蚂蚁集团旗下的百灵大模型团队宣布,正式开源其面向复杂任务的万亿级综合旗舰模型 Ling-2.6-1T。
根据介绍,Ling-2.6-1T 并不是为了单纯追求更长的思考链,或制造更强的“参数规模体感”,而是面向真实复杂任务,系统性优化模型的智效比、指令执行、工具适配、长上下文承接和工程任务处理能力。
“我们希望它能够成为复杂工作流中的核心模型:既能理解复杂目标、拆解任务路径,也能在多样化 Agent harness、开发工具链和真实业务流程中稳定推进执行。”
具体而言,Ling-2.6-1T 重点解决三个问题:
- 第一,在更低 Token 开销下保持强综合智能。依托 MLA 与 Linear Attention 的 Hybrid 架构创新,结合抑制“过程冗余”的强化奖励策略,Ling-2.6-1T 在保持 1T 参数能力上限的同时,减少对冗长思考链的依赖,以更高效的“快思考”机制直达结果,从而压缩同等智能水平下的输出成本。
- 第二,在复杂任务中实现更可靠的多步执行。在 Agent、Coding 和工作流场景中,模型需要的不只是单点回答能力,而是对指令、工具、上下文和中间状态的持续把控,在噪声环境下的推理与精准作答。Ling-2.6-1T 加强对复合型任务的学习,在 AIME26、SWE-bench Verified、BFCL-V4 、TAU2-Bench、IFBench 等执行类基准上达到开源 SOTA 水平,展现出面向复杂任务的综合执行能力。
- 第三,让万亿级模型真正进入开发者和企业的生产工作流。Ling-2.6-1T 具备从代码生成到缺陷修复的完整工程落地能力,并与主流 Agent 框架高度兼容,适用于多工具、多步骤、多约束的复杂场景。它的目标不是停留在单次演示,而是成为真实业务系统中可部署、可协同、可持续运行的模型能力底座。
Ling-2.6-1T 在底层训练策略上实现了深度演进,以大幅提升 Token Efficiency 作为关键的优化维度:
- 高智效比优势突出:Artificial Analysis中,Ling-2.6-1T 以约 16M output tokens 达到约 34分 Intelligence Index,进入图中的高吸引力区间,说明它能够在相对克制的 token 消耗下,提供较强的综合智能表现。
- 综合智能已进入领先模型区间:相比 Ling 系列早期旗舰 Ling-1T,Ling-2.6-1T 在能力上实现了明显跃迁,并已展现出与 GPT-5.4(Non-Reasoning)同档的综合智能表现。
- 更适合真实部署的能力—效率平衡:相较部分依赖更高 token 消耗来换取更高分数的模型,Ling-2.6-1T 在效率与能力之间更均衡,更适合需要兼顾成本、吞吐与任务完成度的真实业务场景。
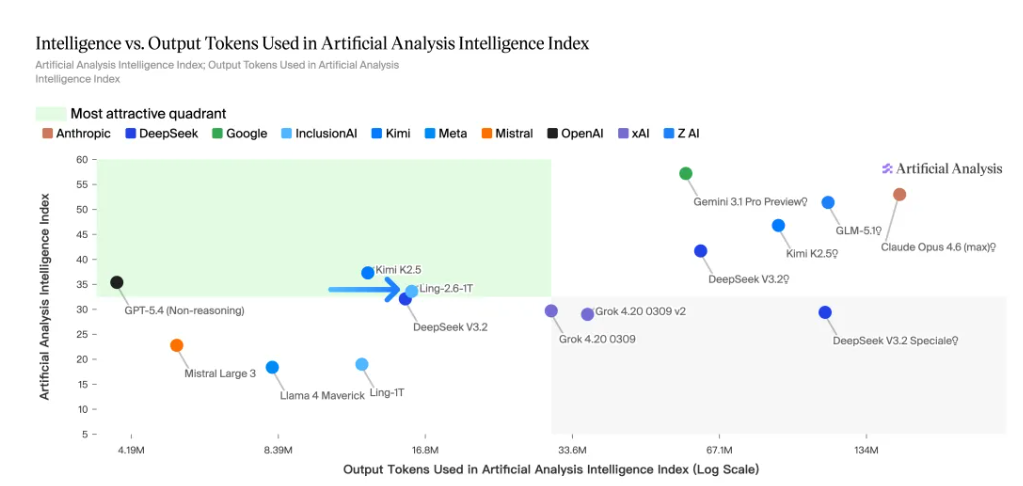
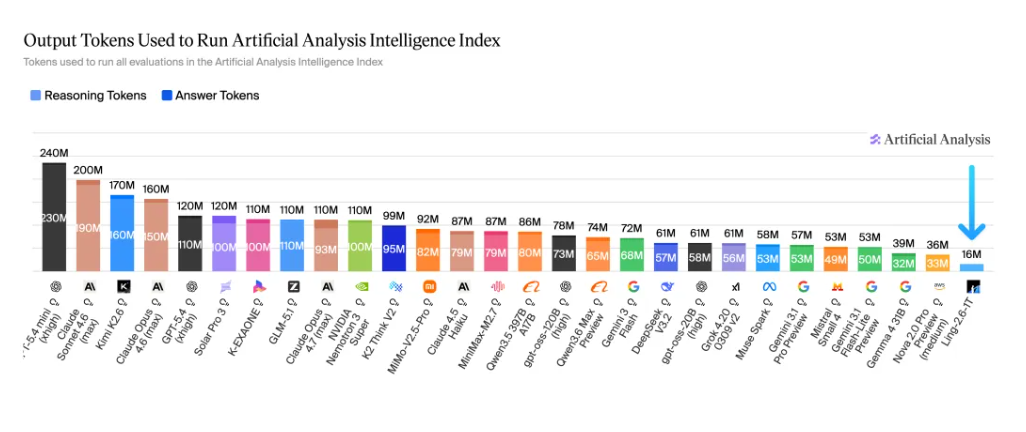
与此同时,Ling-2.6-1T 以仅 16M tokens 完成 Artificial Analysis 完整评测,在同类模型中展现出极突出的 Token Efficiency,体现出更低成本、更高吞吐与更强落地性的综合优势。
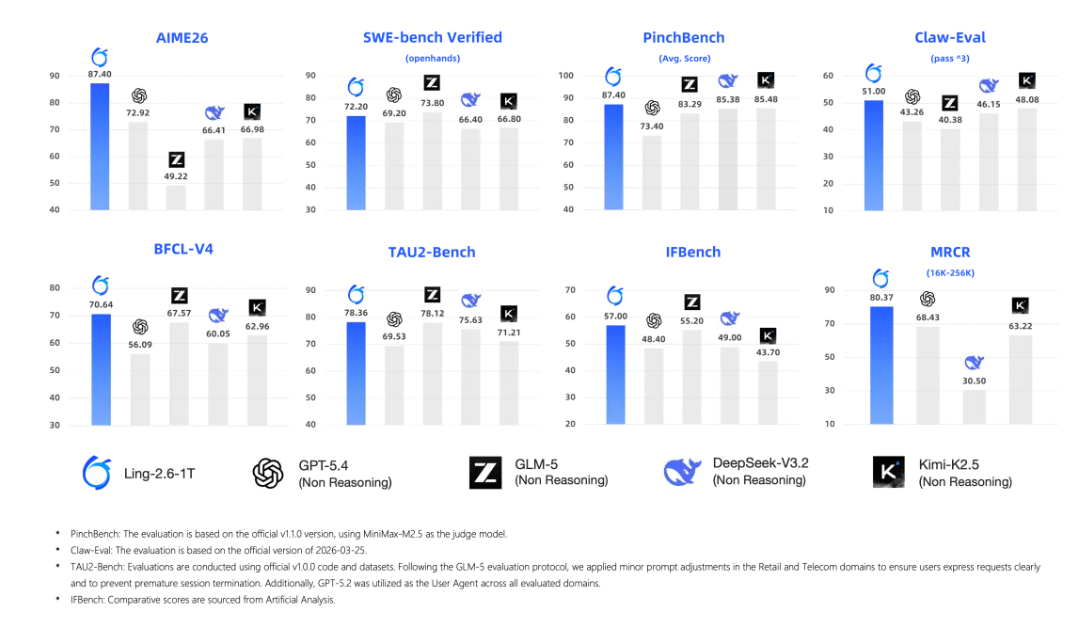
在推理、代码、工具调用、多步任务执行等维度,Ling-2.6-1T 展现出均衡的综合能力,对多样化的 Agent harness、工具链与工作流编排环境具备良好的适配性,在多个执行类 benchmark 上达到开源 SOTA 水平。
-
高难推理能力突出:在 AIME26 上,Ling-2.6-1T 显著领先于其他非思考模型,展现出更强的复杂问题分析与求解能力。
-
Agent 执行能力处于第一梯队:在 SWE-bench Verified、TAU2-Bench、Claw-Eval、BFCL-V4 和 PinchBench 上,Ling-2.6-1T 达到第一梯队,在工具调用、多步任务推进与真实工作流执行中均有不错的表现。
-
长上下文理解与优秀的指令遵循能力:在 MRCR(16K-256K)和 IFBench 均取得较高的分数,模型不仅具备更强的长文本理解能力,同时能够保证多重约束下的执行准确率与逻辑一致性。
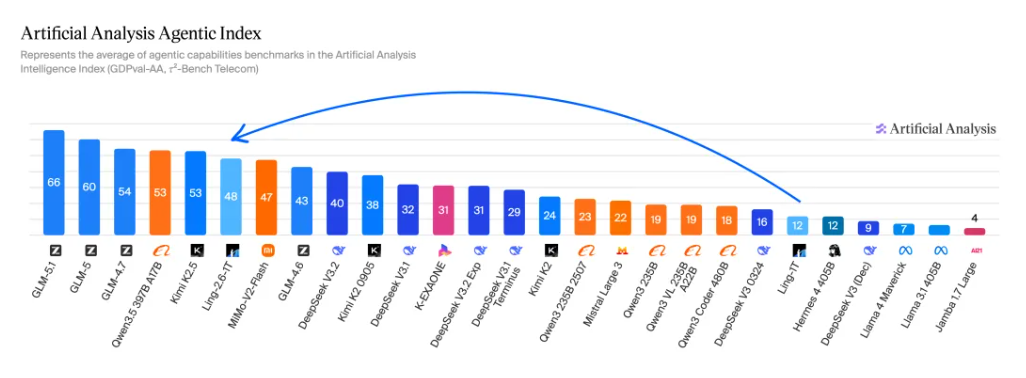
接下来,项目团队计划持续提升 Ling-2.6-1T 在知识密集型任务下的 Token 效率表现,追求更优的智能表现。同时,面对真实世界更严苛的交互需求,进一步优化 Agent 长程规划的全局一致性与复杂信息检索能力,并重点打磨复杂指令下的跨语言动态对齐,改善偶发的中英双语切换偏移现象。下一步,将继续拓宽模型性能边界,推动全场景复杂任务的交付效率与交互体验全面进化。
此外,为支持更多开发者体验与评测 Ling-2.6-1T,其还宣布将 OpenRouter 平台的免费 API 调用服务延期一周。
