在AI从"对话工具"迈向"生产代理"的转折点上,算力底座的开放程度正在成为生态竞争的关键变量。华为昇腾在近期的生态媒体沟通会上释放了明确信号:CANN(Compute Architecture for Neural Networks)全面开源开放,与Triton、PyTorch、vLLM等90多个主流开源社区深度对接,并对DeepSeek、Qwen等70+全球及国产主流大模型实现"发布即支持"的0day适配。
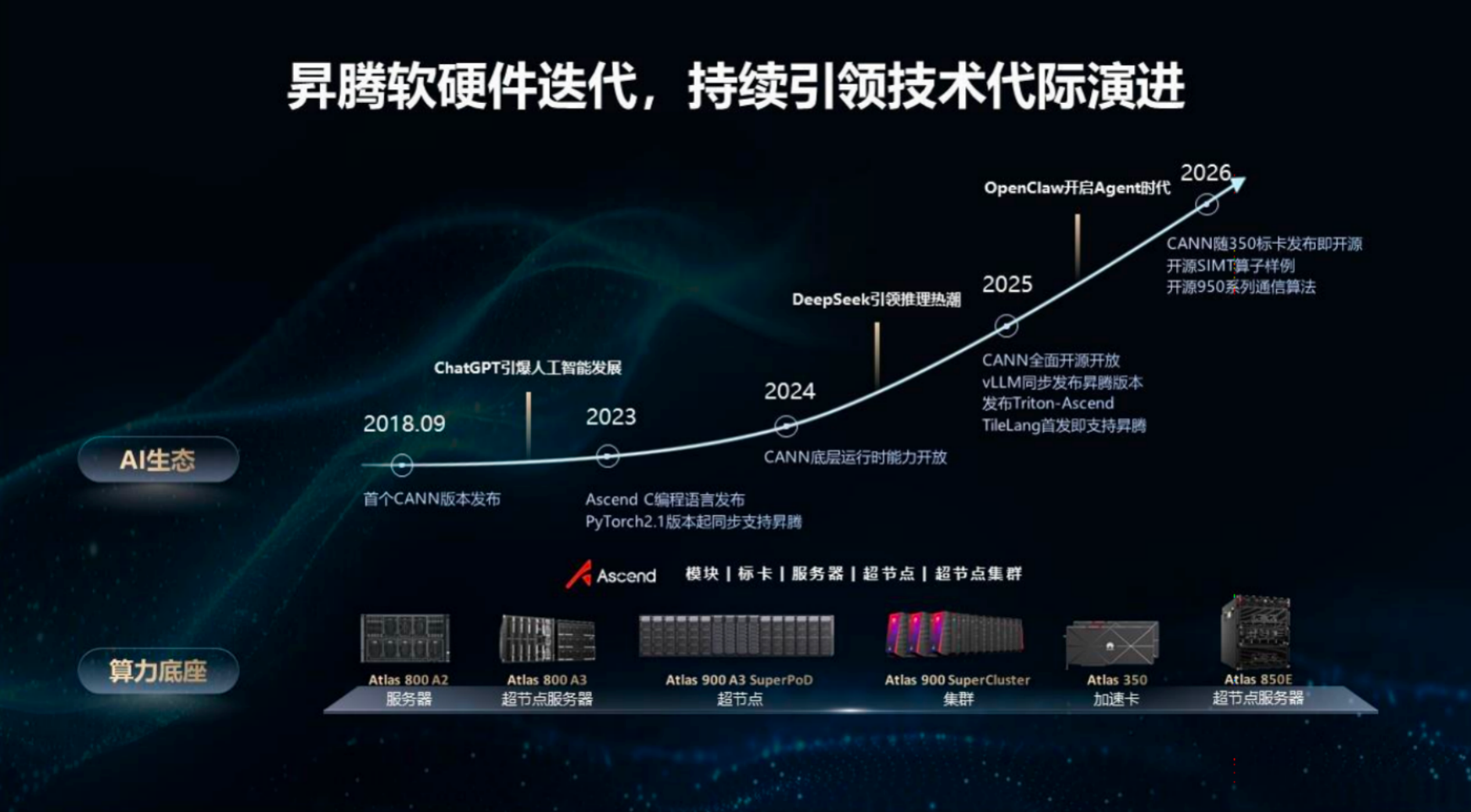
CANN开源升级,从"能用"到"好用"
昇腾此次强调的是"把底层做厚,把体验做轻"。技术层面,随950芯片发布的CANN在架构上做了几项实质性升级:
- 编程范式扩展:新增SIMT+SIMD混合编程模式,细化Cache Line粒度,算子编程语言体系新增 PyPTO(基于Python,与Triton编程习惯保持一致),兼容 Ascend C、Triton 等多种范式,同时全面支持 PyTorch 等主流开发框架。这意味着开发者不需要为了昇腾单独学习一套全新的开发语言。
- 精度格式支持:新增mxFP4/mxFP8低精度数据格式,直接面向大语言模型、多模态生成、搜索推荐等场景的推理需求。
- 工具链配套:从开发环境部署到训练推理实践,提供一站式开发平台,并配套完整的调试调优工具链。
简单来说,昇腾正在试图解决一个老问题:国产算力的软件生态门槛。
生态对接,不是"兼容",而是"同步迭代"
官方披露的一组数据值得关注:昇腾目前与90多个主流开源社区实现深度对接,并对70+主流大模型完成0day适配与全链路优化。
这里的"0day适配"是关键词。过去国产算力芯片常被诟病"模型发布了半个月才能跑通",而昇腾现在强调的是"发布即支持"——模型开源当天就能在昇腾上跑起来。这背后是昇腾将自身新功能、新特性持续回馈开源社区,与社区同步升级迭代的策略。
此外,昇腾已预置1500+基础算子、100+融合算子,覆盖大语言模型、多模态模型、搜索推荐模型等主流AI场景。对于开发者而言,这相当于"开箱即用"的底气。
Agent体系,算子开发从"手写"到"生成"
此次沟通会另一个值得关注的方向是昇腾的Agent体系。
昇腾推进 Agent Skills 开源及 Model Agent 建设。其中,昇腾算子专家 Agent 将算子开发从纯手写模式推进到自动生成模式——开发者只需描述设计意图,Agent 会自动配置环境并生成代码。这对于需要深入硬件细节、反复调试的算子开发工作来说,意味着门槛的大幅降低。同时,昇腾将调优优化工具和方法沉淀为开源 Skills,可被各类第三方 Agent 灵活调用,大幅降低模型部署门槛。
结合当前OpenClaw开源Agent框架的火爆来看,昇腾显然希望在AI Agent爆发的前夜,把自己嵌入到"从模型到应用"的全链路中。
4000卡算力+2000万基金,生态建设的真金白银
开源社区最怕"只喊口号不给资源"。昇腾这次给出了具体的数字:
- 全年4000卡算力资源:向社区免费开放,用于开发者体验、验证和持续集成。
- 2000万创新基金:用于激励全球伙伴参与昇腾生态共建。
- 行业SIG:联合企业、高校在化工、电力等传统行业推动专用算子与领域大模型适配,打造"样板间"式的落地案例。
算力战争的下半场是生态战争
从2018年首个CANN版本发布,到2023年Ascend C编程语言、PyTorch 2.1同步支持昇腾,再到2024年CANN底层运行时能力开放、2025年全面开源开放——昇腾的技术迭代曲线与AI产业的爆发周期基本重合。
当DeepSeek引领推理热潮、Token经营推动算力需求指数级爆发时,昇腾选择用"全面开源开放"来回应市场。这背后的逻辑很清晰:在AI基础设施层,封闭生态已经很难赢得开发者,而开发者的选择最终将决定算力底座的生死。
对于开发者来说,一个更开放的昇腾生态意味着多一个"不卡脖子"的选项。而对于整个AI产业来说,国产算力能否真正从"可用"走向"好用",2026年或许是一个关键的验证窗口。

我们从昇腾此次释放的信号可以概括为三个"全":全面开源、全社区对接、全模型适配。
但生态建设从来不是一蹴而就的——90个社区对接得是否深度、70个模型优化是否到位、4000卡算力能否持续供给,这些都需要开发者在实际使用中验证。至少从态度上看,昇腾已经摆出了"把地基打牢"的姿势。
