腾讯混元的全新 AIGC 视频生成加速方案--(Distillation-CompatibleLearnableFeatureCaching) DisCa 现已正式开源,其代码和模型权重公开可用。作为学界和业界首次对基于可学习的特征缓存技术进一步加速蒸馏后少步模型的这一方向的尝试,该工作现已被CVPR2026接收。
DisCa主要聚焦于两大方向的讨论:
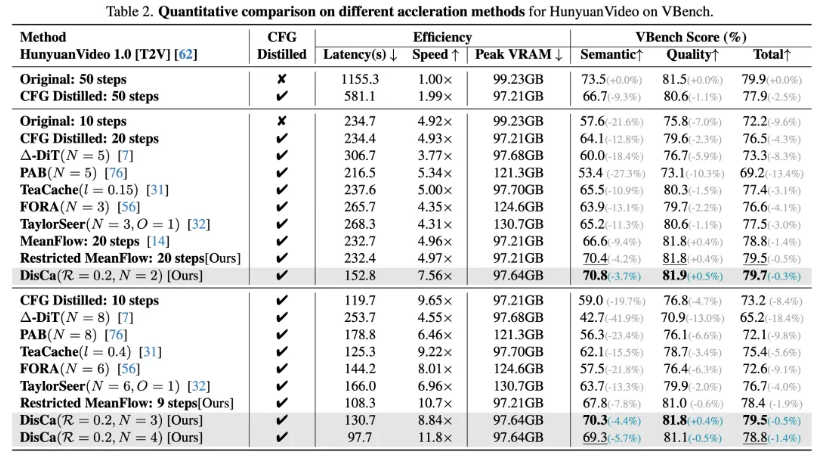
- DisCa首次提出在蒸馏后的少步模型上,通过引入可学习的轻量神经网络预测器,进一步利用特征缓存高度压缩推理成本,在保证质量前提下将加速边界拓展至11.8倍。
- MeanFlow蒸馏方案简单实用的进一步改进。这一点上与麻省理工(MIT),谷歌(Google)等团队同期工作的探索不谋而合,互相印证;相较之下,该工作在更复杂的高质量视频生成任务上开展,更具实践指导意义。
DisCa:蒸馏兼容的可学习缓存
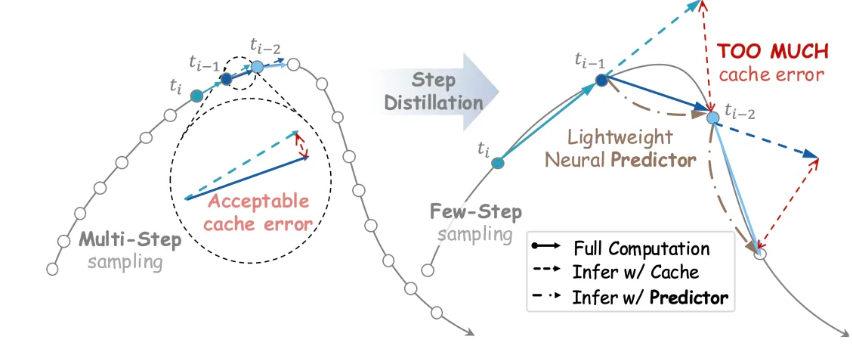
在扩散模型进行多步生成的过程(左)中,传统的特征缓存方案直接将以往特征缓存,然后在接下来推理步中直接复用,或简单地进行预测,就能达到不错的加速效果。但在已经进行少步蒸馏的模型(右)中,直接地运用特征缓存方案会导致过大的缓存误差,进而导致严重崩坏。
DisCa首次提出通过引入轻量神经网络预测器,通过神经网络以更好地捕获高维特征的演化轨迹,从利用以往推理步中的特征更精准地预测后续特征演化,实现推理加速。
基于生成-判别对抗的预测器训练
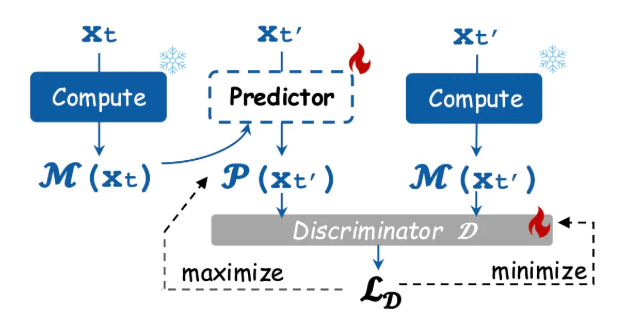
对于轻量级神经网络预测器Predictor(P),项目团队将上图所示的对抗学习方案引入其训练过程。
简单来说,在这个过程中,神经网络预测器P的目标是使其生成结果尽量接近同输入下,大模型M的输出,而判别器D的目标则是精准分别出预测器P和大模型M的输出。通过神经网络预测器P和判别器D的交替学习进化的博弈过程,轻量神经网络预测器P能很好地习得如何基于缓存来预测接下来的特征。
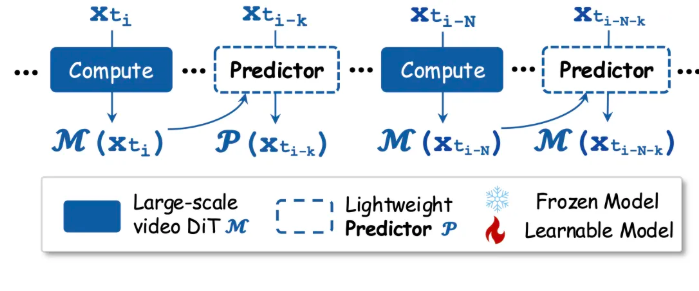
引入预测器后的推理模式
完成预测器训练后,主模型M和预测器P组装起来,按所示模式进行推理:
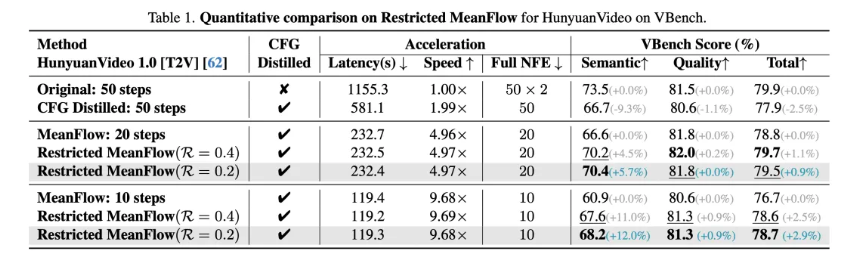
R-MeanFlow: 剪除激进场景的MeanFlow训练
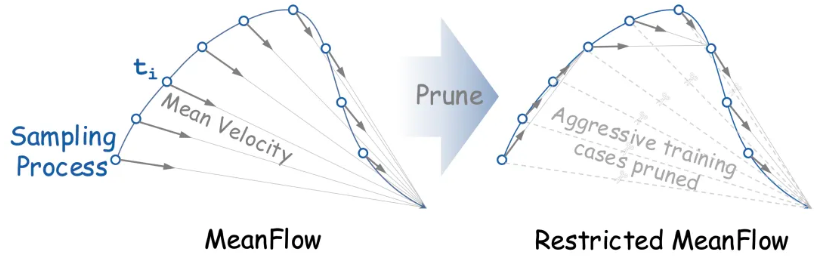
来自麻省理工的何恺明团队提出的MeanFlow,引入“预测平均速度场”的观点,在ImageNet图像生成任务的加速上取得了显著成功。而腾讯混元团队研究中注意到,在更复杂多样,要求更高的视频生成任务上,这样“一步生成”的目标过于激进,以“一步生成”为目标的激进训练样本,甚至会对模型训练产生明显的负面影响。
其相应的改进方案简单而实用:既然暂时不打算做“一步生成”,就剪除这些激进的训练场景,使得左图中本来模型每一步步长可能在0到1之间任取的训练,被约束为右图中步长受限在0到r(r<1)的RestrictedMeanFlow(R-MeanFlow)模式。这与麻省理工团队和谷歌团队的同期研究结论相互印证,并作为更复杂任务,更大规模的实践证据。相关研究成果也被用于当前最佳开源视频生成模型 HunyuanVideo-1.5的步数蒸馏实践中。
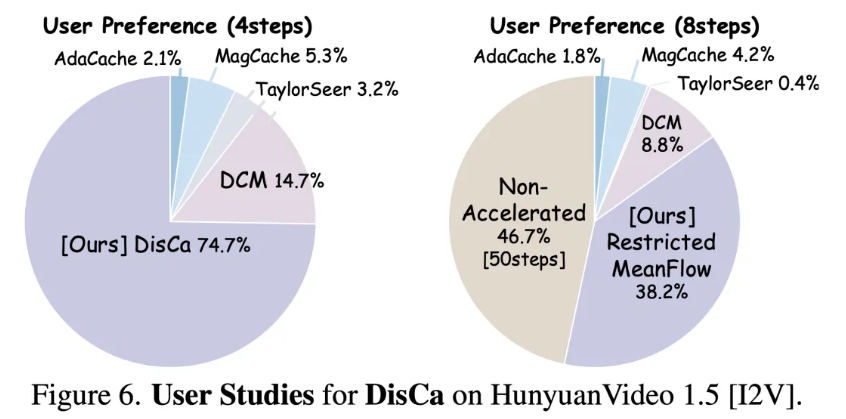
实验结果展示