 的出现提供了一个不同的思路:基于 SlateDB 构建在对象存储之上,直接利用对象存储的持久性和可扩展性,省去了独立向量存储系统的复杂性。
从核心架构看,OpenData Vector 是一个无状态的持久化向量搜索引擎。它使用 IVF 索引来组织向量,这种索引方式适合对象存储的延迟特性。更新策略上,它采用了基于 LSM 的 LIRE compaction 机制,对象存储天然支持追加写入,这个设计很自然。另一个特点是 share-everything 状态模型——任意节点都可以服务任意数据,查询请求可以路由到任何一个节点,不需要特定的协调者。
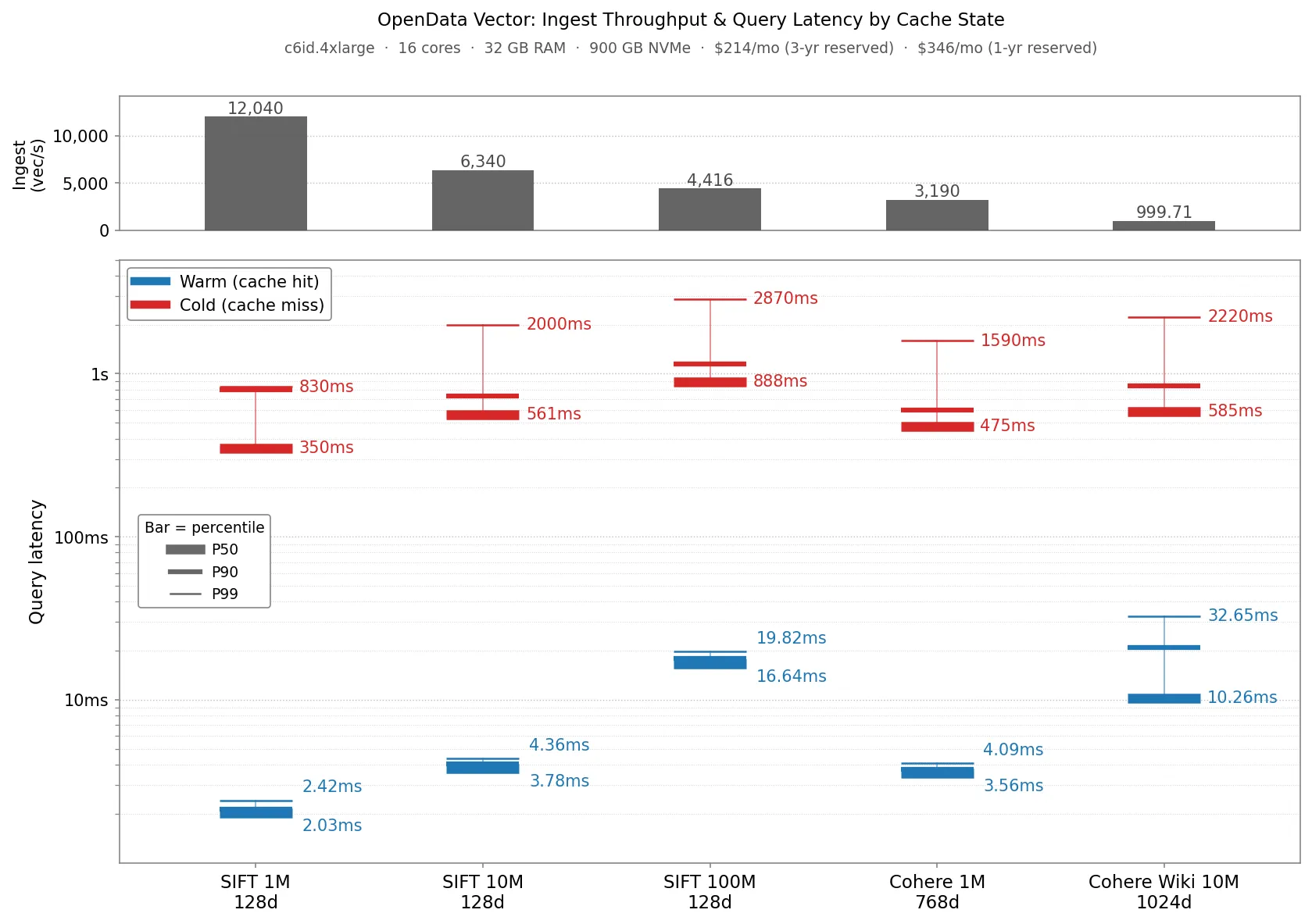
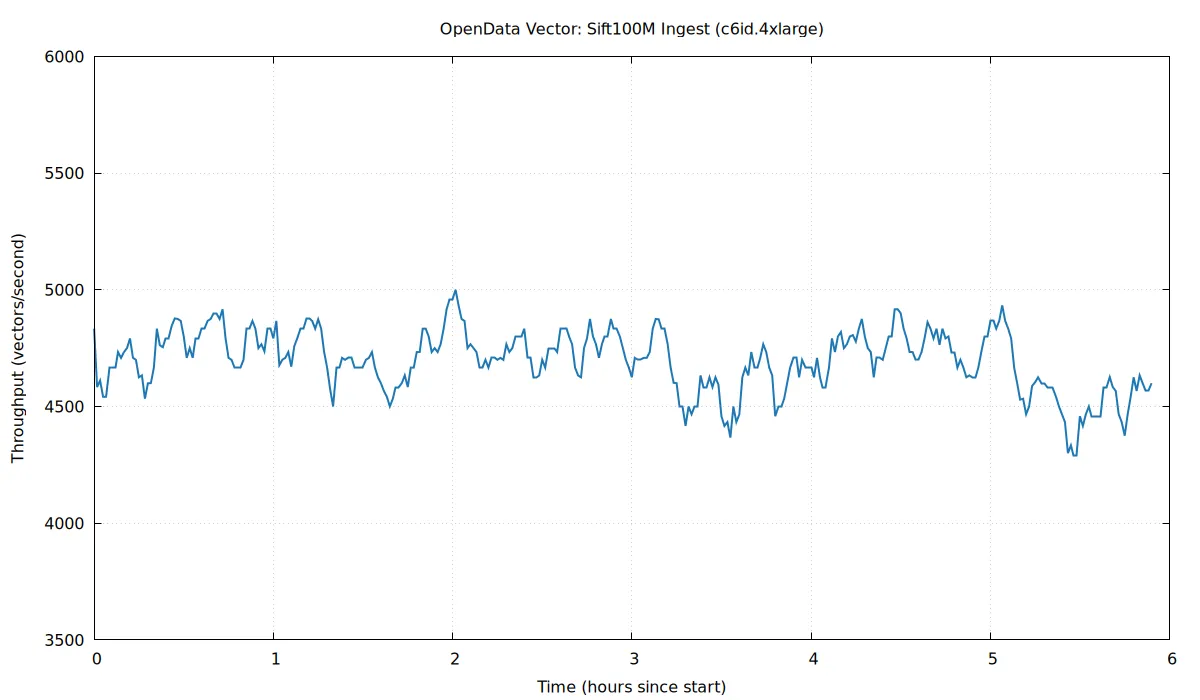
性能方面有几个关键数字值得关注:100M 向量规模下的月成本约 350 美元,对于中等规模的 AI 应用来说这个价格有竞争力。查询延迟方面,热点数据约 10ms,冷数据亚秒级,这个差异主要来自对象存储的特性。写入延迟约 1 秒确认,这个延迟水平对于非实时场景是可以接受的。
从部署模式看,OpenData Vector 支持从嵌入式到多节点拓扑的灵活扩展。嵌入式模式适合边缘设备或轻量级场景,多节点模式可以水平扩展应对更大规模数据。这个弹性让同一套代码可以适应不同规模的需求,不需要为不同场景维护不同的技术栈。
OpenData 团队列出了几个典型的应用场景:多模态内容的相似性检索、RAG 场景下的知识库召回、以及推荐系统中的向量匹配。这些都是当前 AI 应用中常见的需求场景。
OpenData Vector 采用 MIT 许可证,这意味着它可以免费商用,也为后续的技术演进和社区共建提供了法律基础。考虑到向量搜索在 AI 应用中的广泛需求,这个项目值得关注。
来源:OpenData (https://www.opendata.dev/blog/introducing-vector)
