4 月 28 日,NVIDIA 正式发布开源全模态推理模型 Nemotron 3 Nano Omni,将文本、图像、音频、视频、文档、图表乃至 GUI 界面等多种感知能力整合至单一系统,旨在解决传统 AI 智能体系统中多模型碎片化导致的延迟高、上下文断裂和成本攀升等痛点。

Nemotron 3 Nano Omni 采用 30B-A3B 混合专家(MoE)架构,总参数量约 300 亿,每次前向传播仅激活约 30 亿参数。该模型融合了 Mamba 层(提升长序列处理与内存效率)与 Transformer 层(保障推理精度),并集成 Conv3D、高效视频采样(EVS)等技术。其上下文窗口支持 256K 至 100 万 Token,能够处理超长文档与视频序列。
在性能方面,Nemotron 3 Nano Omni 在六项权威排行榜中名列前茅。相比同类开源全模态模型,其吞吐量最高提升 9.2 倍;在固定交互延迟下,视频推理的有效容量提升约 9.2 倍,多文档推理提升约 7.4 倍。得益于 Mamba 与 Transformer 的混合设计,内存与计算效率最高可提升 4 倍。在 MMlongbench-Doc、OCRBenchV2、WorldSense、DailyOmni、VoiceBench 等文档智能与音视频理解基准测试中,该模型均表现出色。
NVIDIA 此次将模型权重、训练数据集与训练配方完全开源,开发者可通过 Hugging Face、OpenRouter、build.nvidia.com 以及超过 25 个合作伙伴平台获取。模型同时以 NVIDIA NIM 微服务形式提供,支持从 NVIDIA Jetson、DGX Spark、DGX Station 等本地设备,到数据中心、云端及边缘环境的一致部署,便于企业在满足数据主权与合规要求的场景下落地。
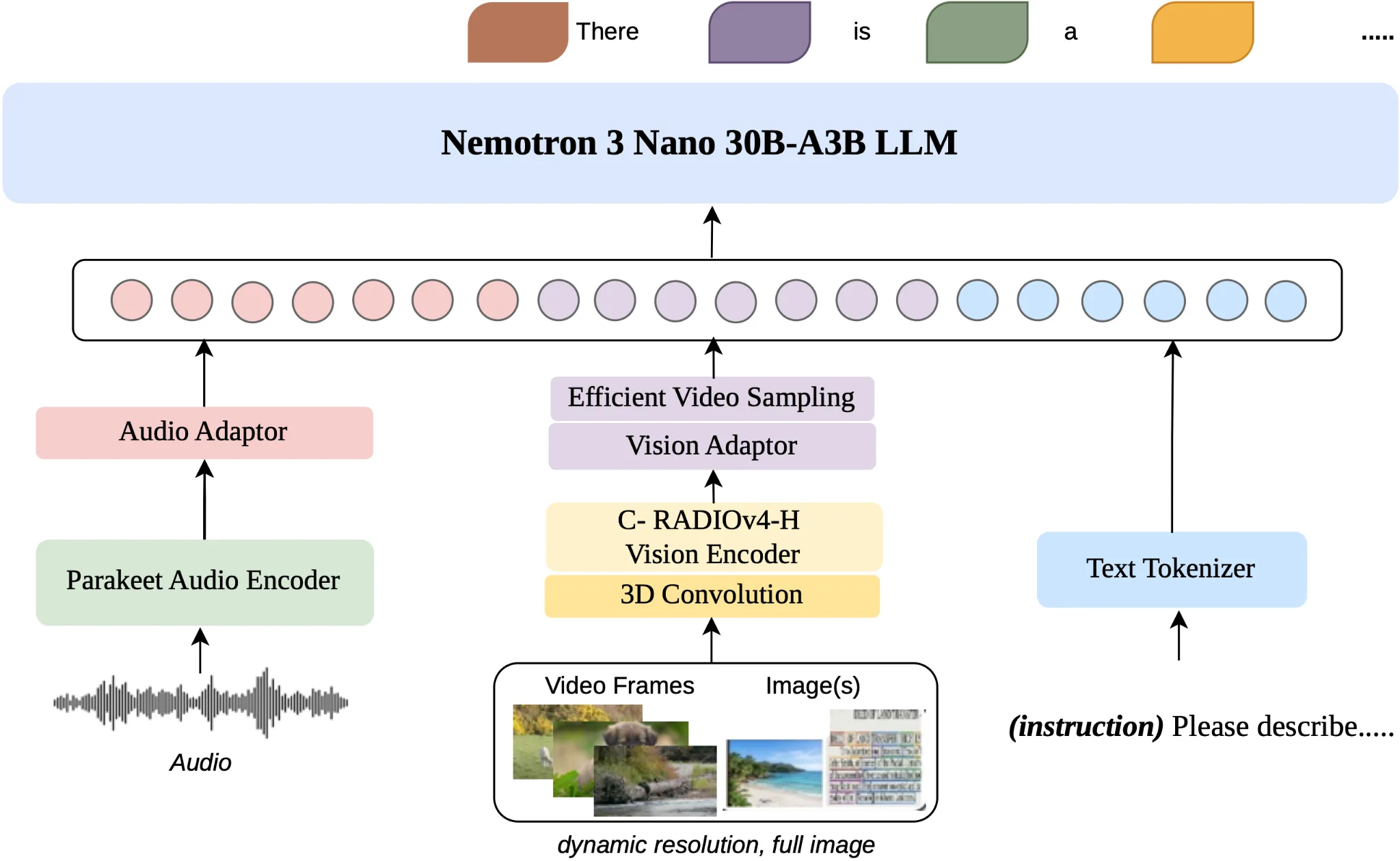
在应用层面,Nemotron 3 Nano Omni 主要面向三大场景:一是电脑操作(Computer Use),代理可在图形界面中导航、推理屏幕内容,H Company 基于此构建的代理已采用 1920×1080 原生分辨率实现高保真视觉推理;二是文档智能(Document Intelligence),可解读文档、图表、表格与混合媒体输入,在视觉结构与文字内容之间进行连贯推理;三是音视频理解,能够将说出的内容、显示的画面与记录的文件整合至单一推理流程。
目前,富士康、Palantir、Aible、H Company、Eka Care、Pyler 等企业已宣布采用该模型,戴尔科技、DocuSign、Infosys、Oracle、Zefr 等公司亦在评估中。Nemotron 3 系列在过去一年中累计下载量已超过 5000 万次,Nano Omni 的发布标志着该系列从纯文本正式拓展至全模态 Agent 领域。
参考来源:
