谷歌宣布正式推出 Gemma 4 系列多模态模型,采用 Apache 2 许可,“这是我们迄今为止最智能的开放模型”。
官方文档介绍称,Gemma 是一系列先进的轻量级开放模型,其开发采用了与 Gemini 模型相同的研究成果和技术。 Gemma 由 Google DeepMind 和 Google 的其他团队共同开发,其名称源自拉丁语 gemma,意为“宝石”。
与 Gemma-3n 类似,Gemma 4 支持图像、文本和音频输入,并生成文本响应。文本解码器基于 Gemma 模型,并支持长上下文窗口。图像编码器与 Gemma 3 的编码器类似,但进行了两项关键改进:可变宽高比和可配置的图像 token 输入数量,以便用户在速度、内存和质量之间找到最佳平衡点。所有型号均支持图像(或视频)和文本输入,而小型版本(E2B 和 E4B)还支持音频输入。
Gemma 4 共包含四个版本:Gemma 4 E2B,有效 20 亿参数;Gemma 4 E4B,有效 40 亿参数;Gemma 4 31B 稠密模型以及 Gemma 4 26B 混合专家(MoE),激活参数 4B,总参数 26B。
| Model |
Parameter Size |
Context Window |
Checkpoints |
| Gemma 4 E2B |
2.3B effective, 5.1B with embeddings |
128k |
base, IT |
| Gemma 4 E4B |
4.5B effective, 8B with embeddings |
128k |
base, IT |
| Gemma 4 31B |
31B dense model |
256K |
base, IT |
| Gemma 4 26B A4B |
mixture-of-experts with 4B activated/26B total parameters |
256K |
base, IT |
Gemma 4 借鉴了此前 Gemma 版本和其他开源模型中使用的多个架构组件,并剔除了 Altup 等复杂或不确定的功能。这种组合旨在实现跨库和设备的高度兼容性,能够高效支持长上下文和代理用例,同时非常适合量化。
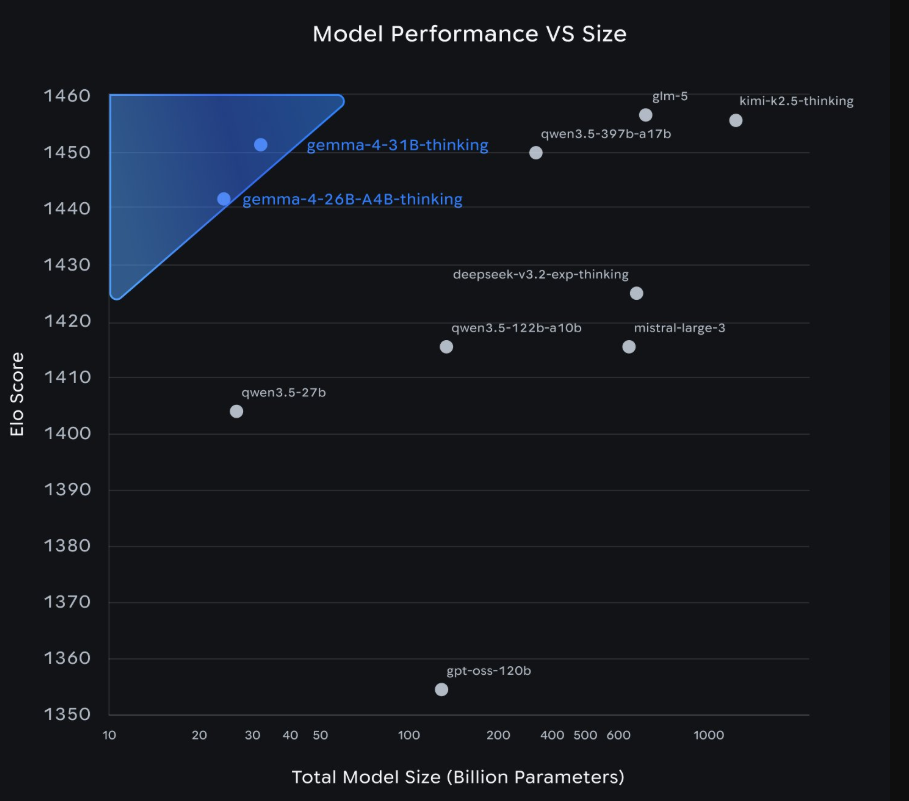
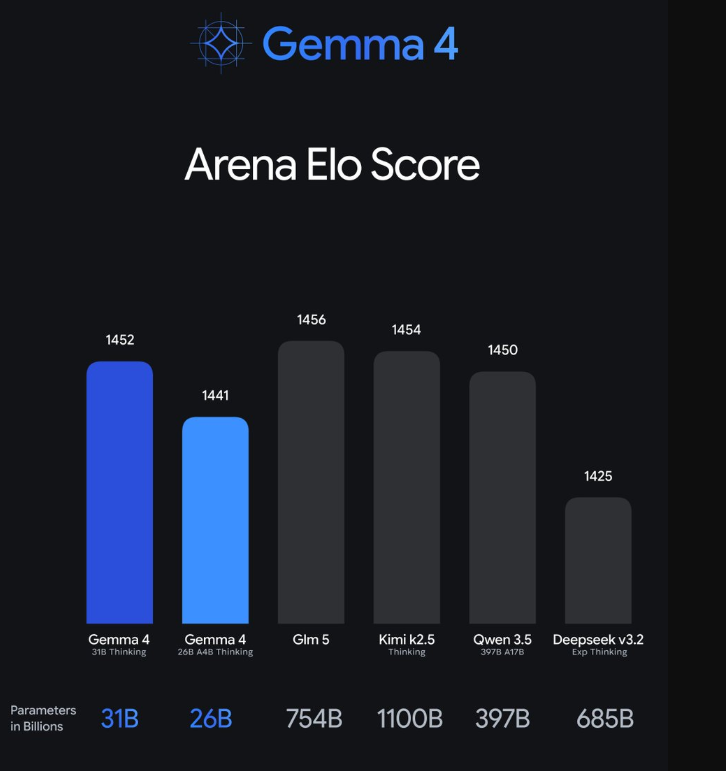
这一特征组合(结合训练数据和配方)使 310 亿参数的稠密模型实现了 1452 的 LMArena 估计分数(仅文本),而 260 亿参数的 MoE 模型仅凭 40 亿个活跃参数就达到了 1441 分。
31B 模型目前在行业标准的 Arena AI 文本排行榜上名列全球开放模型第 3 位,26B 模型则名列第 6 位。在榜单中,Gemma 4 的表现甚至超越了规模达其 20 倍的模型。
以下是 Gemma 4 的主要架构特点:
- 交替使用局部滑动窗口和全局全上下文注意力层。较小的稠密模型使用 512 个 token 的滑动窗口,而较大的模型使用 1024 个 token 的滑动窗口。
- Dual RoPE 配置:标准 RoPE 用于滑动层,比例 RoPE 用于全局层,以实现更长的上下文。
- Per-Layer Embeddings (PLE):一个额外的嵌入表,将一个小的残差信号输入到每个解码器层。
- 共享 KV 缓存:模型的最后 N 层重用来自前面层的键值状态,消除冗余的 KV 投影。
- Vision encoder:使用学习到的 2D 位置和多维 RoPE。保留原始宽高比,并且可以将图像编码为几种不同的 token budgets(70、140、280、560、1120)。
- Audio encoder:USM-style conformer,其基础架构与 Gemma-3n 中的架构相同。
基准测试结果
![]()
![]()
更多详情可查看官方公告。